大模型消耗的显存
在详细说明大模型需要消耗的显存大小之前我们需要先明确几个概念。 一个就是大模型在不同阶段对显存的消耗是不同的。但是大致可以分为三个阶段或者说三个场景。即大模型预训练阶段、大模型微调阶段和大模型推理阶段。 - 在预训练阶段,大模型通常选择较大规模的数据集获取泛化能力,因此需要较大的批次等来保证模型的训练强大。而模型的权重也是从头开始计算,因此通常也会选择高精度(如32位浮点数)进行训练。需要消耗大量的GPU显存资源。 - 在微调阶段,通常会冻结大部分参数,只训练小部分参数。同时,也会选择非常多的优化技术和较少的高质量数据集来提高微调效果,此时,由于模型已经在预训练阶段进行了大量的训练,微调时的数值误差对模型的影响通常较小。也常常选择16位精度或者混合精度训练。因此通常比预训练阶段消耗更低的显存资源。 - 在推理阶段,通常只是将一个输入数据经过模型的前向计算得到结果即可,因此需要最少的显存即可运行。
模型权重
这部分显存用于存储神经网络模型的参数,包括权重(weights)和偏置(biases)。模型内存是模型在训练和推理过程中都需要的,因为它包含了模型的结构和学习到的知识。在训练过程中,模型内存的大小通常与模型的复杂度和参数数量成正比。
梯度
在模型训练反向传播(Backward)过程中,计算的梯度所占的显存大小。梯度内存的大小与模型的参数数量有关,因为每个参数都需要计算对应的梯度。
优化器状态
优化器内存用于存储优化器状态,这通常包括梯度的一阶和二阶矩(如在Adam优化器中使用的均值和方差估计)优化器内存的大小取决于所使用的优化器类型。例如,Adam优化器需要额外的内存来存储梯度的一阶和二阶矩,而SGD只需要存储梯度信息,无其他优化器内存占用。
