前言
在传统的自注意力机制中,注意力矩阵的计算复杂度为 O(N²),其中 N 是序列的长度。对于长序列的输入(如文本或图像中的像素点),这种计算代价极高,特别是在训练大型语言模型或视觉模型时,内存占用和计算开销随着序列长度的增加而急剧上升。此外,注意力矩阵的大小为 N×N,这也对 GPU 内存消耗极大。自注意力机制不仅在计算时消耗大量内存,还需要存储所有中间变量(如 Q、K、V 矩阵及注意力权重),以支持后续的反向传播。
因此,找到有效降低 Transformer 模型 O(N²) 复杂度的方案至关重要。理想情况下,若能将复杂度降至 O(N),将大大提升模型效率。即使无法完全实现 O(N),逼近这一复杂度也是十分有价值的。在这一背景下,Flash Attention 应运而生,成为解决该问题的有效方案。
从 Flash Attention(Fast and Memory Efficient Exact Attention with IO-Awareness)的命名可见其优势:
- Fast:在Flash Attention之前,也出现过一些加速Transformer计算的方法,这些方法的着眼点是“减少计算量FLOPs”,例如用一个稀疏attention做近似计算。而FlashAttention发现:计算慢的卡点不在运算能力,而是在读写速度上。 所以它通过降低对显存(HBM)的访问次数来加快整体运算速度,这种方法又被称为O-Awareness。
- Memory Efficient:在 Flash Attention 中,内存使用压力从 O(N²) 降至 O(N),显著节省内存。
- Exact Attention:与稀疏 Attention 不同,Flash Attention 完全等效于标准 Attention。
背景知识
计算限制与内存限制
受限原因分析
首先介绍几个关键概念:
- \(\pi\):硬件算力上限,表示一个计算平台在全负荷情况下每秒能够执行的浮点运算次数,单位为 FLOPS(浮点运算次数每秒)。
- \(\beta\):硬件带宽上限,表示一个计算平台在全负荷情况下每秒能够完成的数据交换量,单位为 Byte/s。
- \(\pi_t\):某算法所需的总运算量,单位为 FLOPs。(t 表示 total)
- \(\beta_t\):某算法所需的总数据读取和存储量,单位为 Byte。
这里强调一下对FLOPS和FLOPs的解释:
FLOPS:等同于FLOP/s,表示Floating Point Operations Per Second,即每秒执行的浮点数操作次数,用于衡量硬件计算性能。
FLOPs:表示Floating Point Operations,表示某个算法的总计算量(即总浮点运算次数),用于衡量一个算法的复杂度。
在实际执行过程中,时间不仅消耗在计算上,也消耗在数据读取和存储上。因此,我们定义:
- \(T_{cal}\):算法执行所需的计算时间,其公式为\(\pi_t / \pi\)。
- \(T_{load}\):算法执行所需的数据读取与存储时间,公式为 \(\beta_t / \beta\)。
由于计算和数据传输可以同时进行,我们定义算法的总执行时间:\(T = max(T_{cal}, T_{load})\)
- 当 \(T_{cal}>T_{load}\) 时,算法的瓶颈在计算部分,称为计算限制(math-bound)。此时,\(\pi_t / \pi > \beta_t / \beta\),即 \(\pi_t/\beta_t > \pi/\beta\)。
- 当 \(T_{cal}<T_{load}\) 时,瓶颈在数据读取部分,称为内存限制(memory-bound)。此时,\(\pi_t / \pi < \beta_t / \beta\),即 \(\pi_t/\beta_t < \pi/\beta\)。
算法的计算强度(Operational Intensity)定义为 \(\pi_t/\beta_t\),表示每个数据读取操作对应的计算量。当算法的计算强度越高,说明计算部分的工作量越大,反之则说明数据读取部分的工作量越大。
假设我们现在采用的硬件为A100-40GB SXM,同时采用混合精度训练(可理解为训练过程中的计算和存储都是fp16形式的,一个元素占用2byte),则: \[ \pi/\beta = 312*10^{12} / 1555*10^9 = 201 FLOPs/Bytes \]
对于一个模型,\(Q, K \in \mathbb{R}^{n \times d}\),其中N为序列长度,d为embedding dim。现在计算\(S = QK^T\),则有: \[ \frac{\pi_t}{\beta_t} = \frac{2N^2d}{2Nd + 2Nd + 2N^2} = \frac{N^2d}{2Nd + N^2} \]
下表记录了不同的N,d下的受限类型: 
根据这个表格,我们可以来做下总结: - 计算限制(math-bound):大矩阵乘法(N和d都非常大)、通道数很大的卷积运算。相对而言,读得快,算得慢。 - 内存限制(memory-bound):逐点运算操作。例如:激活函数、dropout、mask、softmax、BN和LN。相对而言,算得快,读得慢。
所以,“Transformer计算受限于数据读取”也不是绝对的,要综合硬件本身和模型大小来综合判断。但从表中的结果我们可知,memory-bound的情况还是普遍存在的,所以Flash attention的改进思想在很多场景下依然适用。
在Flash attention中,计算注意力矩阵时的softmax计算就受到了内存限制,这也是flash attention的重点优化对象,我们会在下文来详细看这一点。
roof-line 模型
一个算法运行的效率是离不开硬件本身的。我们往往想知道:对于一个运算量为 \(\pi_t\),数据读取存储量为 \(\beta_t\) 的算法,它在算力上限为 \(\pi\),带宽上限为 \(\beta\) 的硬件上,能达到的最大性能 \(P\)(Attanable Performance)是多少?
