GPU与内存
深度学习模型的基础计算单元是"算子",本质上是将输入映射为输出的计算过程,对于古老的CPU-内存体系来说,算子遵循一下步骤: - 从内存中读取输入数据 - 对独到的数据调用CPU指令,完成算子计算 - 将计算结果写回内存
内存
通常指的是随机访问存储器(RAM),“随机”意味着访问任何位置的数据所需的时间是相同的,与位置无关。 RAN可以分为两类: - 静态随机访问存储器(SRAM):基于双稳态触发器(bistable flip-flop),读取时不会丢失数据(非破坏性读取)。常用于Cache。 - 动态随机访问存储器(DRAM):基于电容存储,读取数据会丢失数据,需要重写(破坏性读取,需刷新)。常用于主存。
不管是SRAM还是DRAM,都是临时存储,断电后数据会丢失的,数据不会保留(易失性)。
在选用内存时往往会看到DDR4、DDR5等字样,指的是基于DDR的第几代产品,涉及技术标准、芯片结构及控制算法的升级,但是要看主板是否支持最新一代内存规格。
CPU
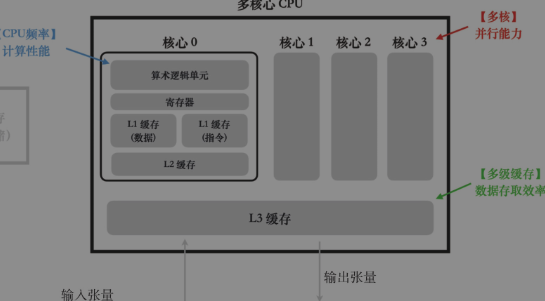 CPU的核心结构包括负责计算的算数逻辑单元(ALU)、负责加速数据读写速度的多级缓存,在此基础上还会采用CPU多核心设计来增加并行度。
CPU的核心结构包括负责计算的算数逻辑单元(ALU)、负责加速数据读写速度的多级缓存,在此基础上还会采用CPU多核心设计来增加并行度。
硬盘
与RAM不同,硬盘是长期存储设备,断电后数据不会丢失,数据会保留(非易失性)。 一般常用的硬盘有机械硬盘HDD和固态硬盘SSD。SSD的读写速度远高于HDD,但是价格也更高。
