前言
基于KV Cache的大模型推理过程通常分为两个阶段:Prefill 和 Decoding。
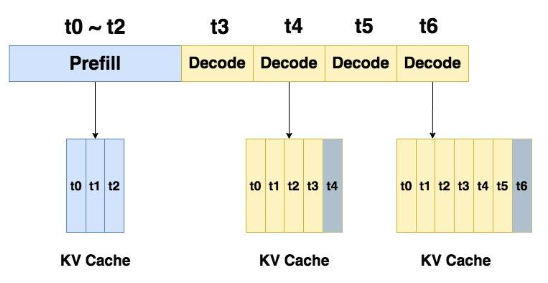
在 Prefill 阶段,推理引擎将整段 prompt 输入模型进行前向计算。如果引入了 KV Cache 技术,prompt 经 Wk 和 Wv 计算得到的结果(即 K 和 V)会被存储到 K Cache 和 V Cache 中。这样,在后续 token 的 Attention 计算中,无需重复计算 K 和 V,从而显著节约计算时间。
进入 Decoding 阶段后,推理引擎会基于 Prefill 阶段的结果,逐步生成响应,每次输出一个 token。如果同样使用了 KV Cache,每生成一个 token,都会将其对应的 K 和 V 值存入缓存,加速后续推理。
下图展示了一个13B的模型在A100
40GB的gpu上做推理时的显存占用分配(others表示forward过程中产生的activation的大小,这些activation你可以认为是转瞬即逝的,即用完则废,因此它们占据的显存不大),从这张图中我们可以直观感受到推理中KV
cache对显存的占用。因此,如何优化KV
cache,节省显存,提高推理吞吐量,就成了LLM推理框架需要解决的重点问题。

KV Cache的常规存储分配
由于推理所生成的序列长度大小无法事先预知,所以大部分推理框架都会按 batch_size x max_seq_len 这样的固定尺寸来分配。在请求到来时,预先在显存中申请一块连续的区域。然而,这种“静态”显存分配策略,显存利用率是很低的。
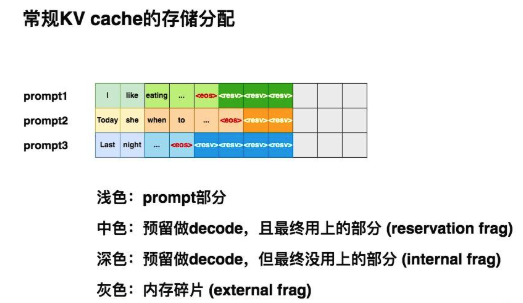
我们假设 max_seq_len = 8,所以当第1条请求(prompt1)过来时,我们的推理框架为它安排了(1, 8)大小的连续存储空间。
当第2条请求(prompt2)过来时,同样也需要1块(1, 8)大小的存储空间。但此时prompt1所在的位置上,只剩3个空格子了,所以它只能另起一行做存储。对prompt3也是同理。
问题:
- 浅色块:prefill阶段prompt的KV cache,是无论如何都会被使用的空间,它不存在浪费。
- 中色块:decode阶段的KV
cache,其中
表示序列生成的截止符。虽然这些中色块最终都会被我们用上,但是在decode阶段一个个token生成时,我们并不能预知哪些块会被最终用上,导致一种“潜在的浪费”, 称为预留碎片(reservation fragment)。 - 深色块:decode阶段预留空间但是最终没有用上,称为内部碎片(internal fragment)。
- 灰色块:不是预留的KV cache的一部分,且最终也没有被用上,称这些灰色块为外部碎片(external fragment)。想象一下,此时新来了一条prompt4,它也要求显存中的8个格子作为KV cache。此时你的显存上明明有9个空格子,但因为它们是不连续的碎片,所以无法被prompt4所使用。这时prompt4的这条请求只好在队列中等待,直到gpu上有足够显存资源时再进行推理。
观察整个KV cache排布,你会发现它们的毛病在于太过
“静态化”。当你无法预知序列大小时,你为什么一定要死板地为每个序列预留KV
