KV Cache 介绍
KV Cache是Transformer标配的推理加速功能,transformer官方use_cache这个参数默认是True,但是它只能用于Decoder架构的模型,这是因为Decoder有Causal Mask,在推理的时候前面已经生成的字符不需要与后面的字符产生attention,从而使得前面已经计算的K和V可以缓存起来。
我们先看一下不使用KV Cache的推理过程。假设模型最终生成了“遥遥领先”4个字。
当模型生成第一个“遥”字时,input="<s>",
"<s>"是起始字符。Attention的计算如下: 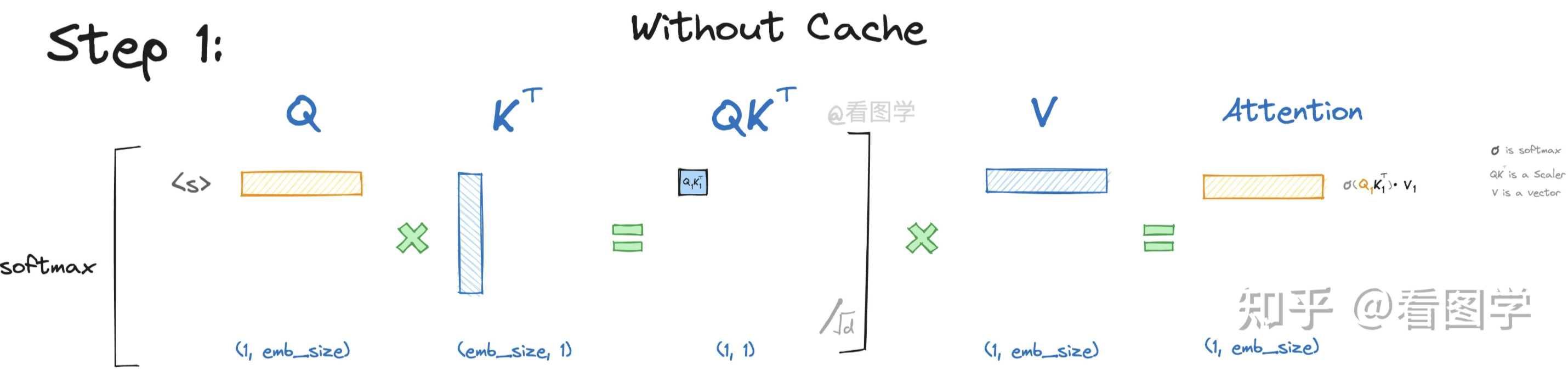
为了看上去方便,我们暂时忽略scale项\(1/\sqrt(d)\), 但是要注意这个scale面试时经常考。
如上图所示,最终Attention的计算公式如下,(softmaxed
表示已经按行进行了softmax): 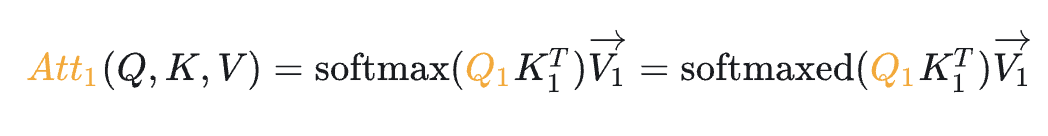
当模型生成第二个“遥”字时,input="<s>遥",
Attention的计算如下: 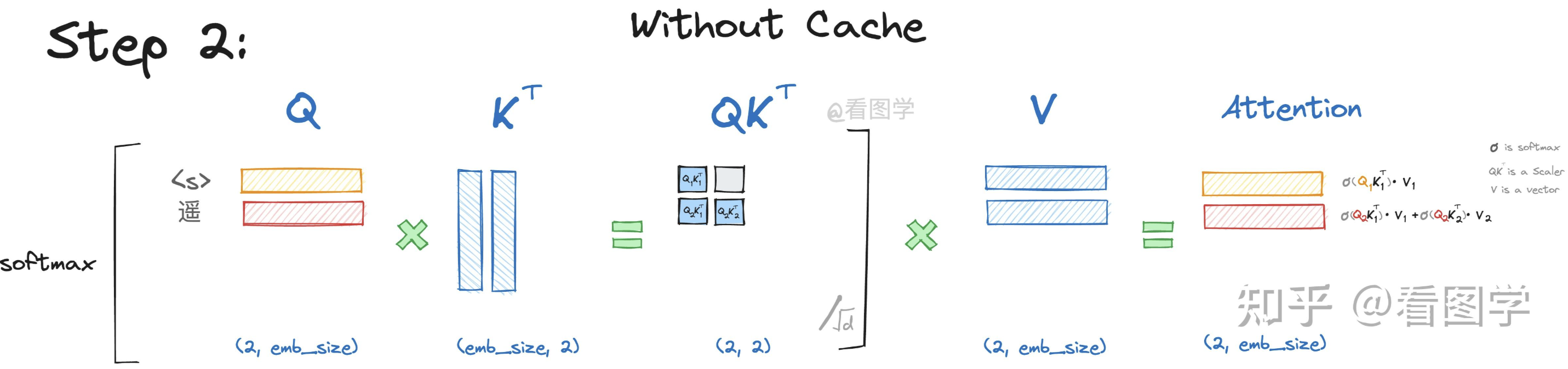
当QK变为矩阵时,softmax 会针对 行 进行计算。写详细一点如下,softmaxed 表示已经按行进行了softmax。
(关键)由于decoder架构的模型有Causal Mask,所以\(Q_1\)与\(K_2\)的计算结果为\(-\infty\)。 
假设\(Att_1\)表示 Attention