硬盘的读写行为大致分为两种模式: - 随机读写模式:高频率读写小规模数据。IOPS(Input/Output Operations Per Second)是衡量硬盘随机读写速度的指标。 - 连续读写模式:需要读取大文件或顺序访问数据。MB/s(Megabytes per second)是衡量硬盘连续读写速度的指标。
其中连续读写速度有硬盘连续读写速度和数据传输速度共同决定。随着硬盘读取效率的不断提高,读写效率的瓶颈慢慢开始出现在了数据传输阶段,所以在SATA固态硬盘的基础上,又发展出了NVMe固态硬盘。NVMe固态硬盘使用传输效率更高的PCIe传输通道,在读写性能上往往超出SATA固态硬盘许多。
显卡
CPU局限性
CPU可以“全能”的处理各种指令(计算指令、访存指令,也能够处理好跳转等逻辑指令),但在处理计算密集型任务时,CPU的计算速度不如GPU或其他异构芯片高效。
因此针对计算密集型的额任务,应该让CPU处理复杂的交互逻辑,而采用一个专门的芯片处理密集的计算, 这需要我们在软件层面上对程序任务进行划分,将一个程序涉及的所有任务都分为两种类型: - 外围任务:业务代码、API接口、用户交互等逻辑复杂的任务。 - 内核任务:高度内聚的计算密集型任务,逻辑分支很少。
而GPU可以处理密集的计算,例如一个3D游戏,其中用户交互、用户界面(UI)、音频等部分由CPU负责处理,而图形渲染和物理仿真等核心计算任务则由GPU执行。 在深度学习领域,核心的计算任务被封装成算子并在GPU上执行,而复杂的逻辑调度、数据搬运等任务则由CPU完成。