激活值
激活内存用于存储神经网络在前向传播过程中计算的中间激活值。这些激活值在反向传播过程中需要被重用,以计算关于模型参数的梯度。激活内存的大小与网络的深度和输入数据大小(batch size)有关。更深的网络和更大的 batch size 会导致更大的激活内存需求。
数据精度
想要计算显存,从“原子”层面来看,就需要知道我们的使用数据的精度,因为精度代表了数据存储的方式,决定了一个数据占多少bit。对于一个1B参数的模型,如果使用FP32精度存储,那么模型权重占用的显存就是1B * 2 = 2GB。
常见精度类型
浮点数主要是由符号位(sign)、指数位(exponent)和小数位(mantissa)三部分组成。
符号位都是1位(0表示正,1表示负),指数位影响浮点数范围,小数位影响精度。
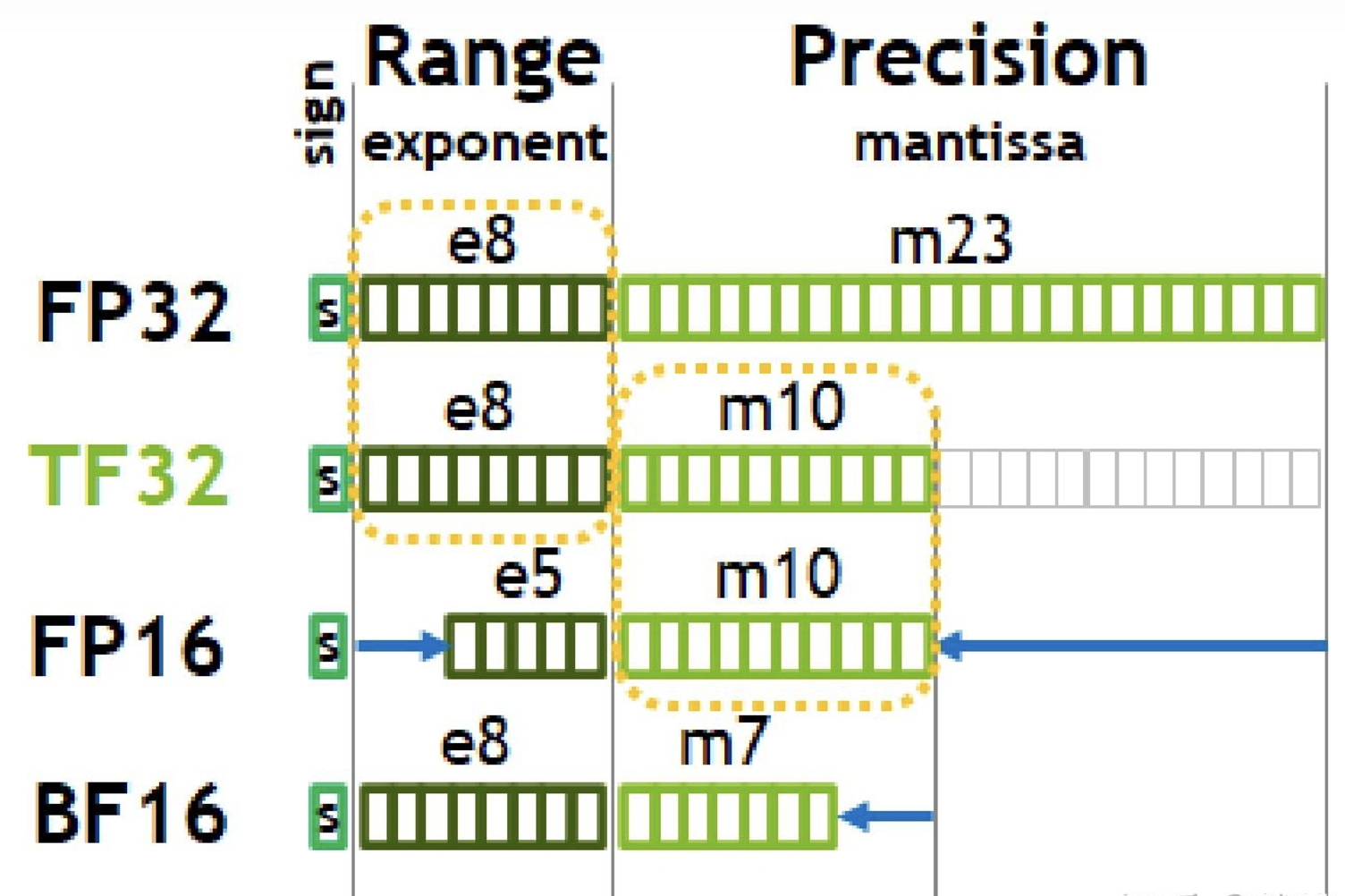 - FP32:32位浮点数,每个数据占4字节 -
TF32:19位浮点数,每个数据占2字节 -
FP16:16位浮点数,每个数据占2字节 - BF16:16位浮点数,每个数据占2字节 -
Int8:8位整数,每个数据占1字节 - Int4:4位整数,每个数据占0.5字节
- FP32:32位浮点数,每个数据占4字节 -
TF32:19位浮点数,每个数据占2字节 -
FP16:16位浮点数,每个数据占2字节 - BF16:16位浮点数,每个数据占2字节 -
Int8:8位整数,每个数据占1字节 - Int4:4位整数,每个数据占0.5字节
混合精度训练AMP
较低模型精度对于运算效率和显存占用都更友好,但是如果直接使用FP16精度在训练过程中会出现很多问题:
