参数高效微调PEFT
微调
微调(Fine-tuning)是一种迁移学习的技术,用于在一个已经预训练好的模型基础上,通过进一步训练来适应特定的任务或数据集。微调可以在具有相似特征的任务之间共享知识,从而加快训练速度并提高模型性能。
以下是一般的微调步骤:
- 选择择预训练模型:选择一个在大规模数据集上预训练好的模型,如ImageNet上的预训练的卷积神经网络(如ResNet、VGG等)。这些模型通常具有良好的特征提取能力。
- 冻结底层权重:将预训练模型的底层权重(通常是卷积层)固定住,不进行训练。这是因为底层权重通常学习到了通用的特征,可以被用于许多不同的任务。
- 替换顶层分类器:将预训练模型的顶层分类器(通常是全连接层)替换为适合特定任务的新的分类器。新的分类器的输出节点数量应该与任务的类别数相匹配。
- 解冻部分权重(可选):根据任务的复杂性和可用的训练数据量,可以选择解冻一些底层权重,以便更好地适应新的任务。这样可以允许底层权重进行微小的调整,以更好地适应新任务的特征。
- 进行训练:使用特定任务的训练数据集对新的分类器进行训练。可以使用较小的学习率进行训练,以避免对预训练模型的权重进行过大的更新。
- 评估和调整:在训练完成后,使用验证集或测试集评估模型的性能。根据评估结果,可以进行调整,如调整学习率、调整模型结构等。
微调的关键是在预训练模型的基础上进行训练,从而将模型的知识迁移到特定任务上。通过这种方式,可以在较少的数据和计算资源下,快速构建和训练高性能的模型。
PEFT
PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)是一种在大语言模型(Large Language Model,LLM)上进行微调的新技术,旨在降低微调大模型的计算和存储成本,使得微调过程更为高效。与传统的微调技术相比,PEFT 可以显著减少训练所需的参数量,并保持与标准微调相似的性能。PEFT 技术在优化资源效率、降低硬件需求、并提高开发灵活性方面有显著优势,特别是在需要频繁微调以适应不同任务或领域的场景中尤为有用。
目前主流的方法包括2019年 Houlsby N 等人提出的 Adapter Tuning,2021年微软提出的 LORA,斯坦福提出的 Prefix-Tuning,谷歌提出的 Prompt Tuning,2022年清华提出的 P-tuning v2。
- Adapter Tuning 在模型的某些层之间插入小的适配器模块,而不对原有的大量参数进行修改。适配器模块通常包含一小部分可训练的参数,并通过这些参数来调整模型的输出;但是增加了模型层数,引入了额外的推理延迟
- Prefix-Tuning 每个 Transformer 层前面添加一个可学习的前缀(prefix)来实现模型的调整。这个前缀是固定长度的,可视作特定任务的提示(prompt);但是预留给 Prompt 的序列挤占了下游任务的输入序列空间,影响模型性能
- P-tuning v2 使用可学习的嵌入来替代硬编码的提示文本;但是很容易导致旧知识遗忘,微调之后的模型,在之前的问题上表现明显变差
- 基于上述背景,LORA 得益于前人的一些关于内在维度(intrinsic dimension)的发现:
模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。
假设模型在任务适配过程中权重的改变量是低秩(low rank)的,由此提出低秩自适应(LoRA)方法。
LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵,来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
LoRA
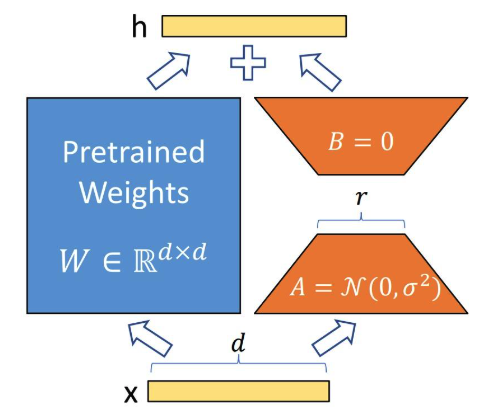 LoRA 的思想很简单:
LoRA 的思想很简单:
在原始 PLM (Pre-trained Language Model) 旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的intrinsic rank。
训练的时候固定 PLM 的参数,只训练降维矩阵 与升维矩阵。而模型的输入输出维度不变,输出时将与 PLM 的参数叠加。
用随机高斯分布初始化 A,用 0 矩阵初始化 B,保证训练的开始此旁路矩阵依然是 0 矩阵。 > 为什么A用随机高斯分布初始化,B用0矩阵初始化呢?