GPU硬件结构
GPU的计算核心并不能直接从内存读取数据,于是在二者之间又加入了显存(VRAM)这个额外的存储元件。
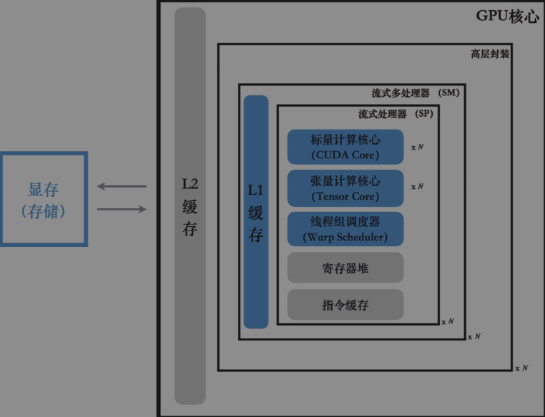
GPU自顶向下可以分为以下几个部分: - 最外层:显存、L2缓存 - 高层封装单元:流式多处理器(SM) - L1缓存 - 多个流式处理器(SP),共享一个SM的L1缓存,每个SP包括: - 若干标量计算核心(CUDA core) - 若干张量计算核心(tensor core) - 若干寄存器 - 线程束调度器(warp scheduler)
这里面真正重要的是图中标记为蓝色的几个硬件单元。其中张量计算核心、标量计算核心决定了GPU的整体计算效率;L1缓存、显存决定了GPU存取数据的效率;线程束调度器则与CUDA编程模型中的线程束(warp)概念直接对应,负责线程间的通信和调度。
A100(Ampere架构)中的SM如下图: 
A100整体架构图: 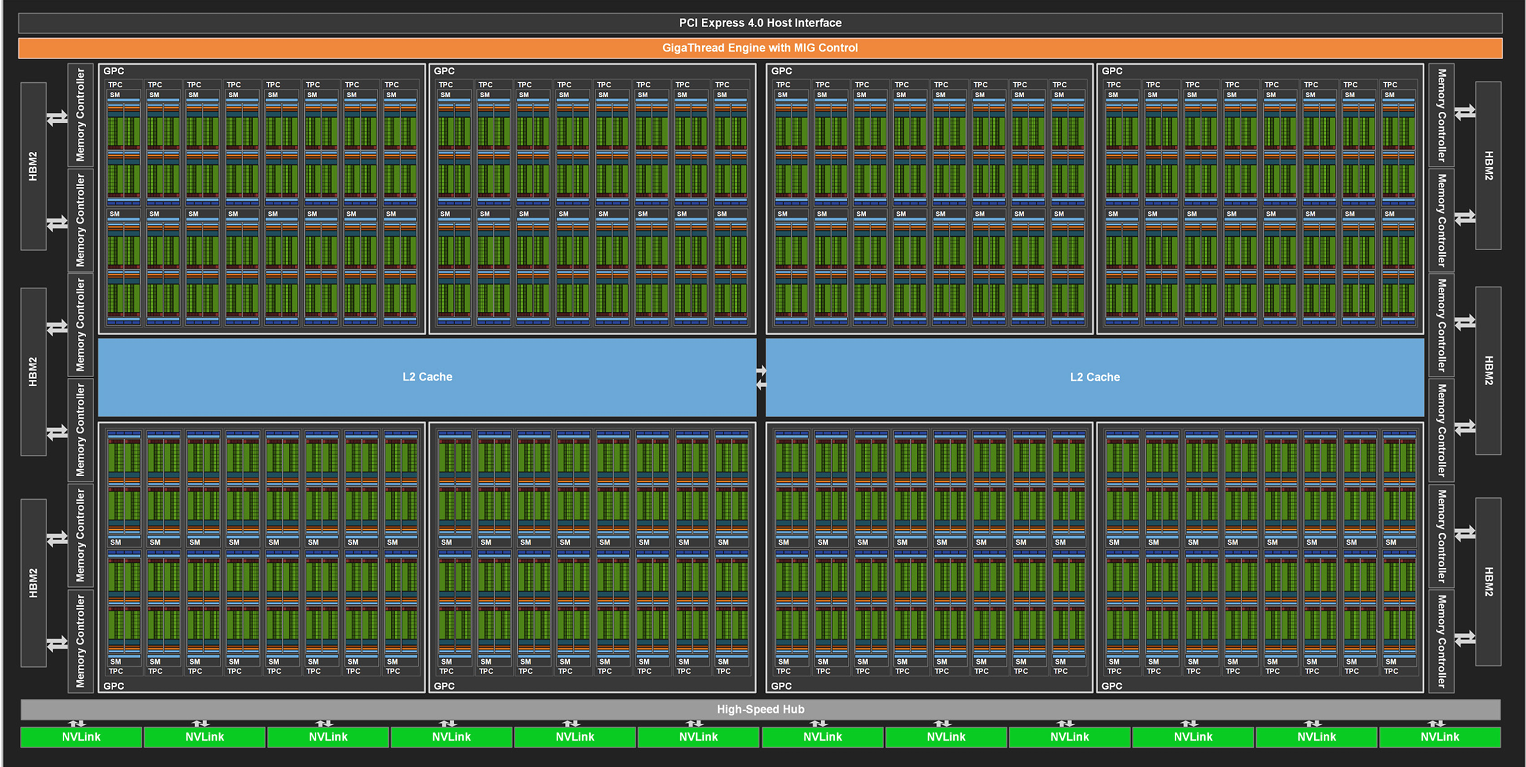
GPU编程模型及其硬件对应
Python、C++等程序能够在计算机上运行,是因为它们通过编译器转换成硬件能识别的指令,从而在CPU上执行。 基于这一逻辑,如果存在一个能将C++或Python编译成GPU指令的编译器,我们就可以直接在GPU上运行这些代码。 然而,遗憾的是,NVIDIA没有提供这种直接的编译器。相反,NVIDIA开发了一套专门的GPU编程模型,称为CUDA语言,来支持在GPU上进行编程。 CUDA编程模型本质是对GPU硬件的抽象。