- underflow:梯度再乘以学习率会很小,无法用fp16表示 - rounding
error:fp16各个区间之间存在gap,即使梯度可以用fp16表示,但是也没有把法加在fp16的权重上(被舍去)
- 模型预测准确度降低 #### FP32权重备份:解决舍入误差问题
保留一份FP32的主权重(Master-Weights),同时在训练中使用FP16存储权重、激活、梯度等数据。在参数更新的过程汇总,用FP16更新FP32的主权重。
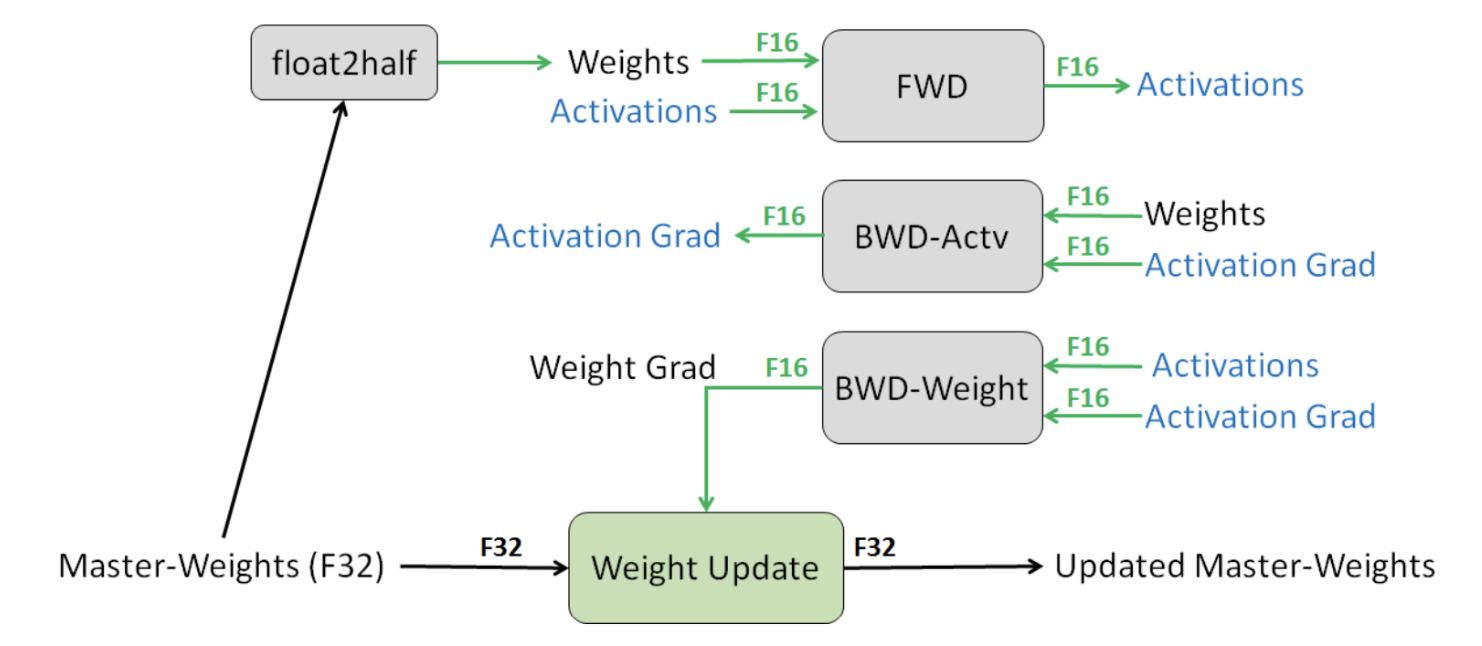
Step1:优化器会先备份一份FP32精度的模型权重,初始化好FP32精度的一阶和二阶动量(用于更新权重)。
Step2:开辟一块新的存储空间,将FP32精度的模型权重转换为FP16精度的模型权重。
Step3:运行forward和backward,产生的梯度和激活值都用FP16精度存储。
Step4:优化器利用FP16的梯度和FP32精度的一阶和二阶动量去更新备份的FP32的模型权重。
Step5:重复Step2到Step4训练,直到模型收敛。
我们可以看到训练过程中显存主要被用在四个模块上:
- 模型权重本身(FP32+FP16)
- 梯度(FP16)
- 优化器(FP32)
- 激活值(FP16)
写到这里,我们应该对于分析大模型训练时候的显存问题应该不在话下了(除了动态部分),那么我们就来实测一下,正在阅读的小伙伴也可以先自己尝试计算一下,看看是不是真的懂了。 对于llama3.1 8B模型,FP32和BF16混合精度训练,用的是AdamW优化器,请问模型训练时占用显存大概为多少?