首先增量矩阵\(\Delta W = BA\) 在训练刚开始肯定是要用0来初始化。
如果A用0矩阵初始化,在计算梯度时由于B的梯度有一个因子A,导致B的梯度始终为0,无法被更新,导致梯度传播受阻。
我们也可以理解为因为A是降维矩阵,所以它能够学到一些有用的信息,所以用随机高斯分布初始化;而B是升维矩阵,我们希望它能够保持原始信息,所以用0矩阵初始化。
秩的选择 在 Transformer 中,LoRA 主要作用在
attention 过程的四个权重矩阵W_Q, W_K, W_V,
W_O(也可以选择其中部分)。A,B矩阵的秩r也时远远小于原始的权重大小。
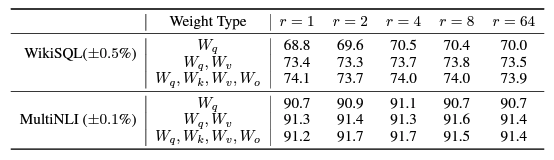
对于一般的任务,
r=1,2,4,8就足够了。而一些领域差距比较大的任务可能需要更大的r。
同时,增加r值变大并不能提升微调的效果,这可能是因为参数量增加需要更多的语料.
实现 huggingface: https://huggingface.co/docs/peft/main/conceptual_guides/lora llama_factory: https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/sft.html 关键参数: - lora_r:秩,控制低秩矩阵的表示能力。 - lora_alpha:缩放因子,控制 LoRA 的影响力。 - lora_dropout:dropout 概率,防止过拟合。 - lora_target_modules:指定微调的目标层。 - lora_trainable_only:是否只训练 LoRA 增加的部分。 - lora_init_scale:控制低秩矩阵初始化的尺度。 - lora_layers_to_freeze:指定冻结哪些层。 - lora_lr:设置 LoRA 的学习率。 - lora_warmup_steps:指定热身阶段的步数。
QLoRA
QLoRA(Quantized Low-Rank Adapter)是一种高效的微调方法,是 LoRA 的量化版本(什么是 LoRA?)。该调优方法由华盛顿大学发表于论文《QLORA: Efficient Finetuning of Quantized LLMs》。通过降低内存使用,实现在单个 GPU 上对大型语言模型进行微调。它可以在单个 48GB GPU 上微调 650 亿个参数的模型,并且能够保持完整的 1 6 位微调任务性能。
QLoRA 核心是使用量化进行微调。其成果有三个。 - 4 位标准浮点数量化(4-bit NormalFloat Quantization) - 双重量化(Double Quantization) - 分页优化(Paged Optimizer)就是显存不足时将部分梯度检查点转移到内存上。
为了降低极端的量化对微调造成的不利影响,QLoRA 借助 LoRA
对原模型权重进行更新,且 LoRA 侧的权重保持高精度。这就是 QLoRA
与 LoRA 的关系。  ### 基础知识 #### 量化
量化指的是将连续或高精度的数值转换为较低精度(比如较少的位数)的表示形式的过程。这通常用于减少模型的存储需求和加快其运算速度。例如,将一个
FP32 的 tensor 转成 Int8: \[X^{\text{Int8}} =