的第一行, \(Att_2\)表示 Attention
的第二行,则根据上面推导,其计算公式为: 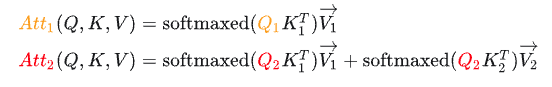
我们发现: - \(Q_1\)在第二步参与的计算与第一步是一样的,而且第二步生成的\(Att_1\)仅仅依赖于\(Q_1\),与\(Q_2\)毫无关系。 - \(Att_2\)仅仅依赖于\(Q_2\),与\(Q_1\)毫无关系。
当模型生成第三个“领”字时,input="<s>遥遥",
Attention的计算如下: 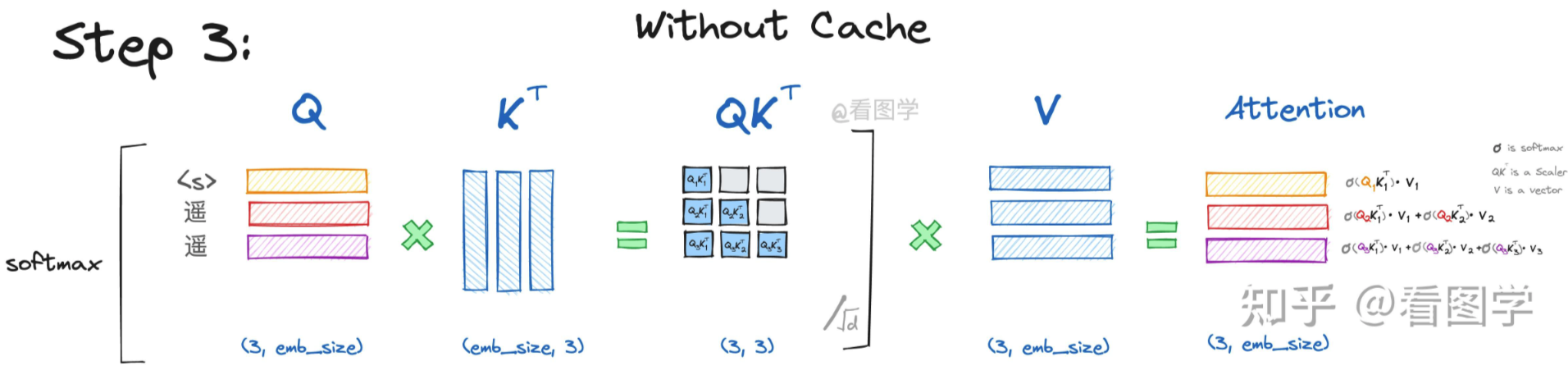 详细的推导参考第二步,其计算公式为:
详细的推导参考第二步,其计算公式为: 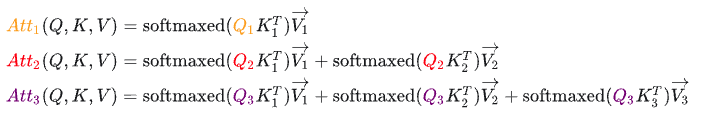 同样的,第三步生成的\(Att_3\)仅仅依赖于\(Q_3\),与\(Q_1\)和\(Q_2\)毫无关系。
同样的,第三步生成的\(Att_3\)仅仅依赖于\(Q_3\),与\(Q_1\)和\(Q_2\)毫无关系。
当模型生成第四个“先”字时,input="<s>遥遥领",
Attention的计算如下: 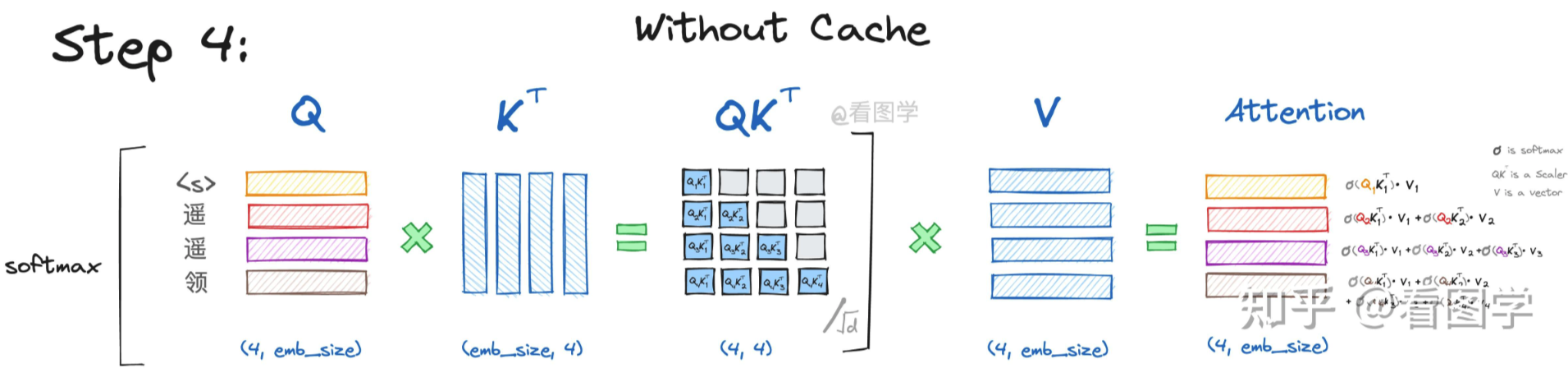
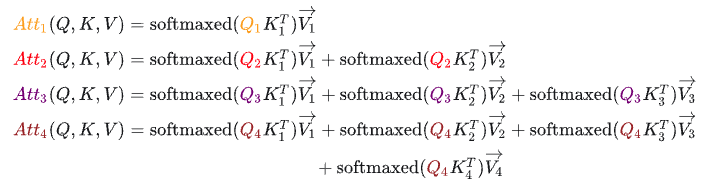 和之前类似,不再赘述。
和之前类似,不再赘述。