解:
模型参数:16(BF16) + 32(PF32)= 48G
梯度参数:16(BF16)= 16G
优化器参数:32(PF32) + 32(PF32)= 64G
不考虑激活值的情况下,总显存大约占用 (48 + 16 + 64) = 128G
损失缩放:解决数据下溢问题
当采用FP16而不是FP32更新梯度时,由于值太小,会造成FP16精度下数据下溢的问题,一些梯度会变为0,导致模型不收敛。故采用在前向过程结束后对损失进行放大,在反向过程结束后对梯度进行缩小。 损失缩放可以有两种主要方式:静态损失缩放和动态损失缩放。 - 静态损失缩放:在训练开始前,设置一个固定的缩放因子,在训练过程中保持不变。 - 动态损失缩放:在训练过程中,根据损失值的大小动态调整缩放因子。 - 如果在某轮训练中检测到梯度正常且没有溢出,缩放因子会逐渐增大。 - 如果检测到梯度出现 NaN 或 Inf,则缩放因子减小以防止数值不稳定。
精度累加
此外,研究者还发现,可以在模型训练的过程中,使用FP16进行乘法预算,使用FP32进行累加运算,并将FP32转换为FP16存储。FP32可以弥补损失的精度,减少舍入误差。
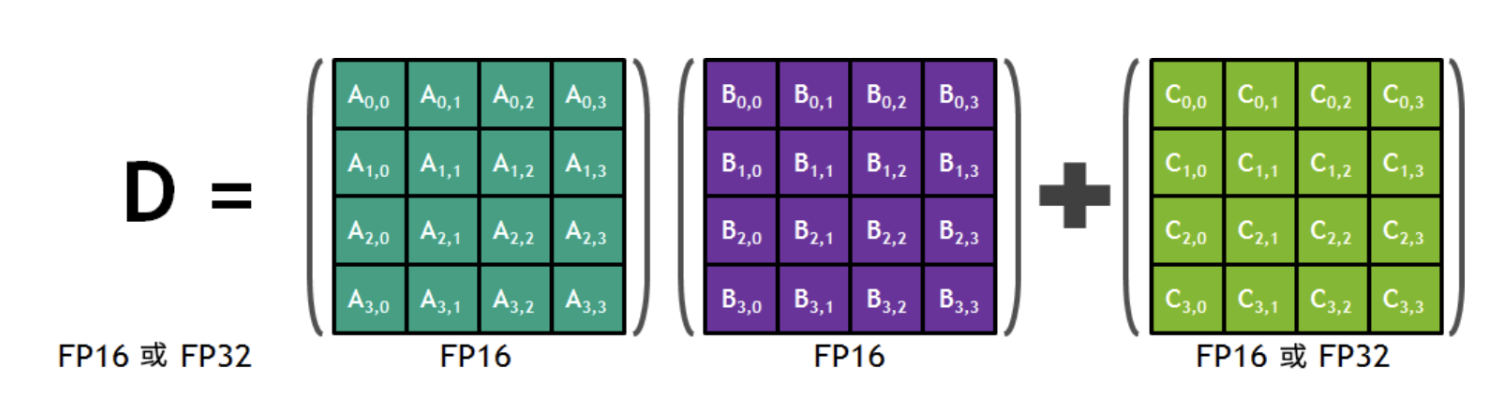 如英伟达Volta架构中的Tensor
Core可以使用FP16混合精度进行加速,采用的是FP16的矩阵乘法,得出全精度乘积,然后使用FP32累加,将该乘积与其他中间乘积累加,减少因FP16带来的精度损失。
如英伟达Volta架构中的Tensor
Core可以使用FP16混合精度进行加速,采用的是FP16的矩阵乘法,得出全精度乘积,然后使用FP32累加,将该乘积与其他中间乘积累加,减少因FP16带来的精度损失。
更为动态的精度缩放方法
在英伟达最新的Hopper架构GPU中,英伟达的Tensor
Core能够自动根据所需的精度进行动态的数据缩放调整,特别是针对Transformer网络架构,能够在数据存入内存前,根据需求改变各种参数精度。
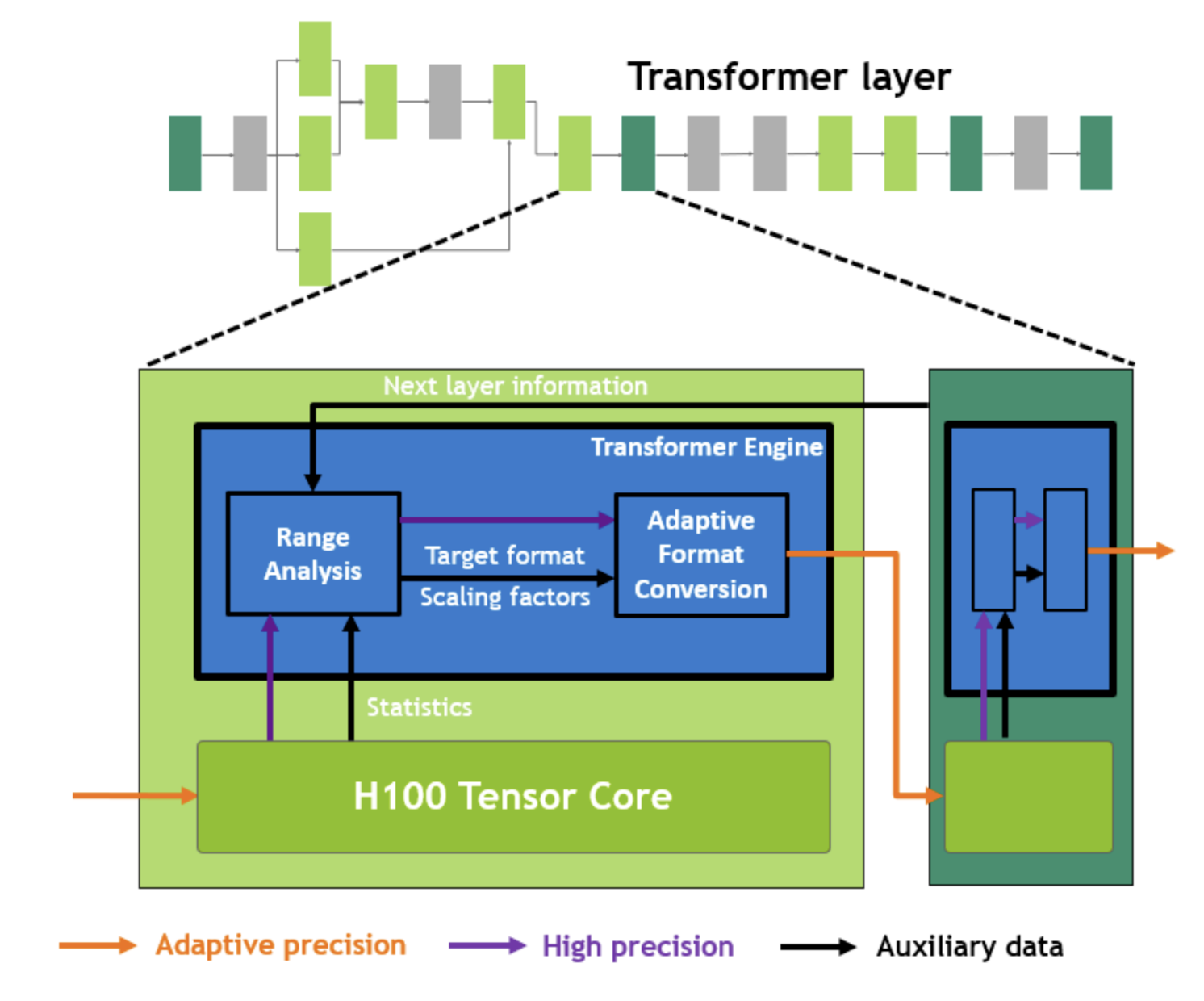 Hopper白皮书内容如下: >在 Transformer 模型的每一层,Transformer
Engine 都会分析 Tensor Core