CUDA编程模型的核心是要求程序员将算法的实现代码,拆分成多个可以独立执行的软件任务。
我们将算法拆分得到的每个独立任务,称为一个线程。线程是软件层面最小的执行单元。
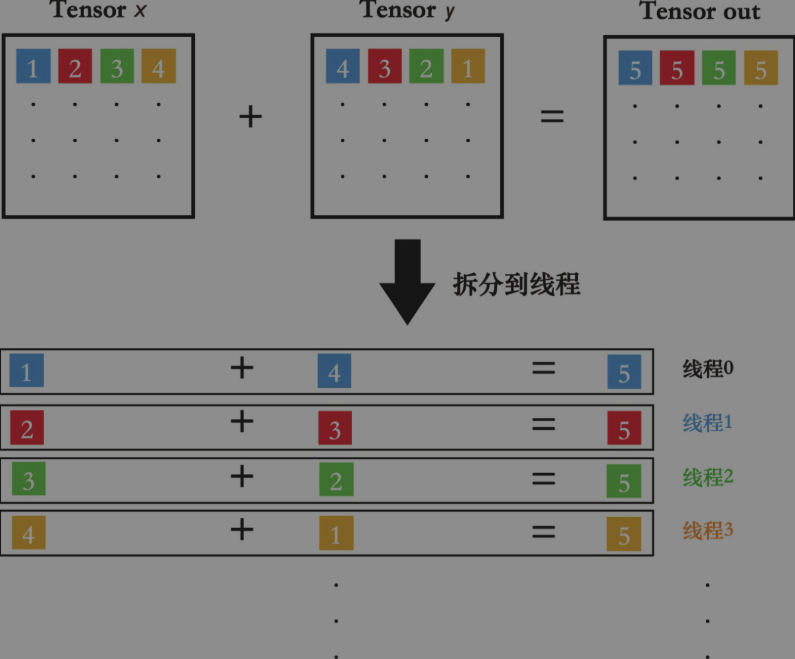
为了尽可能提高并行度,SP中的线程束调度器(warp
scheduler)会将每32个线程打包成一个线程束(warp)。
在一个时钟周期内,每组线程束会被调度到一个流式处理器上,执行一条相同的GPU指令。
SM对应CUDA编程语言中线程块(block)的概念。 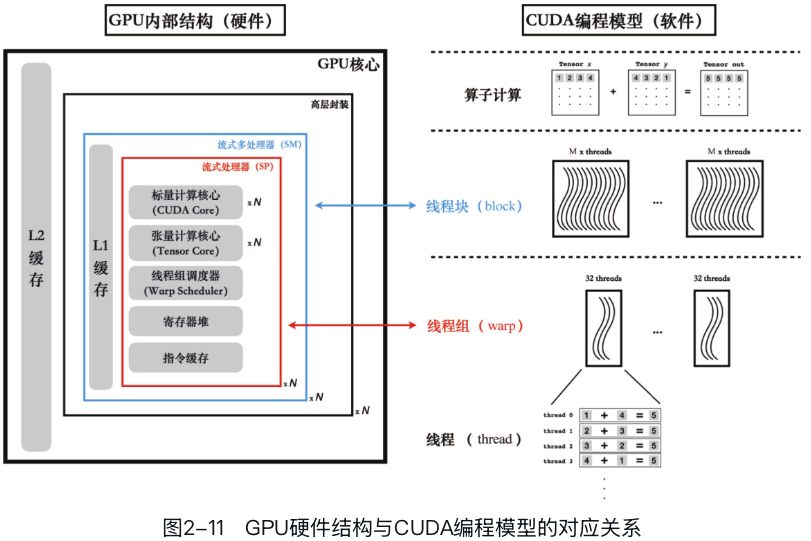
GPU的并行能力其实分为软件并行和硬件并行两层: - 软件并行:将算子拆分成多个可以独立执行的线程,使用CUDA语言实现。 - 硬件并行:对线程进行分组,然后以线程束(warp)或者线程块(block)为单元,并行执行这些线程。
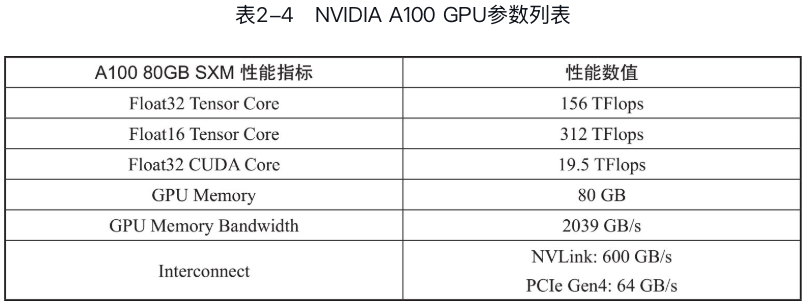
GPU的关键指标
- Tensor core和CUDA core性能:决定了计算效率。
- 显存大小:决定了可以承载的模型、数据规模上限。
- 显存带宽:决定了显存读写效率。
- 卡间通信带宽:决定了多块GPU卡之间数据通信的效率。
显存VRAM与内存DRAM之间的数据传输
一般来说,VRAM与DRAM之间的传输依靠CPU进行调度,但是如果DRAM中的数据存储在锁页内存(Pinned Memory)中,CPU无法直接访问,此时就需要使用DMA(Direct Memory Access)技术。