看上面图和公式,我们可以得出结论: - 当前计算方式存在大量冗余计算 - \(Attn_k\)只与\(Q_k\)有关 - 推理第\(x_k\)个字符时,只需要输入字符\(x_{k-1}\)即可。 第三个结论的前提是,我们需要把每一步的K和V缓存起来,这样在推理第\(x_k\)个字符时,只需要输入字符\(x_{k-1}\)计算其\(Q_k,K_k,V_k\), 结合之前保存的KV Cache即可得到对应的\(Attn_k\)。
下图展示了使用KV Cache和不使用KV Cache的过程对比: 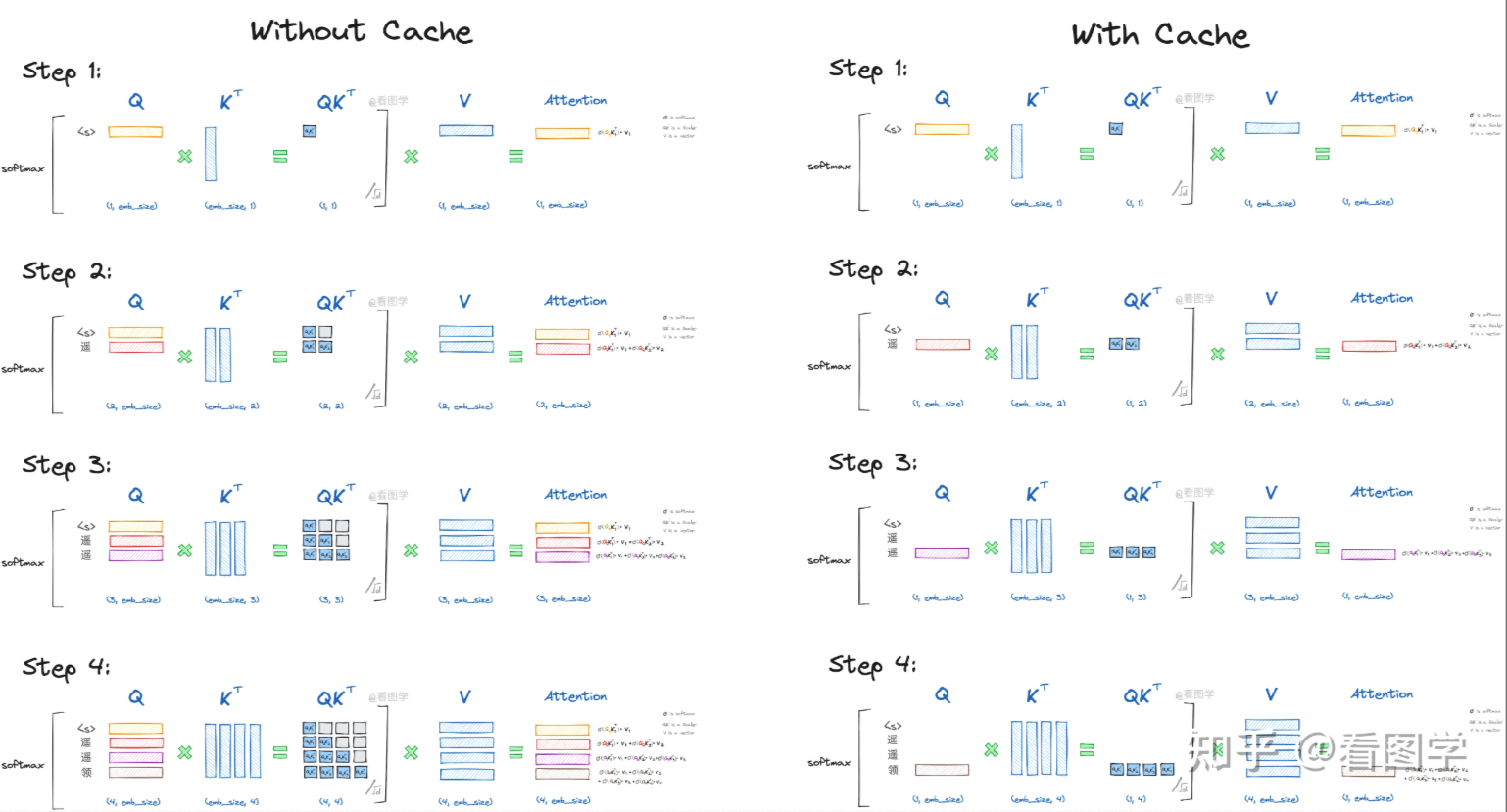
if layer_past is not None:
past_key, past_value = layer_past
key = torch.cat((past_key, key), dim=-2)
value = torch.cat((past_value, value), dim=-2)
if use_cache is True:
present = (key, value)
else:
present = None
if self.reorder_and_upcast_attn:
attn_output, attn_weights = self._upcast_and_reordered_attn(query, key, value, attention_mask, head_mask)
else:
attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask) ### 解码阶段