产生的输出值的统计数据。了解了接下来会出现哪种类型的神经网络层以及它需要什么精度后,Transformer
Engine 还会决定将张量转换为哪种目标格式,然后再将其存储到内存中。 FP8
的范围比其他数字格式更有限。为了优化使用可用范围,Transformer Engine
还使用从张量统计数据计算的缩放因子动态地将张量数据缩放到可表示的范围内。因此,每一层都在其所需的范围内运行,并以最佳方式加速。
Hopper白皮书内容如下: >在 Transformer 模型的每一层,Transformer
Engine 都会分析 Tensor Core
产生的输出值的统计数据。了解了接下来会出现哪种类型的神经网络层以及它需要什么精度后,Transformer
Engine 还会决定将张量转换为哪种目标格式,然后再将其存储到内存中。 FP8
的范围比其他数字格式更有限。为了优化使用可用范围,Transformer Engine
还使用从张量统计数据计算的缩放因子动态地将张量数据缩放到可表示的范围内。因此,每一层都在其所需的范围内运行,并以最佳方式加速。
其他显存占用
- KV Cache:在推理过程中,大模型需要缓存一些中间结果,以便在处理下一个输入时重用。这些缓存的结果通常称为KV Cache。KV Cache占用的显存大小与模型的层数、序列长度和每个序列的token数量有关。
- 显存碎片:显存碎片是指显存中未被使用的空闲空间,这些空闲空间可能无法被有效利用,导致显存利用率降低。paged attention机制可以有效减少显存碎片。
推理与KV cache 显存
推理的时候,显存几乎只考虑模型参数本身,除此之外就是现在广泛使用的KV cache也会占用显存。KV cache与之前讲的如何减少显存不一样,KV cache的目的是减少延迟,也就是为了推理的速度牺牲显存。
kv cache介绍
具体可以参考另一篇博客:大模型优化--KV Cache KV Cache是Transformer标配的推理加速功能,transformer官方use_cache这个参数默认是True,但是它只能用于Decoder架构的模型,这是因为Decoder有Causal Mask,在推理的时候前面已经生成的字符不需要与后面的字符产生attention,从而使得前面已经计算的K和V可以缓存起来。