这里最大性能 \(P\) 指的是当前算法实际运行在硬件上时,每秒最多能达到的计算次数,单位是FLOP/s。
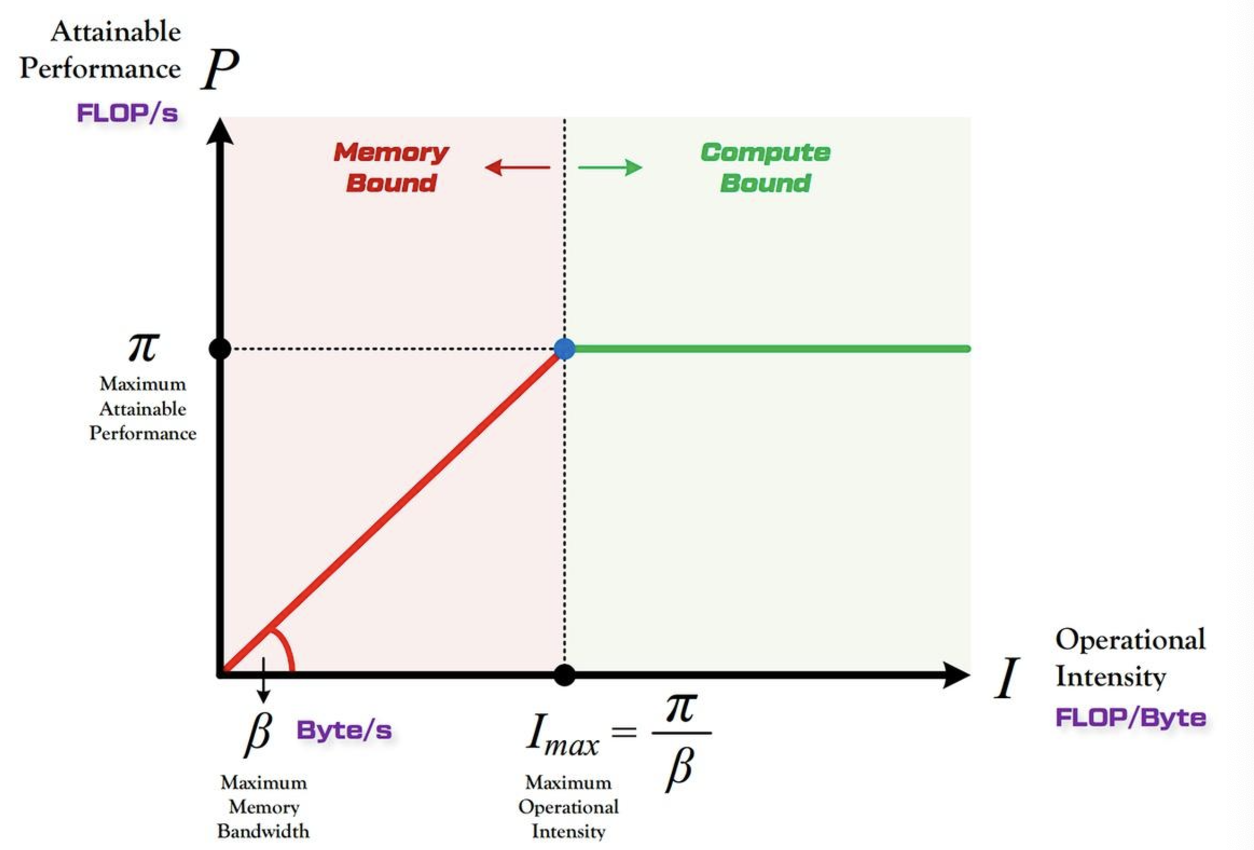
从图中可以直观的看出,当计算强度达到了硬件的上限时,算法的性能达到最大值。而在之前的计算强度范围内,都属于内存限制。
GPU存储与计算
GPU存储分类
通常,GPU 存储分为片上内存(on-chip memory)和片下内存(off-chip
memory),这主要取决于存储单元是否位于芯片内部。 
- 片上内存:用于缓存等,容量小但带宽极高。如上图中的 SRAM,容量仅 20MB,带宽却达 19TB/s。
- 片下内存:用于全局存储(即显存),容量大但带宽相对较小。如 HBM,容量可达 40GB,带宽为 1.5TB/s。
GPU的计算
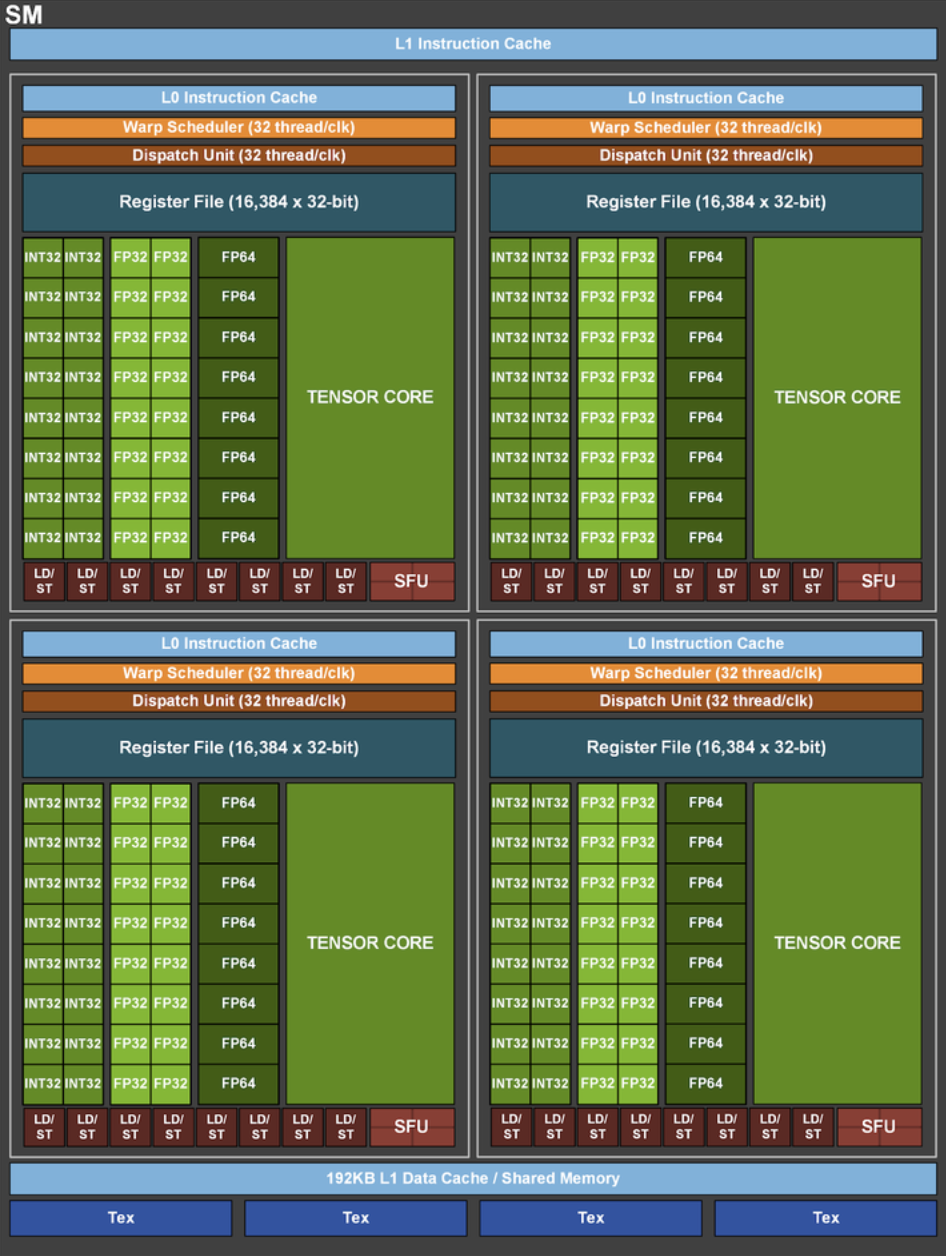 如图,负责GPU计算的一个核心组件叫SM(Streaming
Multiprocessors,流式多处理器),可以将其理解成GPU的计算单元,一个SM又可以由若干个SMP(SM
Partition)组成,例如图中就由4个SMP组成。SM就好比CPU中的一个核,但不同的是一个CPU核一般运行一个线程,但是一个SM却可以运行多个轻量级线程(由Warp
Scheduler控制,一个Warp Scheduler会抓一束线程(32个)放入cuda
core(图中绿色小块)中进行计算)。
如图,负责GPU计算的一个核心组件叫SM(Streaming
Multiprocessors,流式多处理器),可以将其理解成GPU的计算单元,一个SM又可以由若干个SMP(SM
Partition)组成,例如图中就由4个SMP组成。SM就好比CPU中的一个核,但不同的是一个CPU核一般运行一个线程,但是一个SM却可以运行多个轻量级线程(由Warp
Scheduler控制,一个Warp Scheduler会抓一束线程(32个)放入cuda
core(图中绿色小块)中进行计算)。
现在,我们将GPU的计算核心SM及不同层级GPU存储结构综合起来,绘制一张简化图:
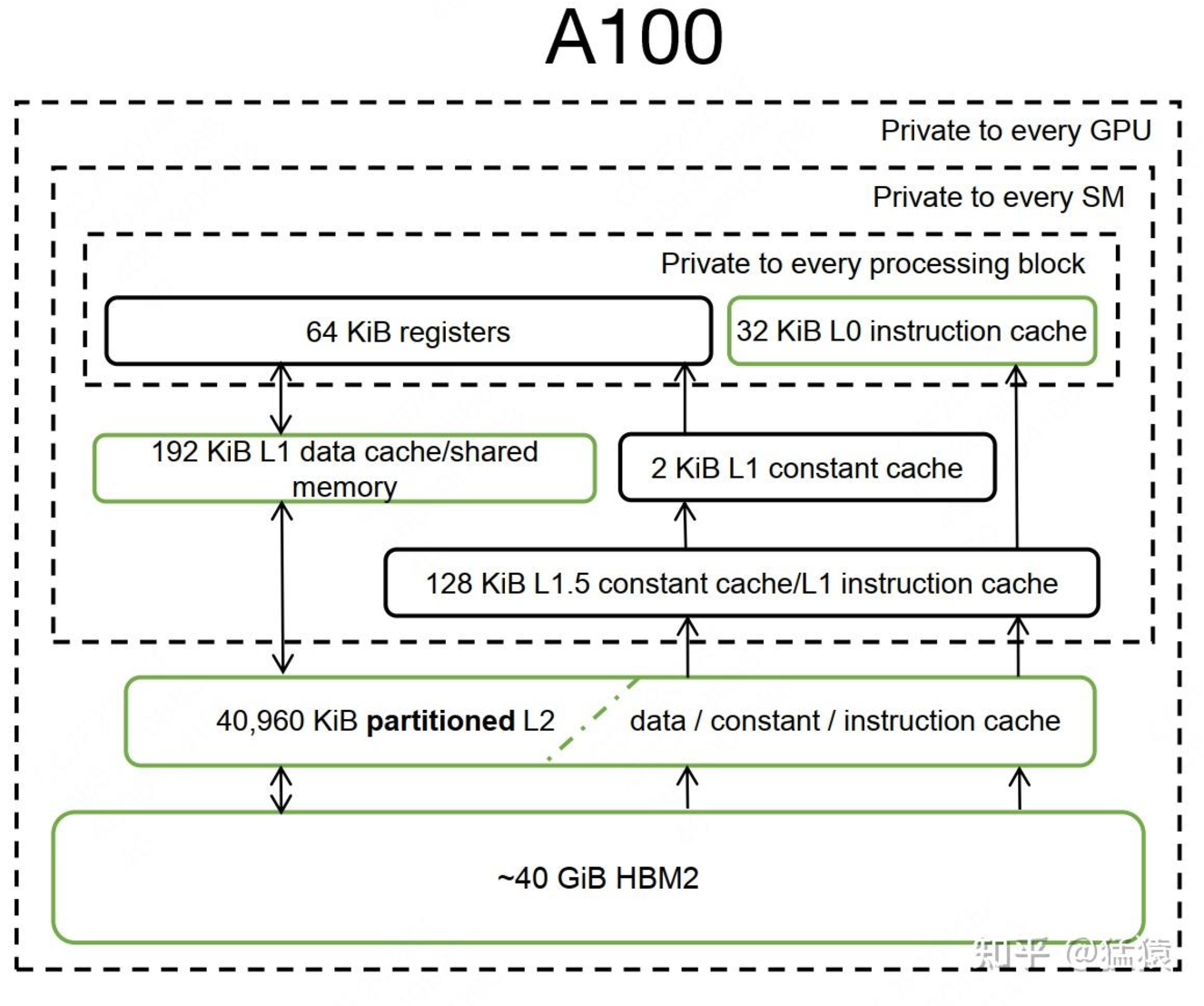 - HBM2:即是我们的显存。 - L1缓存/shared
memory:每个SM都有自己的L1缓存,用于存储SM内的数据,被SM内所有的cuda
cores共享。SM间不能互相访问彼此的L1。NV Volta架构后,L1和shared
memory合并(Volta架构前只有Kepler做过合并),目的是为了进一步降低延迟。合并过后,用户能写代码直接控制的依然是shared
memory,同时可控制从L1中分配多少存储给shared memory。Flash
attention中SRAM指的就是L1 cache/shared memory。 -
L2缓存:所有SM共享L2缓存。L2缓存不直接由用户代码控制。L1/L2缓存的带宽都要比显存的带宽要大,也就是读写速度更快,但是它们的存储量更小。
- HBM2:即是我们的显存。 - L1缓存/shared
memory:每个SM都有自己的L1缓存,用于存储SM内的数据,被SM内所有的cuda
cores共享。SM间不能互相访问彼此的L1。NV Volta架构后,L1和shared
memory合并(Volta架构前只有Kepler做过合并),目的是为了进一步降低延迟。合并过后,用户能写代码直接控制的依然是shared
memory,同时可控制从L1中分配多少存储给shared memory。Flash
attention中SRAM指的就是L1 cache/shared memory。 -
L2缓存:所有SM共享L2缓存。L2缓存不直接由用户代码控制。L1/L2缓存的带宽都要比显存的带宽要大,也就是读写速度更快,但是它们的存储量更小。
GPU 的计算流程可以理解为:数据从显存(HBM)加载到片上内存(SRAM),由 SM(Streaming Multiprocessor)读取并进行计算,计算结果再通过 SRAM 返回显存。具体可参考:NVIDIA GPU 原理详解。
显存带宽远低于 SRAM,因此从显存读取数据往往较耗时。为了优化读取效率,我们会尽量将数据填满 SRAM,从而减少频繁读取。
kernel fusion
为减少显存读取次数,若 SRAM 容量允许,多个计算步骤可合并在一次数据加载中完成。这被称为kernel 融合。