\text{round}\left(\frac{127}{\text{absmax}(X^{\text{FP32}})} \cdot
X^{\text{FP32}}\right)=round(c^{\text{FP32}} \cdot
X^{\text{FP32}})\]
### 基础知识 #### 量化
量化指的是将连续或高精度的数值转换为较低精度(比如较少的位数)的表示形式的过程。这通常用于减少模型的存储需求和加快其运算速度。例如,将一个
FP32 的 tensor 转成 Int8: \[X^{\text{Int8}} =
\text{round}\left(\frac{127}{\text{absmax}(X^{\text{FP32}})} \cdot
X^{\text{FP32}}\right)=round(c^{\text{FP32}} \cdot
X^{\text{FP32}})\]
其中,c 为量化常数,通常是这个张量的特征的绝对值的最大值。逆量化公式则为: \[\text{dequant}(c^{\text{FP32}}, X^{\text{Int8}}) = \frac{X^{\text{Int8}}}{c^{\text{FP32}}}\]
按照量化过程是否以0点为对称点量化又可以分为对称量化和非对称量化。其中对称量化将原浮点数的最小或最大值的绝对值作为映射值的范围,而非对称量化是将原浮点数的最小和最大值映射为量化数据的最小和最大值。在非对称量化中,0的映射也可能会有偏移,因此不一定会被映射到0。
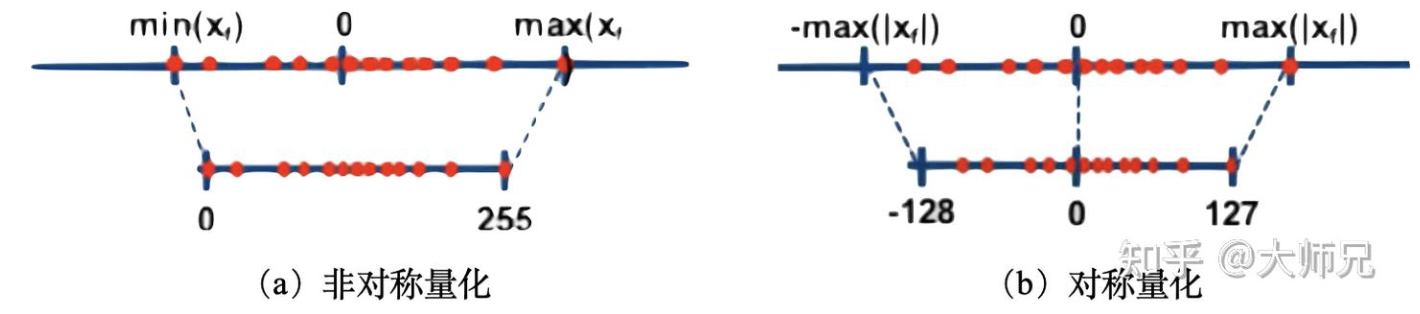
分位数量化
分位数量化(Quantile
Quantization)是隶属于非线性量化。分位数(Quantile)在数学上的定义指的是把顺序排列的一组数据分割为若干个相等块的分割点的数值。在标准正态分布中,对于分布X给定的概率\(\alpha\),如果存在\(\mu_\alpha\)使得它的累积分布函数(CDF)
\(P(X < \mu_\alpha)= \alpha\),则称
\(\mu_\alpha\)是标准正态分布的 \(\alpha\)分位数,因为CDF表示的是概率值小于\(\mu_\alpha\)的阴影部分的面积,因此具有严格递增的特性,所以它一定存在反函数。CDF的反函数的一个重要作用是用来生成服从该随机分布的随机变量。假设a是[0,1)区间上均匀分布的一个随机变量,那么
\(F_{X}^{-1}(a)\)服从分布\(X\)。 
分位数量化是通过分位数将张量分成了大小相同的若干个块,这样我们得到更加均匀的量化特征,对于4比特量化,我们希望需要找到15个分位数来将这个曲线下面的面积(积分)等分成16份。两个分位数的中点便是模型量化到这个区间映射的值
\(q_i\)。 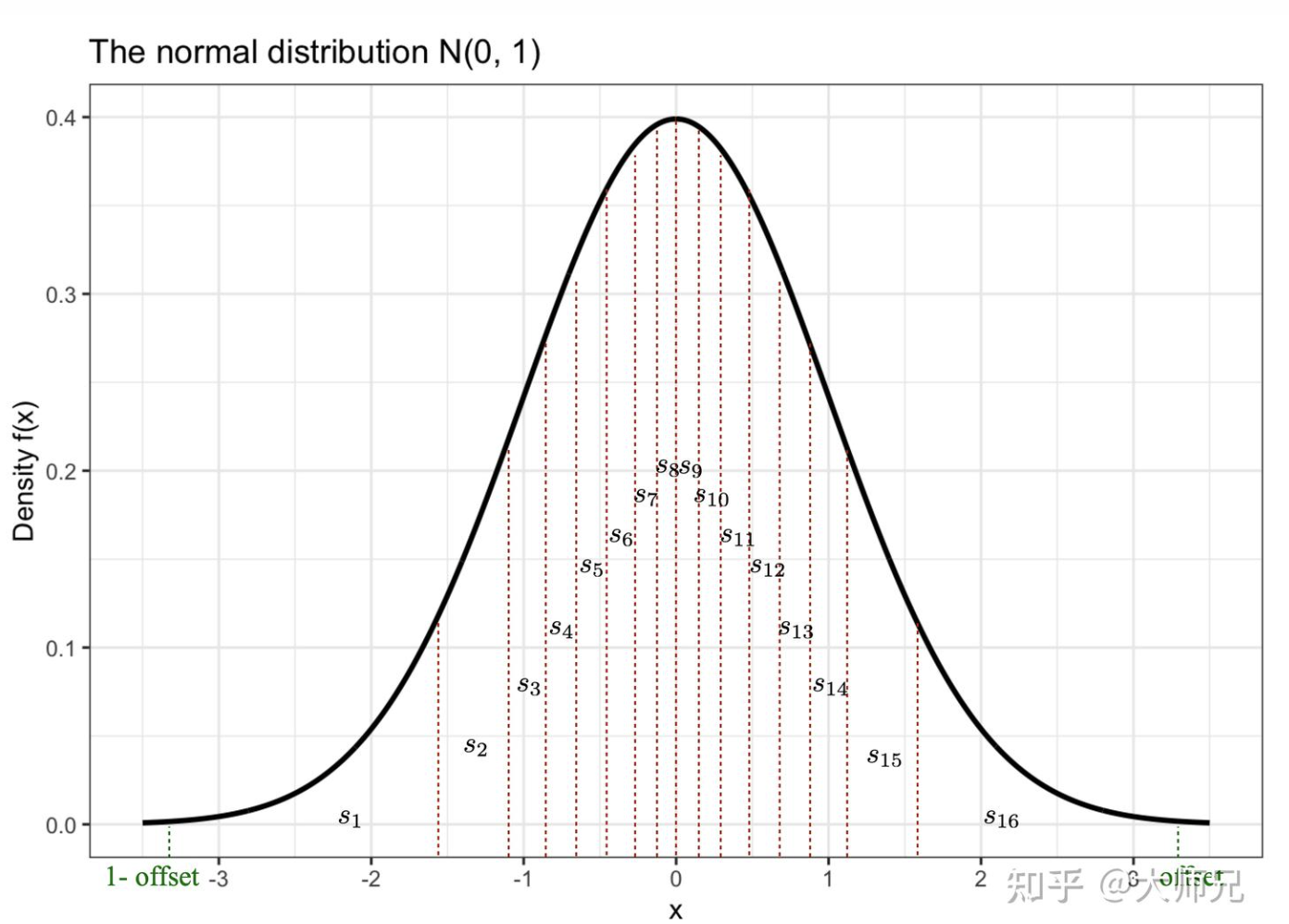
由于大模型参数通常服从正态分布,因此有:  其中\(Q\)是CSF的反函数。
其中\(Q\)是CSF的反函数。
分块k位量化
常规的量化方法的局限性是当 tensor 中有一个非常大的数字(一般称为 outlier)时,导致大多数值被压缩到较小的范围,精度损失大,影响最终的量化结果。