下图展示了使用KV Cache和不使用KV Cache的过程对比: 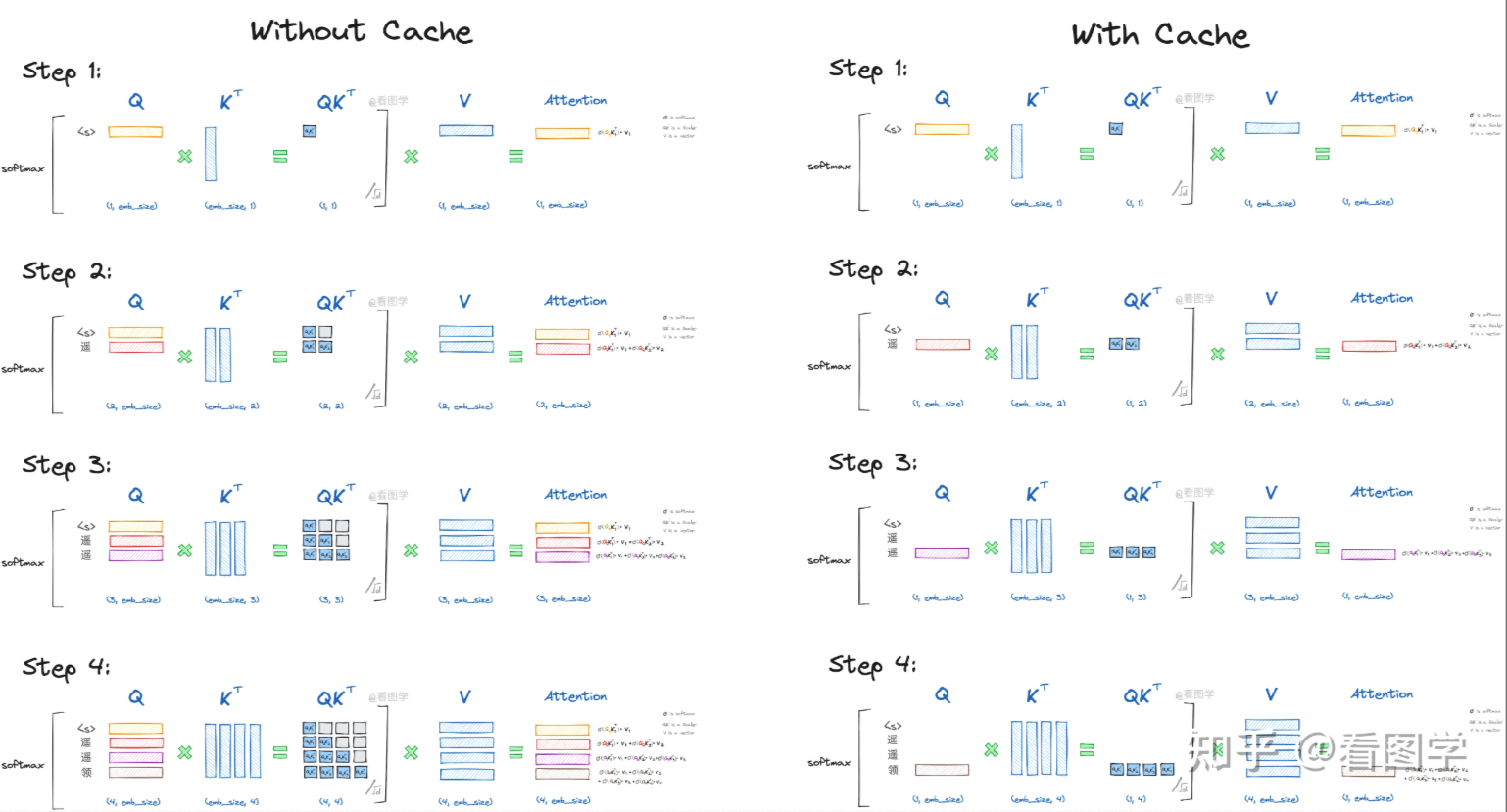 从图中,我们可以得出结论: - 当前计算方式存在大量冗余计算 - \(Attn_k\)只与\(Q_k\)有关 - 推理第\(x_k\)个字符时,只需要输入字符\(x_{k-1}\)即可。
第三个结论的前提是,我们需要把每一步的K和V缓存起来,这样在推理第\(x_k\)个字符时,只需要输入字符\(x_{k-1}\)计算其\(Q_k,K_k,V_k\), 结合之前保存的KV
Cache即可得到对应的\(Attn_k\)。
从图中,我们可以得出结论: - 当前计算方式存在大量冗余计算 - \(Attn_k\)只与\(Q_k\)有关 - 推理第\(x_k\)个字符时,只需要输入字符\(x_{k-1}\)即可。
第三个结论的前提是,我们需要把每一步的K和V缓存起来,这样在推理第\(x_k\)个字符时,只需要输入字符\(x_{k-1}\)计算其\(Q_k,K_k,V_k\), 结合之前保存的KV
Cache即可得到对应的\(Attn_k\)。
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)KV Cache显存占用
当sequence特别长的时候,KV Cache其实还是个Memory刺客。
对于fp16精度保存的KV Cache,其占用的显存大小为: \[ memory = batch\_size * hidden\_size * seq\_length * layer * 2 * 2 \] 其中两个2分别表示K和V,fp16精度字节数。
比如llama 7B模型,batch_size=32, layer=32, dim_size=4096, seq_length=2048, float32类型,则需要占用的显存为 2 * 32 * 4096 * 2048 * 32 * 4 / 1024/1024/1024 = 64G。
为了解决KV
Cache显存占用问题,研究者提出了MQA和GQA。其核心思想是:共享多头KV
Cache。  以GQA为例,我们将hidden_size维度切分为head*head_dim,然后将多个head分成group组,每个group共享一个KV。则总的KV