cache空间呢?为什么不能做得更动态化一些,即“用多少占多少”呢?这样我们就能减少上述这些存储碎片,使得每一时刻推理服务能处理的请求更多,提高吞吐量,这就是vLLM在做的核心事情,我们先通过一张实验图来感受下vLLM在显存利用上的改进效果(VS
其它推理框架): 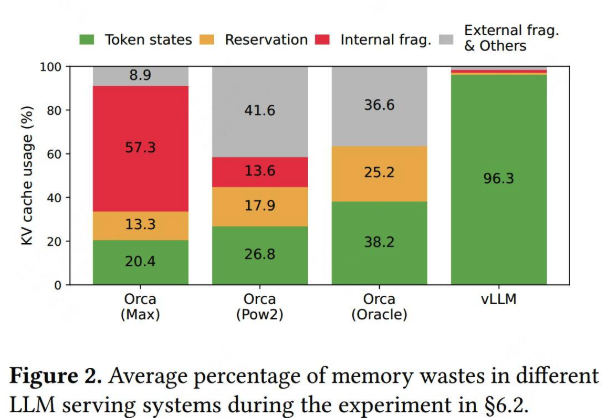
不难发现,相比于别的推理框架,vLLM几乎能做到将显存完全打满。
PagedAttention
vLLM通过一种名为PagedAttention的技术,动态地为请求分配KV cache显存,提升显存利用率。
整体上来说,PagedAttention的设计灵感来自操作系统中虚拟内存的分页管理技术。
操作系统的虚拟内存
虚拟内存分页是一种操作系统管理内存的技术,它将物理内存抽象为一个连续的虚拟地址空间,使每个进程都像拥有独立的内存。 分页通过将内存划分为固定大小的页(虚拟内存)和页框(物理内存)进行管理。页表记录虚拟页到物理页框的映射关系。 若虚拟页不在物理内存中,会发生页缺失(Page Fault),操作系统会从磁盘调入对应页。分页提高了内存利用率,并支持进程隔离与动态内存扩展。
分段式内存管理
在分段式内存管理中,虚拟内存会尽量为每个进程在物理内存上找到一块连续的存储空间,让进程加载自己的全部代码、数据等内容。
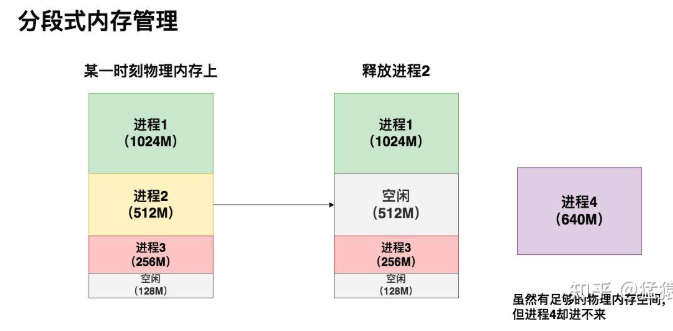
在这个例子中,3个进程的虚拟内存各自为它们在物理内存上映射了一块连续的存储空间。在某一时刻,我释放了进程2,同时想运行进程4。这时我尴尬地发现,虽然物理内存上有640M的空间剩余,但因为是碎片化的,我的进程4无法加载进去,因此它只能等待。
在这个情况下,如果我硬要运行进程4,也是有办法的:我可以先把进程3从物理内存上交换(swap)到磁盘上,然后把进程4装进来,然后再把进程3从磁盘上加载回来。通过这种方法我重新整合了碎片,让进程4能够运行。
但这种办法的显著缺点是:如果进程3过大,同时内存到磁盘的带宽又不够,整个交换的过程就会非常卡顿。这就是分段式内存管理的缺陷。
分页式内存管理
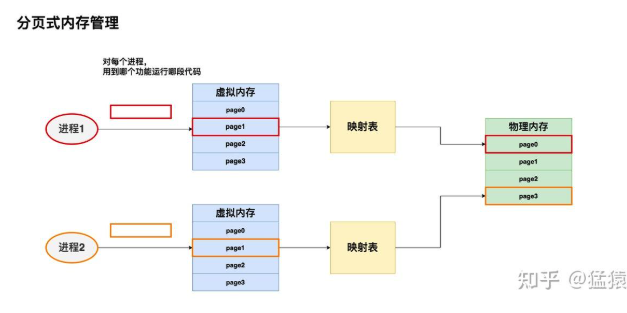
虚拟内存的分页管理技术总结起来就是:
- 将物理内存划分为固定大小的块,我们称每一块为页(page)。从物理内存中模拟出来的虚拟内存也按相同的方式做划分
- 对于1个进程,我们不需要静态加载它的全部代码、数据等内容。我们想用哪部分,或者它当前跑到哪部分,我们就动态加载这部分到虚拟内存上,然后由虚拟内存帮我们做物理内存的映射。
- 对于1个进程,虽然它在物理内存上的存储不连续(可能分布在不同的page中),但它在自己的虚拟内存上是连续的。通过模拟连续内存的方式,既解决了物理内存上的碎片问题,也方便了进程的开发和运行。
PagedAttention 工作流程
假设现在你向推理引擎发送请求,prompt 为 Four score and seven years
ago our,你希望模型进行续写。PagedAttention 的运作流程如下 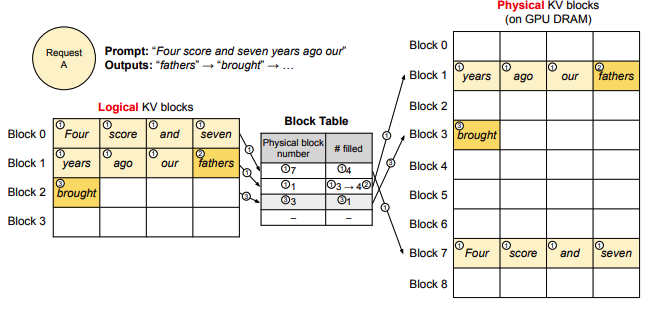
Prefill 阶段:
划分逻辑块:vLLM 在接收到这条 prompt 后,会根据设定的块大小 B(本例中 B=4),将 prompt 划分为若干逻辑块(Logical KV Blocks)。由于该 prompt 包含 7 个 token,因此 vLLM 使用两个逻辑块(block 0 和 block 1)来存储它们的 KV 值。在逻辑块 1 中,目前仅存储了 "years"、"ago" 和 "hour" 这 3 个 token 的 KV 值,还有 1 个位置为空,称为保留位(Reservation)。