### 解码阶段 
KV Cache采用动态分配缓冲区大小,当超过当前容量时,内存大小会翻倍。这种方法虽然可行,但在 GPU 上频繁申请和释放内存的开销较大,导致效率较低。目前流行的解决办法是数据拆分与元数据管理:将数据按最小单元存储,并使用元数据记录每一块数据的位置,称为 PageAttention。程序在初始化时申请一块较大的显存区域(例如 4GB),然后按照 KVCache 的大小将显存划分成多个小块,并记录每个 token 在推理过程中需要访问的小块。显存的分配、释放和管理类似于操作系统对物理内存的虚拟化过程。这一思路被 vLLM(具体参见论文 Efficient Memory Management for Large Language Model Serving with PagedAttention)所采用,并广泛应用于大规模语言模型的推理中。
MQA与GQA
在GPU上部署模型时,我们遵循的原则是:能在一张卡上部署的,就不要跨多张卡;能在一台机器上部署的,就不要跨多台机器。这是因为“卡内通信带宽 > 卡间通信带宽 > 机间通信带宽”。由于“木桶效应”,模型部署时跨的设备越多,受到设备间通信带宽的制约就越大。
因此,减少 KV Cache 的目的是为了在更少的设备上推理更长的 Context,或者在相同的 Context 长度下实现更大的推理 batch size,从而提升推理速度或增加吞吐总量。最终目的都是为了降低推理成本。
MHA
MHA(Multi-Head Attention),也就是多头注意力,是 Transformer 中的标准 Attention 形式。在数学上,多头注意力 MHA 等价于多个独立的单头注意力的拼接。其遵循前面所讲的KV Cache 的原理。而后面的 MQA、GQA、都是围绕“如何减少 KV Cache 同时尽可能地保证效果”这个主题发展而来的产物。