Cache显存占用为: \[
memory = batch\_size * group * head\_dim * seq\_length * layer * 2 * 2
\] 而MQA则是group=1,即每个head单独保存一个KV。
以GQA为例,我们将hidden_size维度切分为head*head_dim,然后将多个head分成group组,每个group共享一个KV。则总的KV
Cache显存占用为: \[
memory = batch\_size * group * head\_dim * seq\_length * layer * 2 * 2
\] 而MQA则是group=1,即每个head单独保存一个KV。
大模型推理加速:看图学KV Cache https://zhuanlan.zhihu.com/p/662498827
LoRA 与 QLoRA 训练显存
LoRA
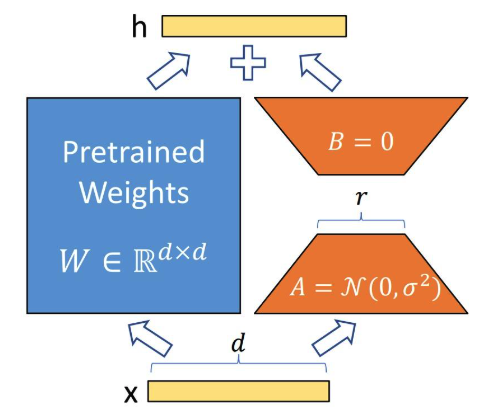 LoRA是在原来的权重矩阵的旁路新建一对低秩的可训练权重,训练的时候只训练旁路,大大降低了训练的权重数量,参数量从
dxd 降为 2xdxr。
LoRA是在原来的权重矩阵的旁路新建一对低秩的可训练权重,训练的时候只训练旁路,大大降低了训练的权重数量,参数量从
dxd 降为 2xdxr。
有了前面的全参情况下训练的显存分析,现在分析起来就比较通顺了,我们一步一步来,还是以BF16半精度模型Adamw优化器训练为例子,lora部分的参数精度也是BF16,并且设1字节模型参数对应的显存大小 \(\Phi\)。
- 首先是模型权重本身的权重,这个肯定是要加载原始模型和lora旁路模型的,因为lora部分占比小于2个数量级,所以显存分析的时候忽略不计,显存占用 \(2\Phi\)。
- 然后就是优化器部分,优化器也不需要对原模型进行备份了,因为优化器是针对于需要更新参数的模型权重部分进行处理,也就是说优化器只包含Lora模型权重相关的内容,考虑到数量级太小,也忽略不计,故优化器部分占用显存 0。
- 原始模型都不更新梯度,肯定只需要Lora部分的梯度显存,而这部分占用显存也可以近似为 0。 想深入探究的可以去看了一篇博文和大模型高效微调-LoRA原理详解和训练过程深入分析。