划分物理块:完成逻辑块的划分后,这些逻辑块会映射到物理块,即实际存储 KV 值的空间。映射关系通过一张 block table(块表)记录,其主要内容包括: - 逻辑块与物理块的映射关系(Physical Block Number):例如,逻辑块 0 映射到物理块 7。 - 物理块已填满的槽位数量(# Filled):例如,在 Prefill 阶段,物理块 7 的 4 个槽位已填满,而物理块 1 的 4 个槽位中填满了 3 个。
系统正常计算 prompt 的 KV 值后,根据上述划分关系,将这些值填入对应的物理块中。
Decode 阶段:
在使用 KV cache 计算 attention 并生成第一个词 "fathers" 时,不难发现,计算过程中使用的是逻辑块,即从形式上看,这些 token 是连续的。与此同时,vLLM 通过后台的 block table 映射关系,从对应的物理块中获取数据以完成实际计算。通过这种方式,每个请求都能认为自己是在一个连续且充足的存储空间上操作,尽管这些数据在物理存储上并不是连续的。
基于新生成的词,系统会对逻辑块、物理块和 block table 进行更新。例如,对于 block table,vLLM 将其 filled 字段从 3 更新为 4。
当 "fathers" 被写入后,当前逻辑块已装满,因此 vLLM 会开辟一个新的逻辑块(逻辑块 2),并同步更新 block table 和对应的物理块,以确保后续生成过程能够顺利进行。
PagedAttention在不同解码策略下的运作
我们知道,根据实际需求,大模型的解码方式也比较复杂,例如:
- Parallel Sampling:我给模型发送一个请求,希望它对prompt做续写,并给出三种不同的回答。我们管这个场景叫parallel sampling。在这个场景中,我们可以将prompt复制3次后拼接成1个batch喂给模型,让它做推理。但我们也需注意到,这种方式会产生prompt部分KV cache的重复存储。
- Beam Search 束搜索:这是LLM常用的deocde策略之一,即在每个decode阶段,我不是只产生1个token,而是产生top k个token(这里k也被称为束宽)。top k个token必然对应着此刻的top k个序列。我把这top k个序列喂给模型,假设词表的大小为|V|,那么在下一时刻,我就要在k*|V|个候选者中再选出top k,以此类推。不难想象每一时刻我把top k序列喂给模型时,它们的前置token中有大量的KV cache是重复的。
- Shared prefix:在某些大模型中,所有请求可能都会共享一个前置信息(比如system message: “假设你是一个有帮助的AI助手...."),这些前置信息没有必要重复存储KV cache
- 其余一般场景:在一些更通用的场景中,虽然两个prompt可能完全没有关系,但它们中某些KV cache却是可以共用的。例如两个prompt的相同位置(position)恰好出现了完全一样的序列,比如它们的结尾都是好想下班。假设这个相同序列已经存在于KV cache中,那也没有必要重复计算和存储了。 纠正: 对于部分序列部分相同的情况,应该是只能作用在layer1的KV cache上,而不能作用在后序的KV cache上。因为计算完layer1的attention后,后面的序列已经不重复了。