MQA
MQA,即“Multi-Query Attention”,2019年由 Google 在论文 Fast Transformer Decoding: One Write-Head is All You Need 中提出。
 使用 MQA 的模型包括 PaLM、StarCoder、Gemini 等。很明显,MQA 直接将 KV
Cache 减少到了原来的 1/head_num。
使用 MQA 的模型包括 PaLM、StarCoder、Gemini 等。很明显,MQA 直接将 KV
Cache 减少到了原来的 1/head_num。
效果方面,目前看来大部分任务的损失都比较有限。
GQA
也有人担心 MQA 对 KV Cache
的压缩太严重,以至于会影响模型的学习效率以及最终效果。为此,一个 MHA 与
MQA 之间的过渡版本 GQA(Grouped-Query Attention)应运而生,出自 2023 年
Google 的论文 GQA: Training
Generalized Multi-Query Transformer Models from Multi-Head
Checkpoints。 

| 模型 | 参数量 | 非Embedding参数量 | GQA | 上下文长度 |
|---|---|---|---|---|
| Qwen2-0.5B | 0.49B | 0.35B | √ | 32K |
| Qwen2-1.5B | 1.54B | 1.31B | √ | 32K |
| Qwen2-7B | 7.07B | 5.98B | √ | 128K |
| Qwen2-57B-A14B | 57.41B | 56.32B | √ | 64K |
| Qwen2-72B | 72.71B | 70.21B | √ | 128K |
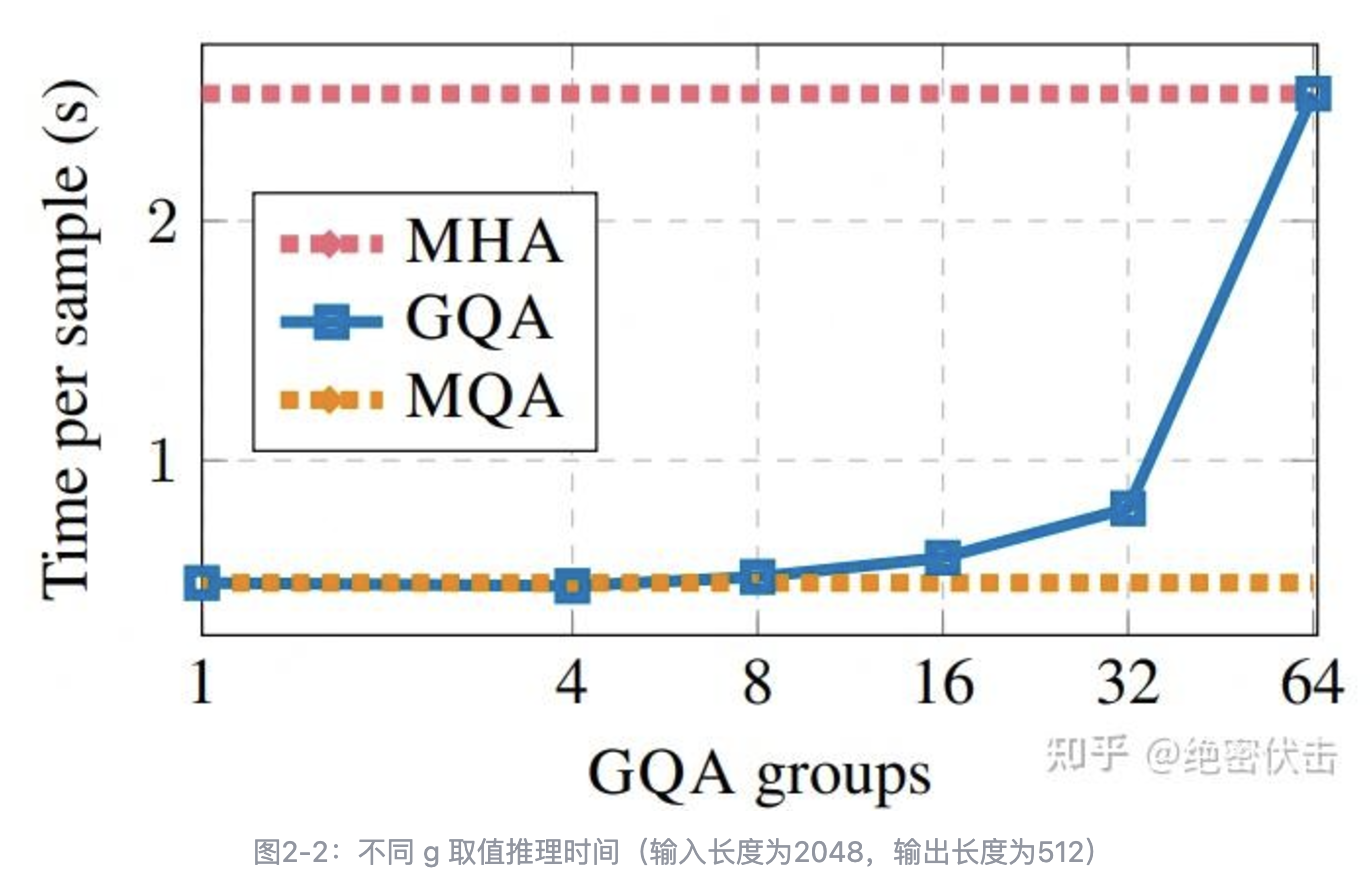
在 Llama 2/3-70B 中,GQA 的 g=8 ,其他用了 GQA 的同体量模型基本上也保持了这个设置,这并非偶然,而是同样出于推理效率的考虑。我们知道,70B 这个体量的模型,如果不进行极端的量化,那么不可能部署到单卡(A100/H100 80G)上。单卡不行,那么就能单机了,一般情况下一台机可以装 8 张卡,Attention 的每个Head 实际上是独立运算然后拼接起来的,当 g=8 时,正好可以每张卡负责计算一组 K、V 对应的 Attention Head,这样可以在尽可能保证 K、V 多样性的同时最大程度上减少卡间通信。
下面看一下 GQA 的实验效果。 | 模型 | 推理时间 | 效果 | | ---------- | -------- | ----- | | MHA-Large | 0.37 | 46.0 | | MHA-XXL | 1.51 | 47.2 | | MQA-XXL | 0.24 | 46.6 | | GQA-8-XXL | 0.28 | 47.1 |
参考: > https://zhuanlan.zhihu.com/p/708120479
大模型推理加速:看图学KV Cache https://zhuanlan.zhihu.com/p/662498827