总的来说,不考虑激活值的情况下,Lora微调训练的显存占用只有\(2\Phi\),一个7B的模型Lora训练只需要占用显存大约14G左右。验证一下,我们来看Llama
Factory里给出训练任务的显存预估表格: 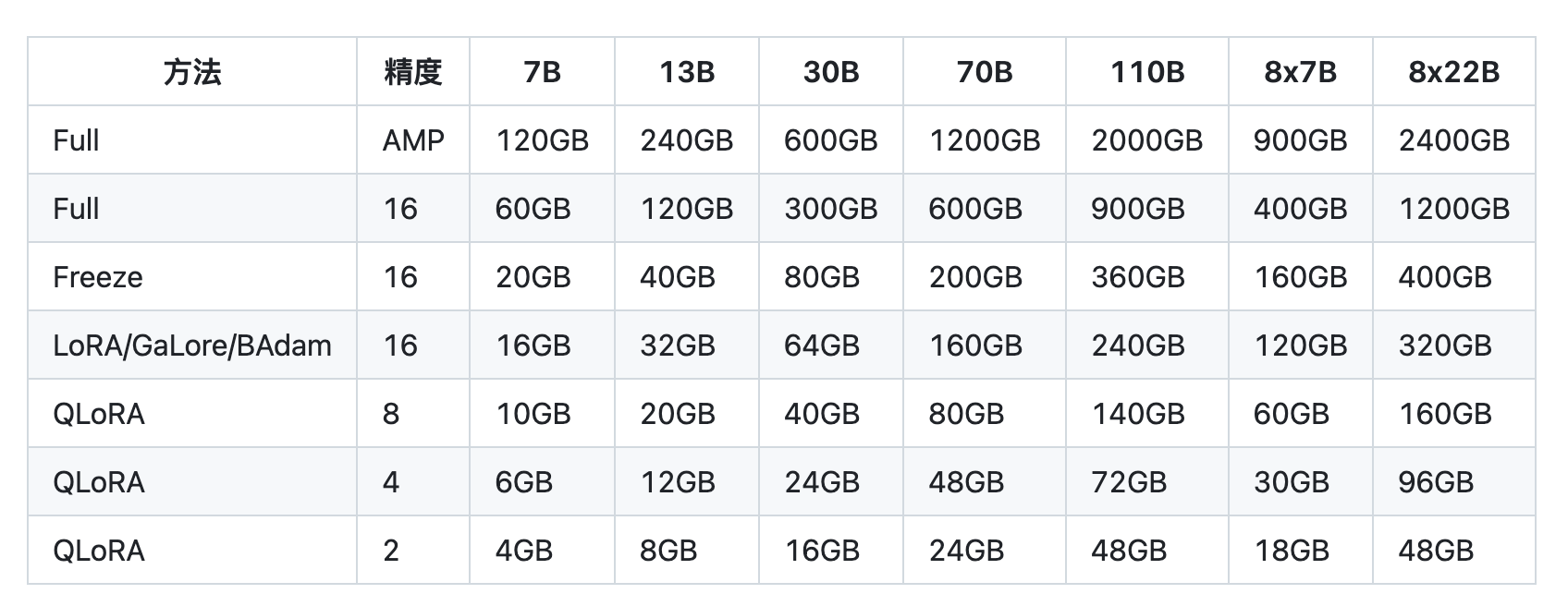
QLoRA
QLoRA本质上还是对模型的主体进行了量化,以4Bit量化为例,Qlora占用的显存主要就是4Bit量化后的模型本身也就是\(0.5\Phi\),由于A、B矩阵的参数量很小,故忽略不计。
总结
| 部分显存对应精度(训练) | 全参微调(全FP16) | 全参微调(BF16混合精度) | LoRA | QLoRA |
|---|---|---|---|---|
| 主干模型(模型存储/计算参数) | FP16/FP16 | BF16/BF16 | BF16/BF16 | NF4/BF16 |
| 主干模型(梯度) | FP16 | BF16 | Null | Null |
| 主干模型(adamw优化器) | 2 x FP16 | 3 x FP32 | Null | Null |
| LoRA部分(可忽略不计) | Null | Null | BF16 | BF16 |
| 总和(大约) | 8Byte | 16Byte | 2Byte | 0.5Byte |
huggingface 显存分析工具
huggingface 提供了一个工具可以方便的查看大模型在不同阶段消耗的显存大小。 model size estimator
参考资料
https://blog.zhexuan.org/archives/llm-gpu-memory.html
https://juejin.cn/post/7352387675837480995
https://gitcode.csdn.net/662a062ca2b051225566cf63.html
https://hub.baai.ac.cn/view/16045
https://zhuanlan.zhihu.com/p/624740065
NVIDIA H100 Tensor Core GPU Architecture:https://nvdam.widen.net/s/9bz6dw7dqr/gtc22-whitepaper-hopper