Parallel Sampling
传统KV cache怎么做: 假设模型的max_seq_len = 2048。传统KV cache可能在显存中分配两块长度是2048的空间。由于prompt一致,这两块2048的空间中存在大量重复的KV cache。
vLLM怎么做: 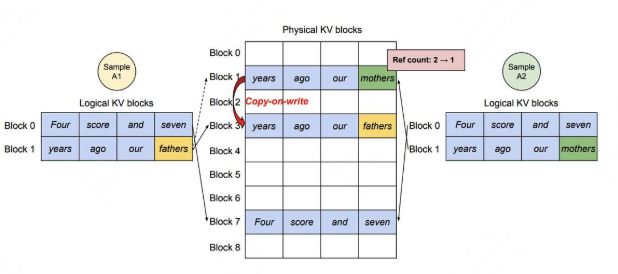 假定我们发给模型1个request,这个request中包含2个prompt/sample,记为Sample
A1和Sample A2,这两个prompt完全一致,都为Four score and seven years ago
our,我们希望模型对这两个prompt分别做续写任务。 - Prefill阶段: -
分配逻辑块:对于A1,vLLM为其分配逻辑块block0和block1;对于A2,vLLM为其分配逻辑块block0和block1。需要注意的是,A1的逻辑块和A2的逻辑块是独立的(尽管它们都叫block0和block1),你可以将A1和A2视作操作系统中两个独立运行的进程。
-
分配物理块:对于A1和A2,虽然逻辑块独立,但因为它们的文字完全相同,所以可以在物理内存上共享相同的空间。所以A1的逻辑块block0/1分别指向物理块block7/1;A2的逻辑块block0/1分别指向物理块block7/1。我们设每个物理块下映射的逻辑块数量为ref
count,所以对物理块block7/1来说,它们的ref count都为2。 -
decode阶段:A1和A2各自做推理,得到第一个token,分别为fathers和mothers。
-
将生成的token装入逻辑块:对于A1和A2来说,将其生成的token装入各自的逻辑块block1。
-
触发物理块copy-on-write机制:由于fathers/mothers是两个完全不同的token,因此对物理块block1触发复制机制,即在物理内存上新开辟一块空间。此时物理块block1只和A2的逻辑块block1映射,将其ref
count减去1;物理块block3只和A1的逻辑块block1映射,将其ref
count设为1。
假定我们发给模型1个request,这个request中包含2个prompt/sample,记为Sample
A1和Sample A2,这两个prompt完全一致,都为Four score and seven years ago
our,我们希望模型对这两个prompt分别做续写任务。 - Prefill阶段: -
分配逻辑块:对于A1,vLLM为其分配逻辑块block0和block1;对于A2,vLLM为其分配逻辑块block0和block1。需要注意的是,A1的逻辑块和A2的逻辑块是独立的(尽管它们都叫block0和block1),你可以将A1和A2视作操作系统中两个独立运行的进程。
-
分配物理块:对于A1和A2,虽然逻辑块独立,但因为它们的文字完全相同,所以可以在物理内存上共享相同的空间。所以A1的逻辑块block0/1分别指向物理块block7/1;A2的逻辑块block0/1分别指向物理块block7/1。我们设每个物理块下映射的逻辑块数量为ref
count,所以对物理块block7/1来说,它们的ref count都为2。 -