因此,Block-wise k-bit Quantization 方法就是把 tensor 分割成 B
块,每块有自己的量化常数
c,独自量化。从而解决模型参数的极大极小的异常值的问题。分块量化的另外一个好处是减少了核之间的通信,可以实现更好的并行性,并充分利用硬件的多核的能力。
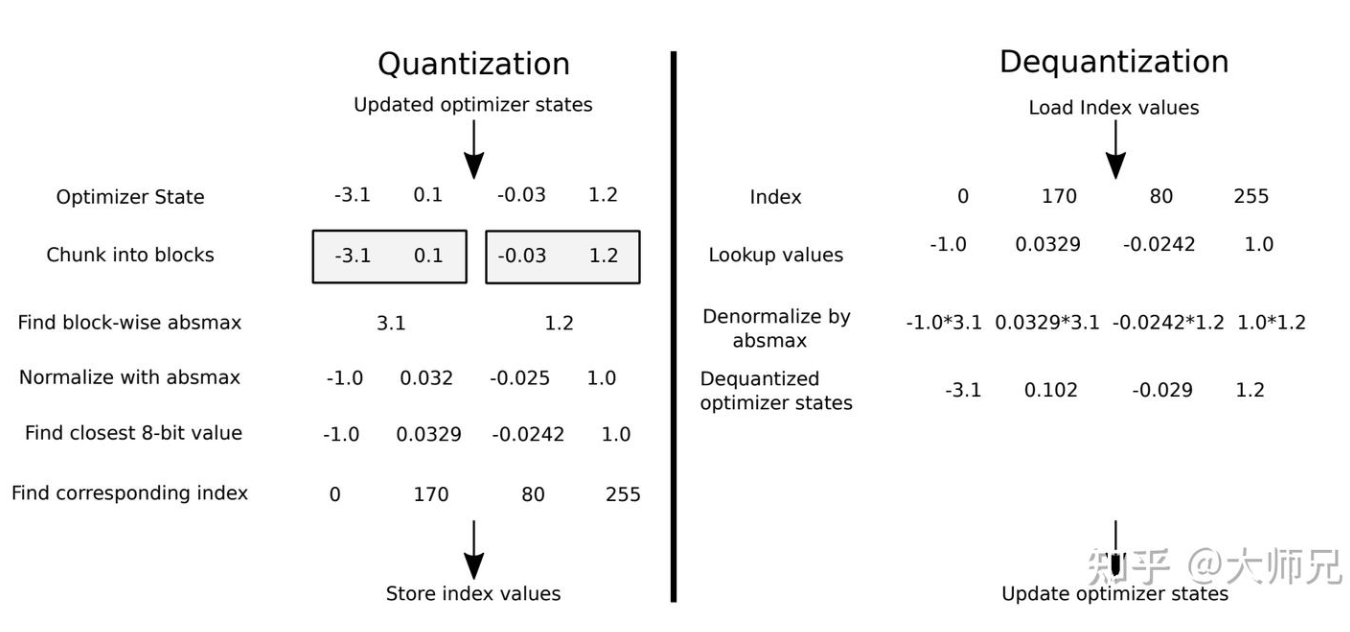
4位标准浮点量化---NF4
4-bit NormlFLoat 量化是结合了分位数量化和分块量化, 使用上面介绍的分位数量化方法我们可以将FP2精度量化到4bit的精度,但是直接这么用的一个问题是不能保证高精度的0一定被映射到低精度的0,但是0点又是深度学习中一个重要的值,例如在模型稀疏化,数据padding的时候一般都是使用0来完成。
假设offset的值是0.99,我们可以通过下面的代码片段计算出它的16个 \(q_i\)。
offset = 0.99
num_bins = 16
quantile = norm.ppf(torch.linspace(1 - offset, offset, num_bins + 1)).tolist() # 将[1-offset,offset]区间等分为16份
tmp = [(quantile[1:][idx] + val) / 2 for idx, val in enumerate(quantile[:-1])] # 计算分位数
r_max, r_min = tmp[-1], tmp[0]
S = (r_max - r_min)/(1 - (-1))
Z = 1 - r_max / S
Q = [x/S + Z for x in tmp] # 分位数量化到[-1,1]
print (Q)
>>> Q = [-1.0, -0.680534899946304, -0.5217156169574965, -0.4015399993912077, -0.299784167882981, -0.20835410767681603, -0.12291223249970012, -0.040639059218818274, 0.04063881956774142, 0.12291199284862328, 0.20835391124150712, 0.2997839714476721, 0.40153976366883704, 0.5217154126647753, 0.6805348056573558, 1.0]这种方式的一个问题是0的映射值不是0,如果我们考虑奇数个bin,0是可以有个映射值但是却无法充分利用4比特的16位的信息。为了确保零点映射到0并且使用4位数据类型的全部16位,我们通过估计正负两个范围的分位数来创建一个非对称的数据类型:负数部分映射其中7位,正数部分映射8位,0占据1位,总共用满了4位数的16位。另外我们也可以使用对称的量化,其中正数和负数均使用7位,0占用2个位。我这里和论文介绍的略有不同,论文说的是正数部分取9个值,负数部分取8个值,不过它们都会取到0,所以合并时再去掉一个重复的0,这两个说法其实是一样的,只是实现方式略有差异。
接下来根据作者的源码来看下量化分位数如何计算的。其中核心代码片段摘抄如下。
from scipy.stats import norm
import torch