举例来说,我现在要做计算A和计算B。在老方法里,我做完A后得到一个中间结果,写回显存,然后再从显存中把这个结果加载到SRAM,做计算B。但是现在我发现SRAM完全有能力存下我的中间结果,那我就可以把A和B放在一起做了,这样就能节省很多读取时间,我们管这样的操作叫kernel融合。
对于kernel可以粗犷地理解成是“函数”,它包含对线程结构(grid-block-thread)的定义,以及结构中具体计算逻辑的定义。理解到这一层已不妨碍我们对flash attention的解读了,想要更近一步了解的朋友,推荐阅读这篇小小将:CUDA编程入门极简教程。
标准Attention计算
 其中, \(S=QK^T,
P=softmax(S)\)。在GPT类的模型中,还需要对\(P\)做mask处理。为了表达方便,诸如mask、dropout之类的操作,我们都忽略掉,下文也是同理。
其中, \(S=QK^T,
P=softmax(S)\)。在GPT类的模型中,还需要对\(P\)做mask处理。为了表达方便,诸如mask、dropout之类的操作,我们都忽略掉,下文也是同理。
标准safe softmax
在\(softmax(x_i) = \frac{e^{x_i}}{\sum_{j=1}^d e^{x_j}}\)的计算中,如果\(x_i\)的值很大,那么\(e^{x_i}\)会变得非常大,这样就会导致数值溢出。为了解决这个问题,我们可以对\(x_i\)做一个平移,即\(x_i - max(x)\),这样就能保证\(e^{x_i}\)不会溢出。
下图展示了safe softmax的过程,这里 \(\tilde{P}, P\)
分别表示平移前后的softmax结果。 
Flash Attention
Flash Attention的核心思想
- 分块计算:将输入矩阵划分为小块,并逐块在 SRAM 上计算注意力,避免将整个 N×N 矩阵存储于显存。
- 重计算:通过前向传播时保存归一化因子,避免在反向传播中存储中间结果,而是通过重计算得出注意力矩阵。这虽然增加了浮点运算次数,但通过减少 HBM 访问,提升了整体效率。
前向计算
分块计算tiling
我们先来了解分块计算的整体流程(帮助大家理解数据块是怎么流转的),然后我们再针对其中的细节做一一讲解。

在计算这些分块时,GPU是可以做并行计算的,这也提升了计算效率。
好!现在你已经知道了单块的计算方式,现在让我们把整个流程流转起来把。在上图中,我们注明了 j 是外循环, i 是内循环,在论文里,又称为K,V是外循环,Q是内循环。写成代码就是:
# ---------------------
# Tc: K和V的分块数
# Tr: Q的分块数量
# ---------------------
for 1 <= j <= Tc:
for 1 <= i <= Tr:
do....

这里的 \(O\) 还需要经过一定的处理,才能和不分块场景下的 \(O\)完全等价。这里我们将每一块的 \(O\) 单独画出,是为了帮助大家更好理解分块计算的整体流程,不代表它是最终的输出结果。
tiliing中的safe softmax
回顾之前绘制的标准safe softmax流程图,我们知道
m、l都是针对完整的一行做rowmax、rowsum后的结果,那么在分块场景下,会变成什么样呢?
 以上图红圈内的数据为例,在标准场景下,我们是对红圈内的每一行做rowmax、rowsum后得到
\(\tilde{P}\)的。而分块后这部分数据会被分到不同的块中。
以上图红圈内的数据为例,在标准场景下,我们是对红圈内的每一行做rowmax、rowsum后得到
\(\tilde{P}\)的。而分块后这部分数据会被分到不同的块中。
所以Flash Attention中采用如下方式实现safe softmax:
我们假设标准场景下,\(S\) 矩阵某一行的向量为 \(x = [x_1, x_2, \dots, x_d]\),因为分块的原因, 它被我们切成了两部分 \(x = \begin{bmatrix} x^{(1)}, x^{(2)} \end{bmatrix}\)。
我们定义:
- \(m(x)\):标准场景下,该行的全局最大值
- \(m(x^{(1)})\):分块1的全局最大值
- \(m(x^{(2)})\):分块2的全局最大值
那么易知: \(m(x) = m\left( \begin{bmatrix} x^{(1)}, x^{(2)} \end{bmatrix} \right) = \max \left( m(x^{(1)}), m(x^{(2)}) \right)\)
- 我们定义:
- \(f(x)\):标准场景下,\(\exp(x - m(x))\) 的结果
- \(f(x^{(1)})\):分块场景下,\(\exp(x^{(1)} - m(x^{(1)}))\) 的结果