decode阶段:A1和A2各自做推理,得到第一个token,分别为fathers和mothers。
-
将生成的token装入逻辑块:对于A1和A2来说,将其生成的token装入各自的逻辑块block1。
-
触发物理块copy-on-write机制:由于fathers/mothers是两个完全不同的token,因此对物理块block1触发复制机制,即在物理内存上新开辟一块空间。此时物理块block1只和A2的逻辑块block1映射,将其ref
count减去1;物理块block3只和A1的逻辑块block1映射,将其ref
count设为1。
总结起来,vLLM节省KV cache显存的核心思想是,对于相同数据对应的KV cache,能复用则尽量复用;无法复用时,再考虑开辟新的物理空间。
Beam Search

我们从右往左来看这张图。虚线位置表示“当前decoding时刻”,beam width = 4。图中所有的block皆为逻辑块。
因为beam width = 4,这意味着根据beam search算法,在当前阶段我们生成了top 4个概率最大的token(我们记这4个token为beam candidate 0/1/2/3),它们分别装在block5,block6,block7和block8中。
现在我们继续使用beam search算法做decoding,继续找出top 4个最可能的next token。经过我们的计算,这top 4 next token,有2个来自beam candidate 1,有2个来自beam candidate 2。因此我们在block6中引出block9和block10,用于装其中两个top 2 next token;对block7也是同理。
现在,block9/10/11/12中装的top 4 next token,就成为新的beam candidates,可以按照和上述一样的方式继续做beam search算法。而对于block5和block8,它们已经在beam search的搜索算法中被淘汰了,后续生成的token也不会和它们产生关系,所以可以清除掉这两个逻辑块,并释放它们对应的物理块的内存空间。
好,我们继续往左边来看这幅图。block3引出block5/6/7,block4引出block8,这意味着当前这4个top4 token,是上一个timestep下candidate1和candidate3相关序列生成的(candidate0和2的block没有画出,是因为它们所在的序列被beam search算法淘汰了,因此没有画出的必要)。由于block8已经被淘汰,所以block4也相继被淘汰,并释放对应的物理内存空间。
由此往左一路推,直到block0为止(block0代表着prompt,因此被beam seach中所有的序列共享)。这一路上,我们都根据最新时刻的beam search decoding结果,释放掉不再被需要的逻辑块和对应的物理内存空间,达到节省显存的目的。
调度和抢占
到目前为止,我们已经解答了“vLLM 如何优化 KV cache 的显存分配”这一问题。接下来,我们将探讨另一个关键问题:当采用动态显存分配策略时,虽然表面上可以同时处理更多的 prompt,但由于没有为每个 prompt 预留充足的显存空间,如果某一时刻显存被完全占满,而所有正在运行的 prompt 都尚未完成推理,系统又该如何应对呢?