def create_normal_map(offset=0.9677083, use_extra_value=True, num_bins=16):
# INT8 : num_bins = 256
# INT4 : num_bins = 16
if use_extra_value:
# one more positive value, this is an asymmetric type
v1 = norm.ppf(torch.linspace(offset, 0.5, 9)[:-1]).tolist() # 正数部分
v2 = [0]*(num_bins-15) ## we have 15 non-zero values in this data type
v3 = (-norm.ppf(torch.linspace(offset, 0.5, 8)[:-1])).tolist() #负数部分
v = v1 + v2 + v3
else:
v1 = norm.ppf(torch.linspace(offset, 0.5, 8)[:-1]).tolist()
v2 = [0]*(num_bins-14) ## we have 14 non-zero values in this data type
v3 = (-norm.ppf(torch.linspace(offset, 0.5, 8)[:-1])).tolist()
v = v1 + v2 + v3
values = torch.Tensor(v)
values = values.sort().values
values /= values.max()
assert values.numel() == num_bins
return values
Q = create_normal_map()
>>> Q = [-1.0, -0.6961928009986877, -0.5250730514526367, -0.39491748809814453, -0.28444138169288635, -0.18477343022823334, -0.09105003625154495, 0.0, 0.07958029955625534, 0.16093020141124725,0.24611230194568634, 0.33791524171829224, 0.44070982933044434, 0.5626170039176941, 0.7229568362236023, 1.0]
函数create_normal_map有两个入参:offset和use_extra_value。其中offset的作用是确定分位数的始末值。use_extra_value用来控制是使用对称量化还是非对称量化。v1计算正数部分,v3计算负数部分。v2直接将0映射到0,并且根据要量化的单位计算0的个数。源码是使用NF4来表示8比特的量化,如果是使用4比特的量化,我们将里面的256改成16就行。接下来最后几行用来将量化值归一化到[-1,1]。
接下来我们举一个具体的实例。假设一个张量有16个值,它的被分成了4块:
```python
input_blocked_tensor = [[-1.28645003578589, -1.817660483275528, 9.889441349505042, 0.010208034676132627],
[ -15.009014631551885, 1.4136255086268115, -7.815595761491153, 10.766760590950263],
[-0.731406153917959, 3.468224595908726, 2.445252541840315, -8.970824523299282],
[-9.641638854625175, 7.696158363188889, -5.323939281255154, 5.97160401402024]]c1 = max(|-1.28645003578589|, |-1.817660483275528|, |9.889441349505042|, |0.010208034676132627|) = 9.889441349505042
c2 = max(|-15.009014631551885|, |1.4136255086268115|, |-7.815595761491153|, |10.766760590950263|) = 15.009014631551885
c3 = max(|-0.731406153917959|, |3.468224595908726|, |2.445252541840315|, |-8.970824523299282|) = 8.970824523299282
c4 = max(|-9.641638854625175|, |7.696158363188889|, |-5.323939281255154|, |5.97160401402024|) = 9.641638854625175最后我们便可以计算这个张量的量化值了。例如第一个值-1.28645003578589,它除以这个块的量化常数c1后得到-0.13008318572517502,接下来我们要按照分位数的值来量化这个值。-0.13008318572517502在Q中最接近的值是-0.12291223249970012,这个值在Q中对应的索引是6,因此这个值被量化后的值是6。同理我们可以得到这个输入张量所有的值量化后的结果。在模型保存时,除了要保存量化后的值,我们还要保存每个块对应的量化常数c_i,因为这个值在我们进行反量化时需要用到。
[[6, 5, 15, 7],
[0, 8, 2, 14],
[6, 11, 10, 0],
[0, 14, 2, 13]][[-0.9004339933799617, -1.8273060011889755, 9.889441349505042, 0.0],
[-15.009014631551885, 1.1944218804231184, -7.880829111886221, 10.850869732860506],
[-0.816793898052648, 3.0313783372030603, 2.2078302737800004, -8.970824523299282],
[-9.641638854625175, 6.970488722350373, -5.062564734402345, 5.424549965245643]]双量化
在上面我们介绍到,当我们保存模型时我们不仅要保存量化后的结果,还要保存每个块的量化常数。虽然量化后的参数只有4bit的精度,但是这个量化常量的精度是float32。
**在QLoRA中,每个块的大小是64,块中的每个值占4比特。这相当于为了存储量化常数,模型要额外占用 32/(64*4)=12.5% 的显存。**
QLoRA的双重量化就是对这个量化常数再做一次8bit的量化,在进行量化常数的量化时,QLoRA以每256个量化常数为一组再做一次量化。因此它额外增加的内存消耗有两部分组成,一部分是量化后的8bit的第一层的量化常数,它额外增加的显存占比是 8/(64x4)= 3.125%, 第二部分是为量化常数做量化的第二层的32bit的量化常数,它额外增加的显存占比是32/(256x64x4)= 0.049%,额外显存增加只有3.17%。
分页优化器
分页优化是针对梯度检查点做的进一步优化,以防止在显存使用峰值时发生显存OOM的问题。QLoRA分页优化其实就是当显存不足是,将保存的部分梯度检查点转移到CPU内存上,和计算机的内存数据转移到硬盘上的常规内存分页一个道理。
实现
要使用 HuggingFace 进行 QLoRA 微调,您需要安装BitsandBytes 库和 PEFT 库。BitsandBytes 库负责 4 位量化以及整个低精度存储和高精度计算部分。PEFT 库将用于 LoRA 微调部分。
import torch
from peft import prepare_model_for_kbit_training, LoraConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "EleutherAI/gpt-neox-20b"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
) # setup bits and bytes config
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config, device_map={"":0})
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model) # prepares the whole model for kbit training
config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["query_key_value"],
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, config) # Now you get a model ready for QLoRA trainingbnb_4bit_compute_dtype,以减少由于低精度存储引起的累积误差。
参考资料: > https://arxiv.org/pdf/2106.09685
https://arxiv.org/abs/2305.14314
https://zhuanlan.zhihu.com/p/623543497
https://mingchao.wang/ShYWOOwr/
https://zhuanlan.zhihu.com/p/690739797
https://zhuanlan.zhihu.com/p/666234324