- \(f(x^{(2)})\):分块场景下,\(\exp(x^{(2)} - m(x^{(2)}))\) 的结果
那么易知:\(f(x) = \left[ e^{m(x^{(1)}) - m(x)} f(x^{(1)}), e^{m(x^{(2)}) - m(x)} f(x^{(2)}) \right]\)
这个很好理解,详细的证明过程就不写了。
- 我们定义:
- \(l(x)\):标准场景下,\(\text{rowsum}[f(x)]\) 的结果
- \(l(x^{(1)})\):分块场景下,\(\text{rowsum}[f(x^{(1)})]\) 的结果
- \(l(x^{(2)})\):分块场景下,\(\text{rowsum}[f(x^{(2)})]\) 的结果
那么由(3)易知:\(l(x) = e^{m(x^{(1)}) - m(x)} l(x^{(1)}) + e^{m(x^{(2)}) - m(x)} l(x^{(2)})\)
- 现在,我们就可以用分块计算的结果,来表示标准场景下 safe softmax 的结果了: \[softmax(x) = \frac{f(x)}{l(x)} = \frac{\left[e^{m(x^{(1)}) - m(x)} f(x^{(1)}), e^{m(x^{(2)}) - m(x)} f(x^{(2)})\right]}{e^{m(x^{(1)}) - m(x)} l(x^{(1)}) + e^{m(x^{(2)}) - m(x)} l(x^{(2)})}\]
我们配合上面的图例和flash attention论文中的伪代码,再来进一步理解一下分块计算safe softmax的(1)~(5)步骤。

我们用 \(S_{00}\)(图中浅绿色方块)替换掉(1)\(\sim\)(5)步骤中的 \(x^{(1)}\),用 \(S_{01}\)(图中深绿色方块)替换掉 \(x^{(2)}\)。我们关注点在伪代码部分的 6 \(\sim\) 11 行。
由于伪代码中的表达符号较多,容易阻碍大家的理解,因此我们先明确各个数学符号表达的含义:
- \(S_{ij}\):对应在我们的例子里,就是 \(S_{00}\) 和 \(S_{01}\),即 \(Q_i K_j^\top\) 的结果。
- \(m_{ij}\):对于当前分块 \(S_{ij}\) 来说,每行的局部最大值。相当于前面步骤(2)中对 \(m(x^{(1)})\), \(m(x^{(2)})\) 的定义。
- \(\tilde{P}_{ij}\):分块场景下,各块的 \(p\) 矩阵(归一化前)结果。相当于步骤(3)中对 \(f(x^{(1)})\), \(f(x^{(2)})\) 的定义。
- \(l_{ij}\):分块场景下,\(\text{rowsum}\) 的结果。相当于步骤(4)中对 \(l(x^{(1)})\), \(l(x^{(2)})\) 的定义。
- \(m\):标准场景下,对 \(S\) 矩阵而言,每行的最大值,这里是全局最大值(\(m\) 首次定义在伪代码第 2 行),相当于前面步骤(2)中对 \(m(x)\) 的定义。
- \(l\):标准场景下,全局 \(\text{rowsum}\) 的结果(\(l\) 首次定义在伪代码第 2 行),相当于前面步骤(4)中对 \(l(x)\) 的定义。
- \(m_i\):表示 \(\max(m_{i0}, m_{i1}, \dots, m_{i(j-1)})\)。如果当前分块是 \(S_{ij}\),则 \(m_i\) 表示固定 \(i\) 时,前 \(j - 1\) 个分块中的局部最大值。容易推出,当固定 \(i\),遍历完成 \(S_{00}, S_{01}\) 后,\(m_i\) 的结果就是全局最大值 \(m_0\)。
- \(m_i^{\text{new}}\):表示 \(\max(m_{i0}, m_{i1}, \dots, m_{i(j-1)}, m_{ij})\)。如果当前分块为 \(S_{ij}\),则 \(m_i^{\text{new}}\) 表示固定 \(i\) 时,截止到当前分块为止的局部最大值。
- \(l_i\):和 \(m_i^{\text{new}}\) 对应,相当于步骤(4)中用分块更新 \(l(x)\) 的步骤。
- \(l_i\):和 \(m_i\) 同理,即当我们将 \(j\) 遍历完后,我们就能得到针对 \(i\) 的全局 rowmax 和全局 rowsum。
而根据前面的定义,\(m_i^{\text{new}}\) 和 \(l_i^{\text{new}}\) 是遍历完成最新的 \(S_{ij}\) 后得到的 rowmax 和 rowsum 结果, 所以每遍历完一块 \(S_{ij}\),我们就执行伪代码的第 13 行,做一次更新。
从伪代码 5-13 行中,你会发现,在整个计算过程中,只有 \(m_i, l_i, O_i\) 被从 on-chip 的 SRAM 中写回到显存(HBM)中。 把 \(i\) 都遍历完成后,读写量也不过是 \(m, l, O\)。相比于标准场景下,我们要读写的是 \(S, P, O\),读写量是不是一下就少很多,这不就能解决 memory-bound 的问题了吗。
所以,分块计算 safe softmax 的意义,就是抹去对 \(S, P\) 的读写。
分块计算中的\(O\)
 上图中画的6个\(O\)并不是我们最终想要的结果。我们期望维护并更新
\(O_i\),当该 \(i\)下的所有 \(j\) 遍历完毕后,我们的 \(O_i\)就应该和标准场景下的 \(O_i\)完全相等。
上图中画的6个\(O\)并不是我们最终想要的结果。我们期望维护并更新
\(O_i\),当该 \(i\)下的所有 \(j\) 遍历完毕后,我们的 \(O_i\)就应该和标准场景下的 \(O_i\)完全相等。
在图中,\(O_i\)应该是红圈部分的乘积,但是我们只存了\(m_i, l_i, O\),但是没有存\(S, P\),所以到了最后一块我们也无法计算出\(O_i\)。
所以这里我们换个思路: \(O_i\)不是每遍历一块就更新一次吗?那有没有一种办法,不断用当前最新的rowmax和rowsum去更新 \(O_i\),直到遍历完最后一块,这时的 \(O_i\)不就和标准场景下的结果完全一致了吗?也就是我们想构造形如下面这样的更新等式: \[ O_i = O_i + 当前最新结果 \]
因此我们有了伪代码中12行的推导: $$ \begin{aligned} O_i^{(j+1)} &= P_{i, j+1} V_{:j+1} \\ &= \text{softmax}(S_{i, :j+1}) V_{:j+1} \\ &= \text{diag}(l^{(j+1)})^{-1} \left[ \exp\left([S_{i, :j}, S_{i(j+1)}] - m^{(j+1)}\right) \right] \begin{bmatrix} V_{:j} \\ V_{j+1} \end{bmatrix} \\ &= \text{diag}(l^{(j+1)})^{-1} \left[\exp(S_{i, :j} - m^{(j+1)})V_{:j} + \exp(S_{i(j+1)} - m^{(j+1)})V_{j+1}\right] \\ &= \text{diag}(l^{(j+1)})^{-1} \left[\exp(S_{i, :j} - m^{(j)})V_{:j} + e^{-m^{(j+1)}}\exp(S_{i(j+1)})V_{j+1}\right] \\ &= \text{diag}(l^{(j+1)})^{-1} \left[\text{diag}(l^{(j)})e^{m^{(j)} - m^{(j+1)}}O_i^{(j)} + e^{-m^{(j+1)}}\exp(S_{i(j+1)})V_{j+1}\right] \\ &= \text{diag}(l^{(j+1)})^{-1} \left[\text{diag}(l^{(j)})e^{m^{(j)} - m^{(j+1)}}O_i^{(j)} + e^{m^{(j)} - m^{(j+1)}} \tilde{P}_{i(j+1)} V_{j+1}\right] \end{aligned} $$
推导过程中的符号上下标的含义: - \(i\):这个大家应该很熟悉了。例如图例中,\(i=0, 1, 2\) 分别对应着深浅绿、深浅蓝、深浅黄块。 - \((j+1)\):表示当前分块的相关结果。 - \(i, :j+1\):表示截止到当前分块(包含当前分块)的相关结果。\(i, :j\) 表示截止到前一分块(包含前一分块)的相关结果。
后向计算
softmax的求导
设 \[ \begin{cases} y = \text{softmax}(z) \\ L = f(y) \end{cases} \]
其中,\(L\) 表示 Loss,\(f(\cdot)\) 表示 Loss 函数,\(y = [y_1 \; y_2 \; y_3]\),\(z = [z_1 \; z_2 \; z_3]\),若现在我们想求 \(\frac{\partial L}{\partial z_j}\),要怎么计算呢?
根据链式法则,我们有: \[ \frac{\partial L}{\partial z_j} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial z_j} \] 所以我们分别来看这两项。
\(\frac{\partial L}{\partial y}\) 我们现在不考虑具体的 Loss 函数,直接假设这一项的结果为 \([m_1 \; m_2 \; m_3]\)。
\(\frac{\partial y}{\partial z_j}\) 我们知道,对于某个 \(z_j\) 来说,在 \(\text{softmax}\) 的操作下,它参与了 \(y_1, y_2, y_3\) 三者的计算, 因此它的偏导和这三者密切切相关,这里我们分成两种情况: \[ \begin{cases} \frac{\partial y_i}{\partial z_j} = y_i (1 - y_i), & \text{当 } i = j \\ \frac{\partial y_i}{\partial z_j} = -y_i y_j, & \text{当 } i \neq j \end{cases} \]
具体的推倒过程可以看这篇文章:对 softmax 和 cross-entropy 求导
有了这个理解,我们再来谈谈基于 \(y = softmax(z)\) 的 Jacobian 矩阵 \(diag(y) - y^T y\):
$$ \begin{aligned} diag(y) - y^T y &= \begin{bmatrix} y_1 & 0 & 0 \\ 0 & y_2 & 0 \\ 0 & 0 & y_3 \end{bmatrix} - \begin{bmatrix} y_1 \\ y_2 \\ y_3 \end{bmatrix} * \begin{bmatrix} y_1 & y_2 & y_3 \end{bmatrix} \\ &= \begin{bmatrix} y_1 - y_1^2 & -y_1 y_2 & -y_1 y_3 \\ -y_2 y_1 & y_2 - y_2^2 & -y_2 y_3 \\ -y_3 y_1 & -y_3 y_2 & y_3 - y_3^2 \end{bmatrix} \end{aligned} $$很容易发现只要把每行/每列相加,就能得到对应 \(z\) 的偏导。别着急求和,我们继续往下看。
- $ = $
有了 (1) (2) 的结果,现在就可以来推导 \(\frac{\partial L}{\partial z_j}\),我们有: \[ \frac{\partial L}{\partial z_j} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial z_j} = \sum_{i=1}^l \frac{\partial L}{\partial y_i} \frac{\partial y_i}{\partial z_j} = y_j (d y_j - \sum_{j=1}^l y_j d y_j) \]
举个例子,若我们现在想求 \(\frac{\partial L}{\partial z_1}\),我们将 \(\frac{\partial L}{\partial y} = [m_1 \; m_2 \; m_3]\) 代入上面公式,则有:
\[ \frac{\partial L}{\partial z_1} = m_1 (y_1 - y_1^2) - m_2 y_1 y_2 - m_3 y_1 y_3 \]
现在,针对所有的 \(z\),我们将 \(\frac{\partial L}{\partial z}\) 写成矩阵表达式有:
$$ \begin{aligned} \frac{\partial L}{\partial z} &= \frac{\partial L}{\partial y} \frac{\partial y}{\partial z} = dy(diag(y) - y^T y) \\ &= [m_1 \; m_2 \; m_3] \begin{bmatrix} y_1 & 0 & 0 \\ 0 & y_2 & 0 \\ 0 & 0 & y_3 \end{bmatrix} - \begin{bmatrix} y_1 \\ y_2 \\ y_3 \end{bmatrix} \begin{bmatrix} y_1 & y_2 & y_3 \end{bmatrix} \\ &= [m_1 \; m_2 \; m_3] \begin{bmatrix} y_1 - y_1^2 & -y_1 y_2 & -y_1 y_3 \\ -y_2 y_1 & y_2 - y_2^2 & -y_2 y_3 \\ -y_3 y_1 & -y_3 y_2 & y_3 - y_3^2 \end{bmatrix} \end{aligned} $$至此,大家记住这两个重要的结论:
\[ \frac{\partial L}{\partial z} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial z} = dy(diag(y) - y^T y) \]
\[ \frac{\partial L}{\partial z_j} = y_j \left( dy_j - \sum_{j=1}^l y_j dy_j \right) \]
标准后向计算
 首先我们先回顾一下标准前向过程: \[
S = QK^T
\]
首先我们先回顾一下标准前向过程: \[
S = QK^T
\]
\[ P = \text{softmax}(S) \]
\[ O = PV \]
\[ L = f(O) \]
对于标准backward来说,在计算开始时,显存(HBM)上已经存放有\(Q, K, V, O, S, P\)这些数据。
分块后向计算
首先回顾一下经过分块 Forward 计算后,显存(HBM)上都存了哪些数据:
- \(m\):全局 rowmax
- \(l\):全局 rowsum
- \(Q, K, V\):等同于标准 attention 场景下的结果
- \(O\):等同于标准 attention 场景下的输出结果 \(O\)
- \(dO\):有了完整的 \(O\),我们就可以按正常的 backward 步骤先求出它的梯度,也存放在显存上。 然后我们就能按照链式法则,分块地去求列的矩阵的梯度了。
既然有了全局的 \(m, l\),那么现在对任意一块 \(S_{ij}\),我们就能基于 \(m, l\) 算出和标准场景下完全一致的 \(P_{ij}\) 了。 因此,在 backward 的过程中,flash attention 将采用重计算的方式,重新算出 \(S_{ij}, P_{ij}\), 并将它们运用到 backward 的计算中去,所以在接下来的讲解中,大家就可以把 \(S, P\) 理解成完全等同于标准场景下的结果, 而不是像分块计算 forward 中那样的 \(S, P\)。

- 求 \(V_j\) 梯度
由 Forward 过程我们知:\(O = PV\),因此有了 \(dO\) 后,我们就可以先来求 \(dP\) 和 \(dV\) 了。 观察下方的图,我们会发现此时所有的 \(P\) 都是不带波浪号的,再强调一下,这是因为经过了重计算, 此处 \(S, P\) 的结果都等同于标准场景下的结果,而不是 forward 中所代表的含义。

假设现在 \(j = 0\),那我们要怎么求 \(dV_0\) 呢?
我们先来看 \(V_0\) 都参与了 \(O\) 哪些部分的计算,以及是怎么参与的:由图可知,\(P_{00}\) 和 \(V_0\) 参与了 \(O_0\) 的计算, \(P_{10}\) 和 \(V_0\) 参与了 \(O_1\) 的计算,\(P_{20}\) 和 \(V_0\) 参与了 \(O_2\) 的计算。所以我们有:
\[ dV_0 = (P_{00})^T dO_0 + (P_{10})^T dO_1 + (P_{20})^T dO_2 \]
进而推知: \[ dV_j = \sum_i (P_{ij})^T dO_i \]
在伪代码 11~15 行中,做的都是 \(S, P\) 重计算的过程,伪代码的第 16 行, 就是在按这个方法分块计算并累积 \(dV_j\)。
- 求 \(P_{ij}\) 梯度

观察上图,可以发现 \(P_{ij}\) 只与 \(V_j, O_i\) 相关,例如 \(P_{10}\) 只与 \(V_0, O_1\) 相关。因此我们有:
\[ dP_{ij} = dO_i V_j^T \]
这就是伪代码第 17 行做的事情。
- 求 \(S_{ij}\) 梯度
这一块是令许多人感到迷惑的,我们先来回顾下 “softmax 求导” 部分让大家记住的一个重要结论:
\[ \frac{\partial L}{\partial z} = \frac{\partial L}{\partial y} \frac{\partial y}{\partial z} = dy(diag(y) - y^T y) \]
我们假设 \(s_i, p_i, o_i\) 分别为矩阵 \(S, P, O\) 的某一行(注意这里 \(i\) 不是表示第 \(i\) 块的意思,是表示第 \(i\) 行,所以我们用小写的 \(s, p, o\) 表示),那么根据这个结论,我们有:
\[ \begin{aligned} ds_i &= dp_i \left( diag(p_i) - p_i^T p_i \right) \\ &= dp_i diag(p_i) - dp_i p_i^T p_i \\ &= dp_i diag(p_i) - dO_i V_j^T p_i \\ &= dp_i diag(p_i) - dO_i o_i^T p_i \\ &= p_i \circ \left[ dp_i - \text{rowsum}(dO_i \cdot o_i) \right] \end{aligned} \] 你可能对这个推导的最后一步有疑惑:为什么要大费周章,将 \(ds_i\) 改写成这么复杂的形式呢?因为在最后一步之前,我们都是针对“某一行”来求导,而引入最后一步的目的,是为了延展至对“某一块(多行)”的求导,也就是说针对某一块 \(dS_i\)(注意这里是大写的 \(S\),\(i\) 的含义也回归至“第几块”),我们有:
\[ dS_i = P_i \circ \left[dP_i - \text{rowsum}(dO_i \circ O_i)\right] \]
如果实在难以理解推导过程,建议大家可以带一些具体的值进去,就能理解我们为什么要写成这种形式了。进而,我们可以推知:
\[ dS_{ij} = P_{ij} \circ \left[dP_{ij} - \text{rowsum}(dO_i \circ O_i)\right] \]
这就是伪代码第 19~20 行做的事情。
- 求 \(Q_i\) 梯度

到目前为止,我们已经知道 \(dS_{ij}\),那么现在就可以根据链式法则继续求 \(dQ_i\) 了。
对照上图,我们把目光聚焦在 \(Q_0\) 身上,由 forward 过程可知:
\[ S_{00} = Q_0 K_0^T \]
\[ S_{01} = Q_0 K_1^T \]
因此,针对 \(Q_0\),我们有:
\[ dQ_0 = dS_{00} K_0 + dS_{01} K_1 \]
推广到任意 \(Q_i\),我们有:
\[ dQ_i = \sum_j dS_{ij} K_j \]
这就是伪代码第 21 行做的事情。
- 求 \(K_j\) 梯度

这一步就很简单啦,如果你被复杂的分块推导弄得晕了脑袋,那不妨再复习一下我们前面提过的 trick: 对照上图,取出某一块 \(K_j\)。由于我们是从 \(dS_{ij}\) 链式推向 \(K_j\),所以这里只要搞明白这块 \(K_j\) 和哪些 \(Q_i\) 一起计算出了哪些 \(S_{ij}\) 再把相关结果相加即可。
只要看了流程图,就不难得知:某块 \(K_j\) 和对应的 \(Q_i\) 共同计算出了对应的 \(S_{ij}\),因此有:
\[ dK_j = \sum_i dS_{ij}^T Q_i \]
这就是伪代码第 22 行做的事情。
计算量与显存占用
矩阵相乘的计算量
我们先来看一个前置知识:两个矩阵相乘,要怎么统计它们的计算量?
我们一般用FLOPs(floating point operations,浮点运算次数)来表示运算量的大小。对于“两矩阵相乘”这个操作而言,其 运算量 = 乘法运算的次数 + 加法运算的次数**。
来看一个具体例子:

两矩阵相乘,为了获取图中深橘色部分的元素,我们一共需要进行n次乘法运算和n-1次加法运算。
对于示例矩阵,我们需要进行:\(mp \cdot (n + n - 1)\) 次浮点计算。
再进一步,假设此时在蓝色和绿色的矩阵外,我们还有一个bias矩阵,意味着计算单个橘色方块时我们需要进行n次乘法和n-1+1次加法运算,那么此时总计算量为:\(mp \cdot (n+n) = 2mnp\)。当然,即使不加这个bias,我们也可以把-1项给忽略,得到相同的结果。
总结一下: - 假设有两个矩阵A和B,它们的维度分别为(m, n)和(n, p),则这两矩阵相乘的运算量为2mnp。 - 由于乘法运算的时间要高于加法运算的时间,因此有时在统计运算量时,我们只考虑乘法运算的次数,则此时两矩阵相乘的运算量可近似为mnp。
Flash Attention的计算量
我们知道矩阵相乘运算占据了运算量的大头,因此我们把分析目光集中到所有的矩阵运算上来。
在代码第 9 行,我们有 \(S_{ij} = Q_i K_j^T\),其中 \(Q_i \in \mathbb{R}^{B_r \times d}\),\(K_j^T \in \mathbb{R}^{d \times B_c}\)。根据前置知识,求 \(S_{ij}\) 的计算量为 \(O(B_r B_c d)\)。
在代码第 12 行,我们有 \(\tilde{P}_{ij} V_j\),其中 \(\tilde{P}_{ij} \in \mathbb{R}^{B_r \times B_c}\),\(V_j \in \mathbb{R}^{B_c \times d}\)。则这里的计算量同样为 \(O(B_r B_c d)\)。
接下来我们看一共计算了多少次 (1) 和 (2),也就是执行了多少次内循环:
\[ T_c T_r = \frac{N}{B_c} \cdot \frac{N}{B_r} \]
- 综合以上三点,flash attention 的 forward 计算量为:
\[ O\left(\frac{N^2}{B_r B_c} B_r B_c d \right) = O(N^2 d) \]
注意,因为计算量是用大 O 阶表示的,所以这里我们把常数项都省略了。
同理大家可以自行推一下 backward 中的计算量,在论文里给出的结论是 \(O(N^2)\),d 远小于 N,因此 d 也可以略去不表述。
Flash Attention的显存占用
和标准 attention 相比,如果不考虑 \(O\) 的话,Flash Attention 只需要存储 \(m, l\),其显存需求为 \(O(N)\)。
而标准 attention 需要存储 \(S, P\),其显存需求为 \(O(N^2)\)。
FlashAttention 将显存需求降低到 O(N),通过分块处理和重计算,显著减少了显存使用。实验显示,其显存消耗可减少至标准 Attention 的 1/20。
IO复杂度分析
flash attention相比于标准attention的最大优势,就是其减少了对显存(HBM)的访问次数,一定程度上解决了memory bound的问题。所以这一节我们就来具体分析这两者对显存的访问次数(同样都是以forward为例,backward部分论文中也有给出相关推导过程,大家可以类比forward自行阅读)。 ### 标准Attention的IO复杂度

- 从 HBM 中读取 \(Q, K \in
\mathbb{R}^{N \times d}\),计算 \(S = Q
K^T\),\(S \in \mathbb{R}^{N \times
N}\) 并将 \(S\) 写回
HBM。
- 一读一写的 IO 复杂度为:\(O(2Nd + N^2)\)。
- 从 HBM 中读取 \(S \in
\mathbb{R}^{N \times N}\),同时计算 \(P
\in \mathbb{R}^{N \times N}\) 并将其写回 HBM。
- 一读一写的 IO 复杂度为:\(O(2N^2)\)。
- 从 HBM 中读取 \(P \in
\mathbb{R}^{N \times N}, V \in \mathbb{R}^{N \times d}\),计算
\(O = P V, O \in \mathbb{R}^{N \times
d}\) 并将 \(O\) 写回
HBM。
- 两读一写的 IO 复杂度为:\(O((N^2 + Nd) + Nd)\)。
因此,总体来说标准 attention 的 IO 复杂度为:\(O(Nd + N^2)\)。
Flash Attention的IO复杂度
我们来看伪代码的第 6 行,在每个外循环中,我们都会加载 \(K, V\) 的 block。所有外循环结束后,相当于我们加载了完整的 \(K, V \in \mathbb{R}^{N \times d}\),因此这里的 IO 复杂度为:\(O(2Nd)\)。
再看伪代码第 8 行,在每个内循环中,我们都加载部分 \(Q, O, m, l\) block。由于 \(m, l\) 本身比较小(IO 复杂度是 \(O(N)\)),因此我们暂时忽略它们,只考虑 \(Q, O\)(原论文也是这么分析的)。 固定某个小循环,对于所有内循环结束后,我们相当于完整遍历了 \(Q, O \in \mathbb{R}^{N \times d}\)。同时我们经历了 \(T_c\) 次外循环。因此这里最终的 IO 复杂度为:\(O(T_c Nd)\)。
将 \(O, m, l\) 写回 HBM,这里近似后 IO 复杂度为:\(O(Nd)\)。
不过在原论文的分析中并没有考虑写回的复杂度,不过省略一些常数项不会影响我们最终的分析。
总体来说,flash attention 的 IO 复杂度为: \[ O(T_c Nd + Nd) = O\left(\frac{N}{B_c} Nd \right) = O\left(\frac{4Nd}{M} Nd \right) = O\left(N^2 d \frac{d}{M} \right) \] 在文章中提到,一般的 \(d\) 取值在 64~128,\(M\) 的取值在 100KB 左右,因此有 \(\frac{d^2}{M} \ll 1\)。因此可以看出,Flash Attention 的 IO 复杂度是显著小于标准 attention 的 IO 复杂度的。
复杂度总结

实验

Flash attention 的作者将 \(N = 1024\), \(d = 64\), \(B = 64\) 的 GPT2-medium 部署在 A100 GPU 上,来观察采用 flash attention 前后的模型的计算性能。
我们先看最左侧图表,标准 attention 下,计算强度 \(I = \frac{66.6}{40.3} \approx 1.6 < 201\),说明 GPT2 在 A100 上的训练是受到内存限制的。而在采用 flash attention 后得到明显改善,runtime 也呈现了显著下降。
我们再来看中间的图表,它表示在使用 flash attention 的前提下,以 forward 过程为例,每个数据块的大小对 HBM 读写次数(绿色)和耗时(蓝色)的影响。可以发现,数据块越大,读写次数越少,而随着读写次数的减少,runtime 也整体下降了(复习一下,读写复杂度为 \(O(T_c Nd)\),数据块越大意味着 \(T_c\) 越小)。但有趣的是,当数据块大小 \(> 256\) 后,runtime 的下降不明显了,这是因为随着矩阵的变大,计算耗时也更大了,会抵平读写节省下来的时间。
参考资料 > 图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑:https://zhuanlan.zhihu.com/p/669926191 > 图解大模型计算加速系列:Flash Attention V2,从原理到并行计算:https://zhuanlan.zhihu.com/p/691067658