vllm 的调度和抢占原则:
- 采用“先到先服务”(FCFS)的调度策略来处理所有请求,确保公平性并防止请求饿死。
- 当 vLLM 需要抢占请求时,它会优先服务最早到达的请求,并优先抢占最新到达的请求。暂停它们的执行,同时将与之相关的 KV cache 从 gpu 上释放掉。等 gpu 资源充足时,重新恢复它们的执行。
Swapping交换策略
对于被抢占的请求,vLLM要将其KV cache从gpu上释放掉,那么:
问题1:该释放哪些KV cache? 由前文PagedAttention原理可知,一个请求可能对应多个block。我们既可以选择释放掉部分block,也可以选择释放掉全部block,或者更科学地,我们可以预测一下哪些block被使用的频率最低,然后释放掉这些低频block(但这种方式实现起来难度较大,性价比不是很高)。
在vLLM中,采取的是all-or-nothing策略,即释放被抢占请求的所有block。
问题2:要把这些KV cache释放到哪里去? 对于这些被选中要释放的KV block,如果将它们直接丢掉,那未免过于浪费。vLLM采用的做法是将其从gpu上交换(Swap)到cpu上。这样等到gpu显存充份时,再把这些block从cpu上重载回来。
Recomputing重计算策略
知道了Swapping机制,重计算的过程也很好理解了:对于有些任务,当它们因为资源不足而被抢占时,可以不做swap,而是直接释放它们的物理块,把它们重新放入等待处理的队列中,等后续资源充足时再重新从prefill阶段开始做推理。
比如parallel sampling中并行采样数n=1的任务,对于这种小粒度任务,直接重计算(从 prefill 阶段重新开始)所需的成本可能比执行 swapping(迁移内存到 CPU)并在未来重新加载更低。Swapping 的过程会将内存页(或张量)从 GPU 转移到 CPU,这涉及到 PCIe 或 NVLink 通信,速度远低于 GPU 内部计算和内存操作。
分布式管理
最后,我们一起来看一下vLLM的整体架构。 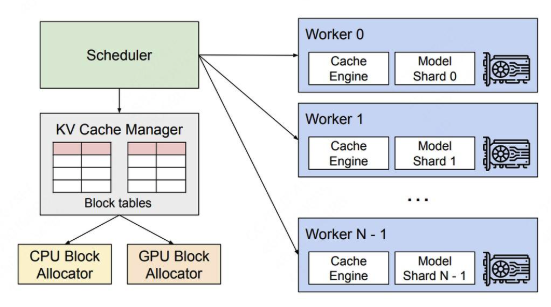
在分布式场景下,vLLM 的整体运作流程如下:
- 中央调度器(Scheduler):vLLM 配备了一个中央调度器,负责计算并管理每张显卡上 KV cache 从逻辑块到物理块的映射表(block tables)。
- 映射表广播:在进行分布式计算时,Scheduler 会将生成的映射表广播到各显卡。
- 缓存引擎管理:每张显卡上的 Cache Engine 在接收到对应的映射信息后,负责具体管理该显卡上的 KV block。
上图中给出的例子,是用张量模型并行(megatron-lm)做分布式推理时的情况,所以图中每个worker上写的是model shard。在张量并行中,各卡上的输入数据相同,只是各卡负责计算不同head的KV cache。所以这种情况下,各卡上的逻辑块-物理块的映射关系其实是相同的(用的同一张block table),只是各卡上物理块中实际存储的数据不同而已。
参考资料: > 极智AI | 大模型优化技术PagedAttention:https://juejin.cn/post/7290163879287881765
图解大模型计算加速系列之:vLLM核心技术PagedAttention原理:https://zhuanlan.zhihu.com/p/691038809
LLM推理优化 - PagedAttention:https://www.yidoo.xyz/paged-attention