另外,NVIDIA还提供了依靠DMA的VRAM与硬盘/网络之间数据传输: - GPU Direct Storage技术:允许GPU借助DMA直接访问NVMe固态硬盘; - RDMA技术:允许GPU借助DMA直接访问网络存储。
分布式系统
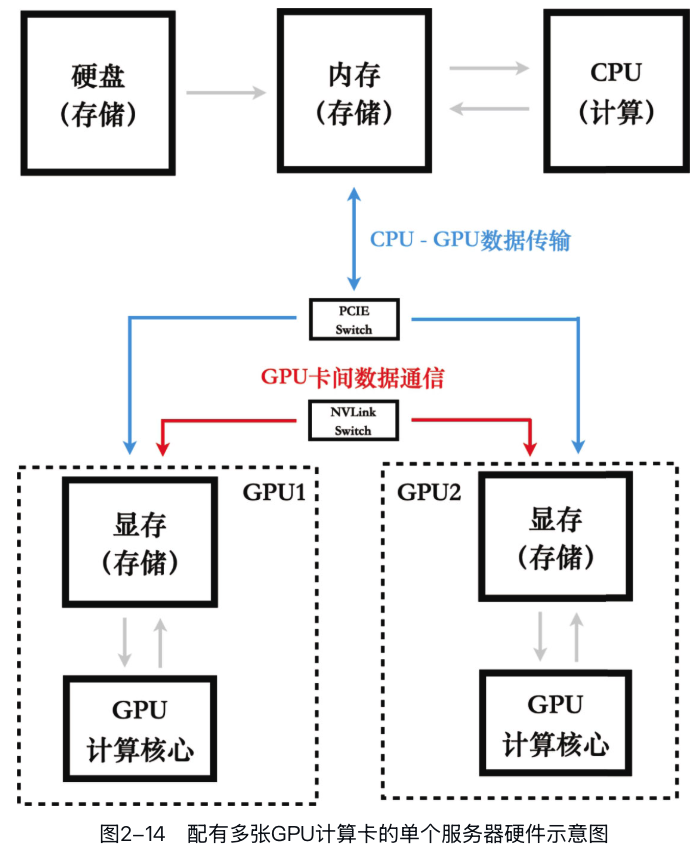
单机多卡
多卡在单机上的通信方式有两种: - 通过PCIe总线连接 - 通过NVLink连接
NVLink是NVIDIA开发的一种高速互连技术,专门用于GPU之间的通信(CPU与GPU之间的通信使用PCIe总线)。
NVLink第一代在Pascal架构中被引入,后面逐代升级。 
多机多卡
在涉及多机多卡的分布式训练中,不同机器上的GPU通信的硬件不再是NVLink或者PCIe这种高带宽低延迟的互联,而是基于网络设备的传输。
两类主流的解决方案分别基于Ethernet以及InfiniBand。

分布式系统的数据存储
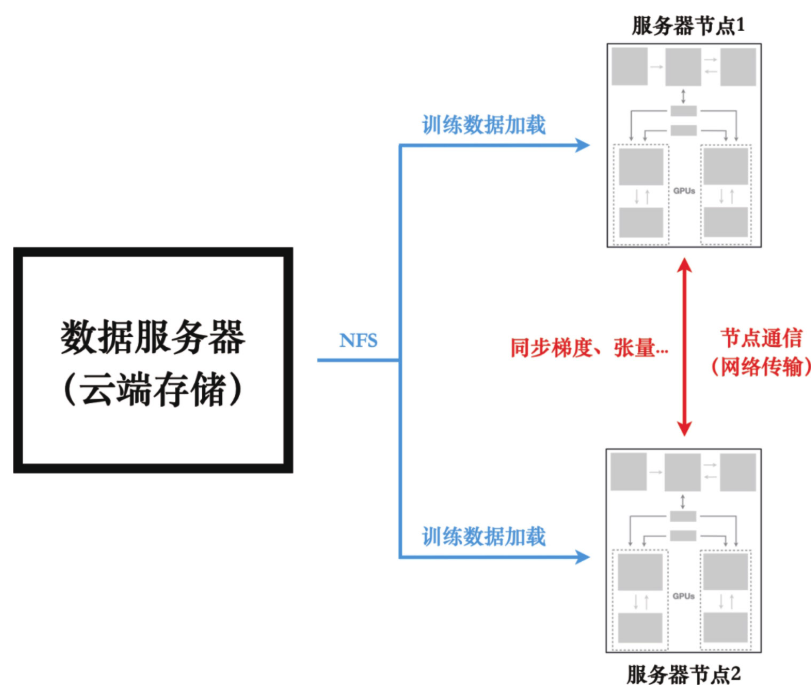
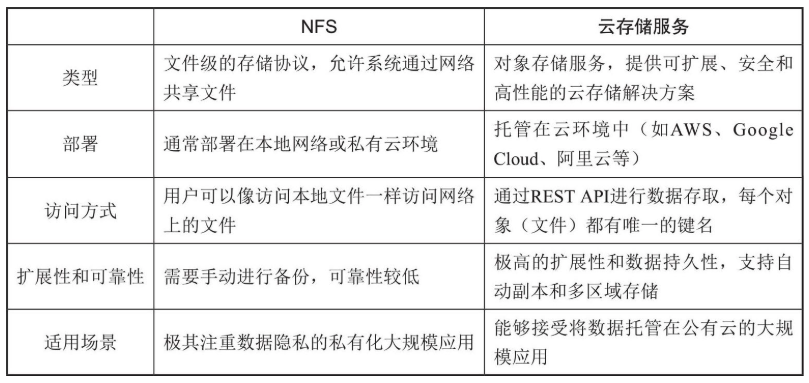
对于分布式训练系统来说,通过每台服务器的本地硬盘存储大规模训练数据并不现实。
基于网络的存储方案在分布式系统中更受欢迎。通常也分为两类,即NFS(network
file system,网络文件系统)和基于云服务的存储方案。
分布式系统的硬件示意图: