前言
Huggingface的transformers库是NLP领域最常用的库之一,其建立在 Pytorch 框架之上(Tensorflow 的版本功能并不完善),基本上 所有的Transformer 模型都可以在 Hugging Face Hub 中找到并且加载使用,包括训练、推理、量化等。
Huggingface官方提供了transformers 快速入门的官方教程,可以快速上手。
HuggingFace主要部分
- Models Hub:托管和分享模型。
- Datasets Hub:托管和分享数据集。
- Spaces:托管和运行应用(基于 Gradio 或 Streamlit)。
- Posts:帖子,可以查看最新的一些更新动态。
- Collections:收藏夹,可以查看最新的热门收藏内容。
- Community:社区,提供一些免费学习课程和博客。
每个hub提供了对应的标签,按内容分为: - tasks:按照Multimodal/Computer Vision/Natural Language Processing/Audio/Tabular/Reinforcement Learning等内容又做了具体的细分。 - libraries:指出改仓库使用了哪些库,如Pytorch、Transformers、PEFT、Diffusers等。 - datasets:指出改仓库使用了哪些数据集,如GLUE、SQuAD、Common Crawl、Wikipedia等。 - languages:指出改仓库使用了哪些语言,如English、Chinese、Spanish、French等。 - licenses:指出改仓库使用了哪些许可证,如Apache 2.0、MIT、CC-BY-NC-SA 4.0等。 - other:如inference status,misc杂项等
Transformers库
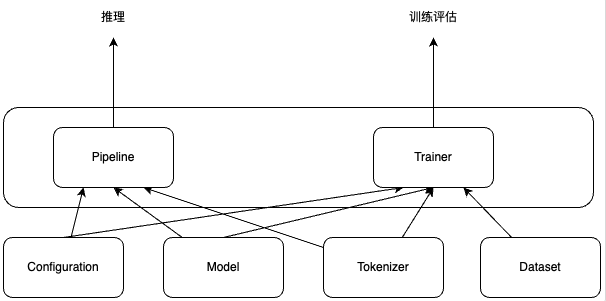
一个自然语言处理的库,提供了简单易用的API,可以快速地加载、训练和部署模型。并且提供统一的代码风格来使用BERT、XLNet和GPT等等各种不同的模型。 包含configuration,models和tokenizer三个主要类,并基于这三个类提供更上层的pipeline和Trainer,从而用更少的代码实现模型的预测和微调。
- pipeline 在底层是由 AutoModel 和 AutoTokenizer 类来实现的。AutoClass(即像 AutoModel 和 AutoTokenizer 这样的通用类)是加载模型的快捷方式,它可以从其名称或路径中自动检索预训练模型。
- 需要为每个模型系列使用特定的Transformers和Tokenizer(例如,如果使用T5模型系列,则对应T5Tokenizer和
T5ForConditionalGeneration),对于所有预训练模型,您可以声明一个简单的语句:
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-3b") model = AutoModelForCausalLM.from_pretrained("databricks/dolly-v2-3b")
下载模型文件
如果直接使用transformers 库,默认保存位置在:~/.cache文件夹下。
HF-Mirror提供了国内的镜像下载,推荐使用“方法三:使用 hfd”更加稳定并且下载进度条更直观。下载时记得使用tmux或screen等工具防止下载中断。
pipeline
开箱即用的 pipelines,它封装了预训练模型和对应的前处理和后处理环节。
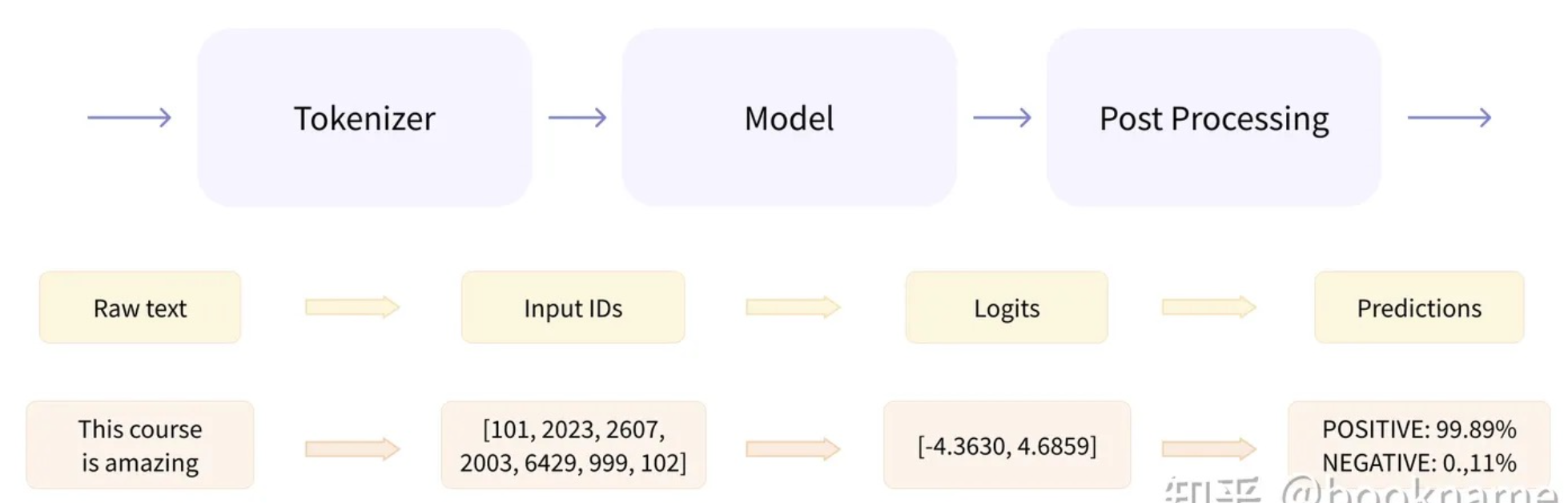 1. 预处理
(preprocessing),Transformer模型无法直接处理原始文本字符串;具体地,我们会使用每个模型对应的分词器
(tokenizer) 来进行。 -
将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens; -
根据模型的词表将每个 token 映射到对应的 token
编号/id;映射通常是通过创建文本语料库中标记的词汇表,并根据每个标记在语料库中的出现频率为其分配一个整数值来执行的(如BPE)。最常见的tokens被分配较低的整数值,而不太常见的标记被分配较高的值。
- 根据模型的需要,添加一些额外的输入。 - [PAD] - 用于填充序列到固定长度
- [CLS] - 分类任务中的起始标记 - [SEP] - 用于分隔不同文本段落 - [MASK] -
用于掩码语言模型预训练 - [BOS] /
1. 预处理
(preprocessing),Transformer模型无法直接处理原始文本字符串;具体地,我们会使用每个模型对应的分词器
(tokenizer) 来进行。 -
将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens; -
根据模型的词表将每个 token 映射到对应的 token
编号/id;映射通常是通过创建文本语料库中标记的词汇表,并根据每个标记在语料库中的出现频率为其分配一个整数值来执行的(如BPE)。最常见的tokens被分配较低的整数值,而不太常见的标记被分配较高的值。
- 根据模型的需要,添加一些额外的输入。 - [PAD] - 用于填充序列到固定长度
- [CLS] - 分类任务中的起始标记 - [SEP] - 用于分隔不同文本段落 - [MASK] -
用于掩码语言模型预训练 - [BOS] / - 序列开始标记 - [EOS] / -
序列结束标记 - [UNK] - 表示词表外的未知词
PS:除了上述训练推理时用到的特殊token,在chat任务时还有有其他的输入token(看promt template):
- "<|system|>" # 系统提示
- "<|user|>" # 用户输入
- "<|assistant|>" # AI助手回复
- "<|human|>" # 人类对话者
还有一些控制相关的token(多模态):
- "<|endoftext|>" # 文本结束
- "<|im_start|>" # 图像开始
- "<|im_end|>" # 图像结束- 将处理好的输入送入模型;
- 对模型的输出进行后处理
(postprocessing),将其转换为人类方便阅读的格式。
from transformers import pipeline # 使用pipeline加载模型 pipeline = pipeline("text-generation", model="gpt2") # 输入文本 input_text = "Once upon a time" # 生成文本 output_text = pipeline(input_text) print(output_text)
三大组件
- 「Configuration」:配置类,通常继承自「PretrainedConfig」,保存model或tokenizer的超参数,例如词典大小,隐层维度数,dropout rate等。配置类主要可用于复现模型。
- 「Tokenizer」:Model只能处理数字,因此Tokenizer需要将我们的文本输入转换为数字。总体上做三件事情:分词;扩展词汇表;识别并处理特殊token。
- 通常继承自「PreTrainedTokenizer」,主要存储词典(也就是
from_pretrained()的部分),token到index映射关系等。 - 此外,还会有一些model-specific的特性,如特殊token,
[SEP],[CLS]等的处理,token的type类型处理,语句最大长度等,因此tokenizer通常和模型是一对一适配的。
- 通常继承自「PreTrainedTokenizer」,主要存储词典(也就是
- 「Model」: 模型类。封装了预训练模型的计算图过程,遵循着相同的范式,如根据token ids进行embedding matrix映射(将token的one-hot编码转换成更dense的embedding编码),紧接着多个self-attention层做编码,最后一层task-specific做预测。
针对上述三大类,transformer还额外封装了AutoConfig, AutoTokenizer,AutoModel,可通过模型的命名来定位其所属的具体类,比如’bert-base-cased’,就可以知道要加载BERT模型相关的配置、切词器和模型。
from transformers import BertConfig, BertModel
# Building the config
config = BertConfig()
# Building the model from the config,使用随机值对其进行初始化
model = BertModel(config)
print(config)
BertConfig {
[...]
"hidden_size": 768, # 定义了hidden状态向量的大小
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12, # 定义了Transformer模型的层数
[...]
}
# 加载已经训练过的Transformers模型
model = BertModel.from_pretrained("bert-base-cased")# 加载与保存分词器
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
tokenizer.save_pretrained("./models/bert-base-cased/")
# 加载与保存模型
from transformers import AutoModel
# 所有存储在 HuggingFace Model Hub 上的模型都可以通过 Model.from_pretrained() 来加载权重,参数可以是 checkpoint 的名称,也可以是本地路径(预先下载的模型目录)
model = AutoModel.from_pretrained("bert-base-cased")
model.save_pretrained("./models/bert-base-cased/") # 保存模型
inputs = tokenizer(["来到美丽的大自然,我们发现"], return_tensors="pt")
# {'input_ids': tensor([[ 1, 68846, 68881, 67701, 67668, 98899, 91935]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1]])}
gen_kwargs = {"max_length": 128, "top_p": 0.8, "temperature": 0.8, "do_sample": True, "repetition_penalty": 1.1}
output = model.generate(**inputs, **gen_kwargs) # 这种生成方式更加可控,结果需要decode
# decode the new tokens
output = tokenizer.decode(output[0].tolist(), skip_special_tokens=True)
print(output)Transformers还将模型分为两个部分: 1. 基础架构:就像一个通用的引擎,负责理解输入的文本,将文本转换成计算机能理解的向量形式,所有任务都用相同的基础结构。 2. 任务相关的head:根据任务的不同,将基础架构的输出转换为任务需要的输出变量。
tranformers中常见的模型类型:
# 举例说明不同任务的模型
models = {
"*Model": "只输出基础理解,像原材料",
"*ForCausalLM": "预测下一个词(像GPT)",
"*ForMaskedLM": "完形填空(像BERT)",
"*ForMultipleChoice": "选择题",
"*ForQuestionAnswering": "回答问题",
"*ForSequenceClassification": "文本分类",
"*ForTokenClassification": "标注词语(如实体识别)"
}
Datasets
介绍
from datasets import load_dataset raw_datasets = load_dataset("glue", "mrpc") # GLUE基准测试中的MRPC任务 print(raw_datasets) # 包含训练集、验证集和测试集。每一个集合都包含几个列(sentence1, sentence2, label, and idx)以及一个代表行数的变量 #DatasetDict({ # train: Dataset({ # features: ['sentence1', 'sentence2', 'label', 'idx'], # num_rows: 3668 # }) # validation: Dataset({ # features: ['sentence1', 'sentence2', 'label', 'idx'], # num_rows: 408 # }) # test: Dataset({ # features: ['sentence1', 'sentence2', 'label', 'idx'], # num_rows: 1725 # }) #})简单使用
# 1. 加载内置数据集 dataset = load_dataset("glue", "mrpc") # GLUE基准测试中的MRPC任务 # 2. 加载本地文件 dataset = load_dataset("csv", data_files="my_file.csv") dataset = load_dataset("json", data_files="my_file.json") # 3. 访问数据 train_data = dataset['train'] first_example = train_data[0]为了预处理数据集,我们需要将文本转换为模型能够理解的数字,使用Dataset.map()方法
# example 是一个dict,对应数据集的每个元素,并返回一个包含input_ids、attention_mask 和token_type_ids为key的新dict # 在机器学习任务中,一个example通常定义为模型的输入(也成为特征集合) def tokenize_function(example): return tokenizer(example["sentence1"], example["sentence2"], truncation=True) tokenized_datasets = raw_datasets.map(tokenize_function, batched=True) print(raw_datasets) #DatasetDict({ # train: Dataset({ # features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'], # num_rows: 3668 # }) # validation: Dataset({ # features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'], # num_rows: 408 # }) # test: Dataset({ # features: ['attention_mask', 'idx', 'input_ids', 'label', 'sentence1', 'sentence2', 'token_type_ids'], # num_rows: 1725 # }) #})为了解决句子长度统一的问题,我们必须定义一个collate函数,该函数会将每个batch句子填充到正确的长度。
from datasets import load_dataset from transformers import AutoTokenizer, DataCollatorWithPadding raw_datasets = load_dataset("glue", "mrpc") tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") def tokenize_function(example): return tokenizer(example["sentence1"], example["sentence2"], truncation=True) tokenized_datasets = raw_datasets.map(tokenize_function, batched=True) data_collator = DataCollatorWithPadding(tokenizer=tokenizer)加载本地数据集
from datasets import load_dataset #{ # "data": [ # { # "title": "Terremoto del Sichuan del 2008", # "paragraphs": [{...}] # } # ], # "version": "1.1" #} squad_it_dataset = load_dataset("json", data_files="SQuAD_it-train.json", field="data") print(squad_it_dataset) # 加载本地文件会创建一个带有train的DatasetDict 对象 # DatasetDict({ # train: Dataset({ # features: ['title', 'paragraphs'], # num_rows: 442 # }) #}) data_files = {"train": "SQuAD_it-train.json", "test": "SQuAD_it-test.json"} squad_it_dataset = load_dataset("json", data_files=data_files, field="data") print(squad_it_dataset) # 包括 train 和 test 的 DatasetDict 对象 #DatasetDict({ # train: Dataset({ # features: ['title', 'paragraphs'], # num_rows: 442 # }) # test: Dataset({ # features: ['title', 'paragraphs'], # num_rows: 48 # }) #})streaming=True:dataset = load_dataset("json", data_files="my_file.json", streaming=True) # 返回一个迭代器,可以逐个处理数据
源码分析
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
sequences = ["I've been waiting for a HuggingFace course my whole life.", "So have I!"]
tokens = tokenizer(sequences, padding=True, truncation=True, return_tensors="pt")
print(tokens)
#{
# 'input_ids': tensor([
# [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172,2607, 2026, 2878, 2166, 1012, 102],
# [ 101, 2061, 2031, 1045, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# ]),
# 'attention_mask': tensor([
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# ])
#}
output = model(**tokens) # model(**tokens, labels=labels), 如果提供labels,则计算损失
print(output)
# SequenceClassifierOutput(
# loss=None, # 损失值,在没有提供标签时为None
# logits=tensor([
# [-1.5607, 1.6123], # 第一个序列的预测分数(两个类别)
# [-3.6183, 3.9137] # 第二个序列的预测分数
# ]),
# hidden_states=None, # 隐藏状态,默认不返回
# attentions=None # 注意力权重,默认不返回
# )tokenizer
tokens = tokenizer(
sequences, # 输入文本,可以是单个字符串或字符串列表
padding=True, # 填充设置
truncation=True, # 截断设置
return_tensors="pt" # 返回格式
)padding
# 相关参数 tokens = tokenizer( ["Hello", "Hi there!"], padding=True, # 填充设置 max_length=10, # 最大长度限制 padding_side='right' # 填充位置:'left'或'right' )truncation: 截断设置
return_tensors: 返回格式(pt, tf)
return_token_type_ids: 是否返回token_type_ids(默认False, 用于区分不同句子)
output = model(**tokens)
对于文本分类来说,整段文本输入返回一个标签,也就是SequenceClassifierOutput.logits,
如果是文本生成模型,整段文本输入返回CausalLMOutputWithPast, 对于 input_ids = [v1,v2,v3] 输出为 [v20,v30,v4]。 v20 是根据v1 生成的下一个token(大概率跟真实的v2 不一样),v4 是根据v1,v2,v3 生成的。 1. 生成式模型的训练是并行的,靠的attention mask操作。训练的时候只需要调用一次即可,因为attention mask的机制可以保证当前token的loss不包含后面的token。inputs 则是一个dict,包含input_ids 和 attention_mask。 2. 推理的时候,只能一个字一个字的推理,所以会调用多次。 output = model(inputs) 或者 output = model.forward(inputs)的时候,inputs 其实也不需要包含 attention_mask,inputs 仅仅是token 就可以
model(xx) ==> Module.__call__ ==>
Module.forward/model.forward,几乎每一个llm 都会自定义forward
方法,如果向forward 方法传入 labels,还会自动计算loss。



