本章将从PyTorch的核心概念——张量和算子讲起,逐步深入PyTorch的内存分配、基于动态图的运行机制,以及作为训练框架的杀手锏级特性——自动微分系统的底层原理
PyTorch的张量数据结构
Pytorch通过张量(torch.Tensor)作为数据容器提供了统一的方式来处理不同维度和形状的数据(标量、向量、矩阵、张量)。
张量的基本属性及创建
import torch
x = torch.tensor((3,2), dtype=torch.float32, device=torch.device('cuda'))
print(x.dtype) # torch.float32
print(x.device) # cuda:0
print(x.shape) # torch.Size([3,2])访问张量的数据
# 创建一个10行20列的连续张量, 并使用contiguous()方法确保张量在内存中是连续的
x = torch.arange(200).reshape(10,20).contiguous()
# 访问张量中的数据
print(x[0, 0]) # tensor(0)
print(x[0, -1]) # tensor(19)
print(x[2, :]) # tensor([40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59])
print(x[0, 1:9:3]) # tensor([1, 4, 7])
print(x[..., 1]) # tensor([1, 21, 41, 61, 81, 101, 121, 141, 161, 181])
print(x[:, None, :]) # 使用None 插入一个新维度,返回一个形状为(10, 1, 20)的张量张量的存储方式
torch.Storage是用于表示数据在物理内存中的存储方式,其实就是一块连续的一维内存空间。每个torch.Storage对象负责维护存储数据的类型和总长度信息。
在此基础上,torch.Tensor添加了如形状(shape)、步长(stride)和偏移量(offset)等额外的属性,定义了torch.Tensor访问底层数据的具体方式。
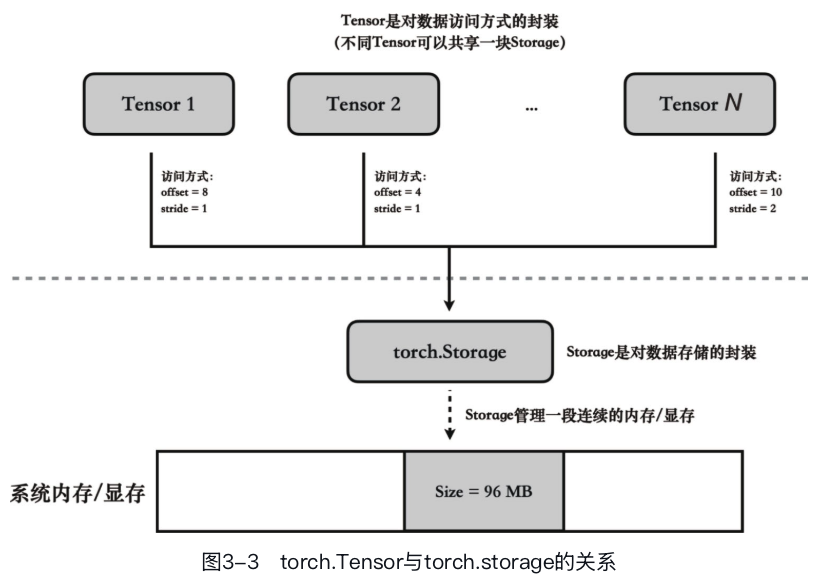
步长指定了在遍历张量数据时,必须在内存中跳过多少元素才能到达下一个元素。 比如我们可以通过改变步长属性来实现一个高效的张量转置操作:
import torch
# 创建一个3*4的张量, 使用contiguous()确保其连续性
x = torch.arange(12).reshape(3, 4).contiguous()
print(f"x = {x}\nx.stride = {x.stride()}")
# x = tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]])
# x.stride = (4, 1)
y = torch.as_strided(x, size=(4, 3), stride=(1, 4))
print(f"y = {y}\ny.stride = {y.stride()}")
# y = tensor([[ 0, 4, 8],
# [ 1, 5, 9],
# [ 2, 6, 10],
# [ 3, 7, 11]])
# y.stride = (1, 4)
# 张量x和y共享同一块底层存储
assert id(x.untyped_storage()) == id(y.untyped_storage())
使用stride属性来访问张量是非常高效的,因为它无需复制,直接操作同一个张量的底层数据存储。但它也是把双刃剑,因为会导致“张量不连续”。 其次许多PyTorch算法在设计时就预设了张量在内存中是连续存储的,如果遇到不连续的张量,可能会抛出错误提示甚至得到错误的计算结果。 PyTorch提供了tensor.is_contiguous()方法用于检测张量是否为连续。对于不连续的张量,可以通过调用tensor.contiguous()方法生成一个连续的副本。然而天下没有免费的午餐,这个调用会将原始数据复制到一块新的连续内存空间,增加内存占用,因此读者在开发时需要时刻注意内存和性能之间的平衡。
张量的视图
不同的张量可以共享同一块底层存储,当这些共享存储的张量互不重叠时,影响较小。但如果它们不仅共享底层存储,还存在重叠,我们称其中一个张量为另一个张量的视图(view)。
以下是pytorch中常见的几种视图操作,它们都共享同一块底层存储,但返回的张量形状可能不同。
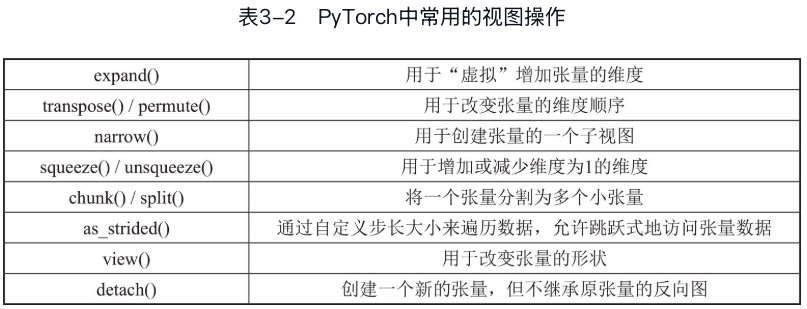 基于基础索引的张量读取操作返回的也是视图:
基于基础索引的张量读取操作返回的也是视图:
import torch
x = torch.zeros(3,3)
y = x[0]
y[0] = 1
print(f"x = {x}\ny = {y}")
# x = tensor([[1., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]])
# y = tensor([1., 0., 0.])注意一些接口如 reshape()和flatten() 的行为较为特殊,它们根据具体的使用场景返回一个视图张量或一个全新内存的张量。这种行为的不确定性导致这些接口并不是最理想的API设计。
Pytorch中的算子
算子库
PyTorch提供了大量用于构建神经网络的算子,这些算子可以分为以下几类: - (1)基础数学运算:涵盖了加法(+)、减法(-)、 **乘法(*/mul) 、除法(/)、指数(exp)、幂次方(pow)等基本数学操作。(element-wise操作) - (2)线性代数运算:包括矩阵乘法(matmul/@)**、点乘(dot)、转置(t)、逆矩阵(inverse)等线性代数相关的运算。 - (3)逻辑和比较运算:例如逻辑与(logical_and)、逻辑或(logical_or)、等于(eq)、大于(gt)、小于(lt)等用于比较和逻辑判断的操作。 - (4)张量操作:涉及张量的索引、切片、拼接(cat)、调整形状(reshape)、调整维度(permute)等操作,用于张量的形状和内容调整。 - (5)其他特殊运算:包括深度学习中使用的各种层(如卷积层、池化层、注意力层)以及损失函数等特定于应用的复杂运算。
矩阵乘法 矩阵乘法是深度学习中非常常见的操作,PyTorch提供了多种矩阵乘法运算符,包括: - dot:用于计算两个1D向量之间的点积,返回一个标量。 - mm:用于计算两个2D矩阵之间的矩阵乘积。 - matmul:用于计算两个张量之间的矩阵乘积。(1D时等价dot,2D时等价mm) - bmm:用于批量计算矩阵乘积。
Pytorch算子的返回值内存分配
PyTorch算子操作的输入和返回值都是张量,但返回值是否创建新的内存取决于具体的算子。 #### 原地操作 PyTorch也为一些算子提供了原位(inplace)操作,它们直接修改输入张量的数据并返回同一个张量,无须创建新的内存。 - 原位操作通常在方法名后加下划线 (_)表示,例如add_()是add()的原位版本。 - 某些语法也会隐式地触发原位操作。比如x+=y将触发原位加法操作,而x = x + y就只是普通的加法操作和赋值操作。
视图操作
输出张量与输入张量共享底层内存,因此不会造成额外的内存分配。
读取操作
- 基础索引操作:返回的是视图。
- 高级索引操作:类似于NumPy的高级索引,也就是使用布尔或者整数张量作为索引。基于高级索引的读取操作会创建新的内存存储。
#### 赋值操作 张量赋值操作是指使用基础索引、高级索引、广播等方式将新的值赋给张量的特定位置。赋值操作直接修改输入张量的内容,没有返回值。import torch # 创建一个10*20的张量, 使用contiguous()确保其连续性 x = torch.arange(200).reshape(10, 20).contiguous() # 基础索引,读取x的第0行 y_basic_index = x[0] # (1) 基于基础索引进行读取的返回张量和x共享底层存储 assert y_basic_index.data_ptr() == x.data_ptr() # 使用整数张量对x进行高级索引,返回位置在[0, 2], [1, 3], [2, 4]位置的元素 z_adv_index_int = x[torch.tensor([0, 1, 2]), torch.tensor([2, 3, 4])] # z_adv_index_int = tensor([ 2, 23, 44]) # 对张量x中的每个元素进行判断,如果元素的值小于10,则对应位置的ind为True,否则为False ind = x < 10 # 使用布尔张量对x进行高级索引,返回x中所有对应ind位置为True的元素 z_adv_index_bool = x[ind] # z_adv_index_bool = tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) # (2) 基于高级索引进行读取的返回张量和x的底层存储是分开的 assert z_adv_index_int.data_ptr() != x.data_ptr() assert z_adv_index_bool.data_ptr() != x.data_ptr()
### 算子的调用 以下面代码为例分析一下PyTorch中y = x1 @ x2在整个调用中大致经历了哪些过程:import torch # 创建一个10*20的张量, 使用contiguous()确保其连续性 x = torch.arange(200).reshape(10, 20).contiguous() # 对张量x中的每个元素进行判断,如果元素的值小于10,则对应位置的ind为 True,否则为False ind = x < 10 # 通过高级索引对x的部分元素进行赋值 x[ind] = 1.0 print(x) # x的对应位置也被更新成1.0import torch x1 = torch.rand(32, 32, dtype=torch.float32, device="cuda:0") x2 = torch.rand(32, 32, dtype=torch.float32, device="cuda:0") y = x1 @ x2 - (1)函数入口:这个表达式会首先调用Python中Tensor类的__matmul__方法作为“矩阵乘法”算子的入口。
- (2)定位算子:PyTorch核心的分发系统(dispatcher)会根据算子类型、输入张量的数据类型、存储后端来找到可以承担该算子计算的底层算子实现。 比如这个例子中,分发系统找到GPU上float32类型矩阵乘法计算对应的CUDA函数实现。
- (3)创建张量:创建所需的输出张量。
- (4)底层调用:调用我们找到的算子函数,进行类型转换、输出张量的创建等必要步骤,计算并将结果写入输出张量。
- (5)函数返回:创建输出张量的Python对象并返回给用户。

图3-5展示了在PyTorch调用一个矩阵乘法算子的调用栈,这里面最核心的步骤是底层调用也就是算子计算,但是前后还做了一系列准备工作,这些准备工作统一称为调用延迟。 虽然少数算子的调用延迟可以接受,但如果频繁调用算子,则累积起来的总调用延迟就不能忽视了。 后续通过CUDA Graph降低调用延迟。
在日常开发中应该紧绷一根弦,尽量减少不必要的操作,如能对张量整体进行操作的时候尽量避免手动操作数组中的单个元素。 因为单个数组元素的读取和赋值都是一次算子调用。 比如对于张量加和运算,如果通过在Python中手写循环来完成“读取单个元素→加和→存储回张量”这个过程,所需要的计算时间要远远高于直接使用张量的加法操作。 这是因为张量的加法和归约操作能够充分地利用GPU的并行计算能力,在性能上会显著优于对单个张量元素进行的串行操作。
Pytorch动态图机制
计算图
计算图是深度学习框架中用于描述和执行计算过程的抽象模型:一个有向无环图,其中的节点(node)代表各种算子操作,比如加法、乘法或更复杂的操作如卷积等,而边(edge)则代表数据(指张量数据)的流动。 ### 动态图与静态图的区别 - 动态图:运行时构建
import torch
x = torch.tensor(2) # 可以尝试不同的值,如 torch.tensor(1.0)
y = x % 2
if y == 0:
z = x * 10
else:
z = x + 10
print(z)import tensorflow.compat.v1 as tf
x = tf.placeholder(tf.float32, shape=())
def true_fn():
return tf.multiply(x, 10)
def false_fn():
return tf.add(x, 10)
y = x % 2
z = tf.cond(tf.equal(y, 0), true_fn, false_fn)
with tf.Session() as sess:
print(sess.run(z, feed_dict={x: 2})) # 输出 10 (2 * 10)
print(sess.run(z, feed_dict={x: 1})) # 输出 11 (1 + 10)差别
- (1)执行方式:静态图有明确图的定义和图的运行两个阶段。而动态图则是在定义的同时就执行,立即得到结果。例如,在TensorFlow中,y = x % 2只是向计算图中添加一个运算节点,该运算不会立即执行。但在动态图中,这个语句在添加节点的同时也执行了该运算。
- (2)数据表示:在静态图的定义阶段,x、y、z都是符号,不含具体数据。只有在运行时,我们才对输入x赋值。而在PyTorch的代码中,x、y、z一开始就是带有具体数据的张量。
- (3)中断与调试:静态图一旦运行就不能中断。要在静态图中打印中间变量y的值进行调试,需要插入tf.Print()语句并重新运行图。但是在PyTorch中,执行过程可以中断,比如可以用import pdb; pdb.set_trace()使运行暂停,并可以自由地打印或修改张量的内容。
- (4)代码执行:在TensorFlow
1.0中,计算图的执行全都是由TensorFlow的底层运行处理的——包括print语句和条件语句在内。而在PyTorch代码中,条件语句和print语句是由Python解释器执行的,只有与张量相关的操作是由PyTorch的运行处理的。这种设计保持了Python作为解释型语言的灵活性,从而可以支持动态修改代码和交互式编程。
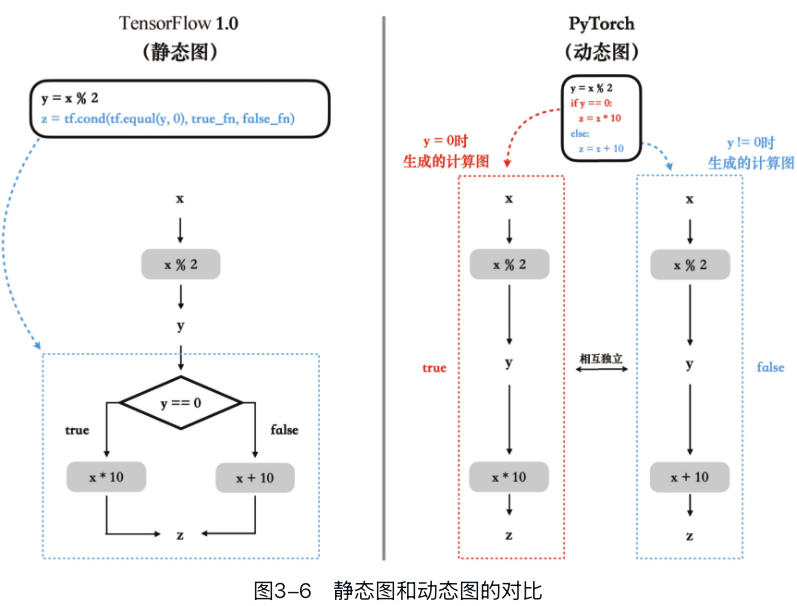
由于静态图在执行前就获得了完整的图信息,使得它能够应用更复杂的优化策略,如移除无用操作、进行跨操作优化,甚至执行算子融合等。 对于追求极致性能的部署工程师来说,像TensorFlow 1.0这样的框架仍然是首选之一。而对于研究人员,快速迭代和易于调试的特性使得PyTorch具有显著优势。
Pytorch 的自动微分系统
自动微分
基于有限差分的数值微分法:通过对输入变量添加一个微小扰动,比如设定h=0.000001,然后观察输出的变化来近似计算梯度值。精度不高,但是实现简单。
基于符号微分的梯度求导公式:基于封闭形式表达式(closed-form expression)的梯度求导公式。 但是对于程序中涉及基于动态输入或条件变化的循环、复杂递归、动态内存分配及涉及大量非线性数据处理等复杂逻辑,将其转化为封闭形式通常是不可能的。 因此,尽管符号微分在计算效率上非常高,其适用性却受到很大限制。
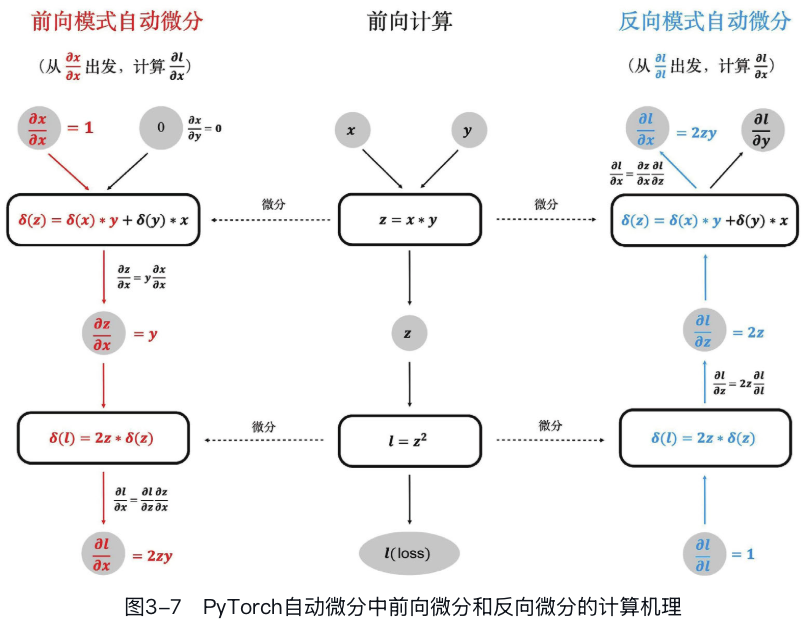
而自动微分(automatic differentiation)则是一种介于数值微分和符号微分之间的方法: - (1)它定义了一系列的“基本操作”(如加、减、乘、除),并且根据手动推导的结果定义了这些操作的梯度。例如,在手动推导z=y×x的微分形式时,我们可以得到 \(\frac{\partial z}{\partial x} = y\) 类似这样的基础操作梯度公式会被硬编码在自动微分系统中,是它的核心组成元素。 - (2)在程序运行时,自动微分系统会基于链式法则将复杂运算拆解成基础操作的组合,一步步计算所有中间结果的梯度,并最终计算出输入参数的梯度。注意在运算过程中对于同一个张量的梯度是累加而不是覆写的。而且这里累加的是具体数值而非符号表达式,这一点至关重要,它使得自动微分系统能够自然地兼容程序中出现的逻辑判断,如分支、循环和递归等,而这对符号微分系统是非常困难的。
自动微分的实现
PyTorch的自动微分系统中默认使用反向微分模式。它以某个输出张量的梯度作为起点,反向逐层计算出每个输入参数对应的梯度,计算图的执行次数与输出张量的数量有关——M个输出张量就需要执行M次计算图。 绝大多数深度学习模型训练的场景都是有w1,w2,...,wN个模型参数,但只有数个甚至一个损失函数(loss)。
还有一种前向模式的自动微分。它以某个输入参数的梯度作为起点,向前逐层计算出每个输出张量对应的梯度,计算图的执行次数与输入参数的数量有关——N个输入参数就需要执行N次计算图。
所以前向微分适合输入参数少而输出张量多的场景,比如模型只有一个输入参数w,但是输出M个loss的情况,这一般多见于科学计算相关的场景,尤其在计算高阶导数时。
PyTorch自动微分机制依赖于torch.Tensor上的两个额外属性,即grad和requires_grad。 - grad:存储了张量对应的梯度值,初始值为None。 - requires_grad:表示是否需要计算梯度。
示例:
import torch
# 创建一个需要计算梯度的张量
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
# 前向传播:
# 1. 构建并执行前向图
# 2. 构建反向图
t = x * 10
z = t * t
loss = z.mean()
# 反向传播,计算梯度
loss.backward()
# 查看x的梯度
print(x.grad)注意每一个算子在前向调用时,就会当场在反向图中构建一个反向算子,前向计算图是当场构建、当场执行的,但反向计算图则是当场构建、延迟执行的——直到我们调用loss.backward()时才会开始执行反向图。
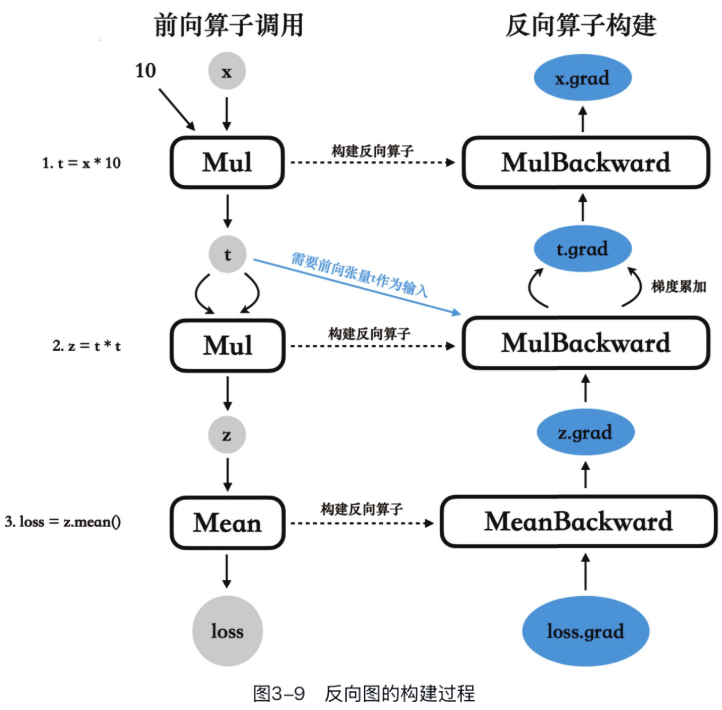
需要注意梯度是累加的,如果多次调用backward(),每次调用计算出的梯度也会累积到对应张量的grad属性中,这也是为什么我们需要在每轮训练循环开始前调用optimizer.zero_grad()来手动清零梯度的原因。
Autograd扩展自定义算子
在实际开发过程中,当我们遇到需要使用一些非标准或特殊的数学操作,而这些操作又不在PyTorch库的支持范围内时,可以利用PyTorch自动微分系统提供的扩展模块来自定义新的算子。新定义的操作能够像PyTorch中的任何其他操作一样被使用,并能自然而然地融入PyTorch的自动微分机制中。
举例来说,假如我们要实现一个计算 \(input1 \times input1 \times input2\) 的算子,其实现方法如下所示:
import torch
class MyMul(torch.autograd.Function):
@staticmethod
def forward(ctx, input1, input2):
ctx.save_for_backward(input1, input2)
return input1 * input1 * input2
@staticmethod
def backward(ctx, grad_output):
input1, input2 = ctx.saved_tensors
grad_input1 = grad_output * 2 * input1 * input2
grad_input2 = grad_output * input1 * input1
return grad_input1, grad_input2
# 使用自定义的乘法操作
x = torch.tensor([2.0, 3.0], requires_grad=True)
y = torch.tensor([3.0, 4.0], requires_grad=True)
z = MyMul.apply(x, y)
z.backward(torch.tensor([1.0, 1.0]))
print(f"x.grad={x.grad}, y.grad={y.grad}")
# x.grad=tensor([12., 24.]), y.grad=tensor([4., 9.])Pytorch的异步执行
PyTorch支持不同的计算后端,模型训练主要依赖其中的CPU和GPU后端。 在使用PyTorch的不同计算后端时,主要会影响以下三个方面: - 张量的存储位置。 - 算子的执行硬件。 - 执行机制。
前两者比较容易理解:使用CPU后端时张量存放在内存中,算子在CPU上执行;而使用GPU后端时张量存放在显存里,算子在GPU上执行。
但是第三点“执行机制”的变化则更为复杂。 #### CPU后端执行机制
每一个Python指令都对应一个CPU算子任务。每个算子在CPU上完全执行完毕,得到输出结果后,才跳转到下一条Python指令,开始执行后续的算子任务。这种执行机制被称为同步执行机制。
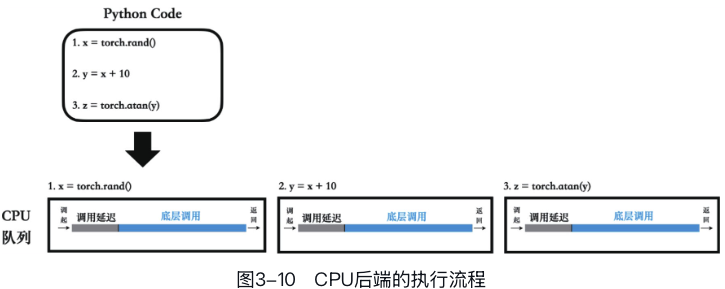 #### GPU后端执行机制
PyTorch也只会把核心的算子计算任务放在GPU上,而类型提升、输出信息推导、输出张量的创建、定位算子等任务依然还留在CPU上。
#### GPU后端执行机制
PyTorch也只会把核心的算子计算任务放在GPU上,而类型提升、输出信息推导、输出张量的创建、定位算子等任务依然还留在CPU上。

GPU内部维护了一系列任务队列(stream),CPU会将算子任务(一般是一个CUDA函数)提交到GPU的任务队列上,之后就可以撒手不管了,GPU会自行从任务队列中依次拿出计算任务然后执行。
不仅如此,CPU将算子任务提交给GPU之后,不会等GPU完成计算,而是直接返回并开始执行下一条Python指令。
这种执行机制被称为异步执行机制。 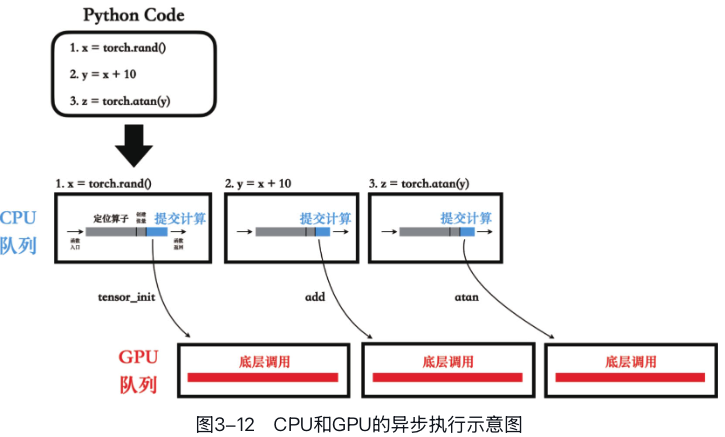 #### 运行时间陷阱
如果我们在CPU任务结束后立即停止计时,并惊讶地发现程序运行得出奇地快,这就不免中了CPU的圈套。
如图3-13所示,当我们打印出“CPU
Finished”的时候,GPU还在后台默默地负重前行呢。 上述CPU -
GPU协同工作机制被称为异步执行机制,其核心特点在于CPU提交任务给GPU后,不等待GPU任务完成而直接返回,继续执行下一个CPU任务或下一条Python代码。
然而在很多任务中我们还是希望等待GPU完成计算的,包括而不限于测试程序的运行时间、打印计算结果等。
这时我们就需要手动调用PyTorch提供的CPU-GPU同步接口,比如torch.cuda.synchronize(),如图3-14所示。
#### 运行时间陷阱
如果我们在CPU任务结束后立即停止计时,并惊讶地发现程序运行得出奇地快,这就不免中了CPU的圈套。
如图3-13所示,当我们打印出“CPU
Finished”的时候,GPU还在后台默默地负重前行呢。 上述CPU -
GPU协同工作机制被称为异步执行机制,其核心特点在于CPU提交任务给GPU后,不等待GPU任务完成而直接返回,继续执行下一个CPU任务或下一条Python代码。
然而在很多任务中我们还是希望等待GPU完成计算的,包括而不限于测试程序的运行时间、打印计算结果等。
这时我们就需要手动调用PyTorch提供的CPU-GPU同步接口,比如torch.cuda.synchronize(),如图3-14所示。
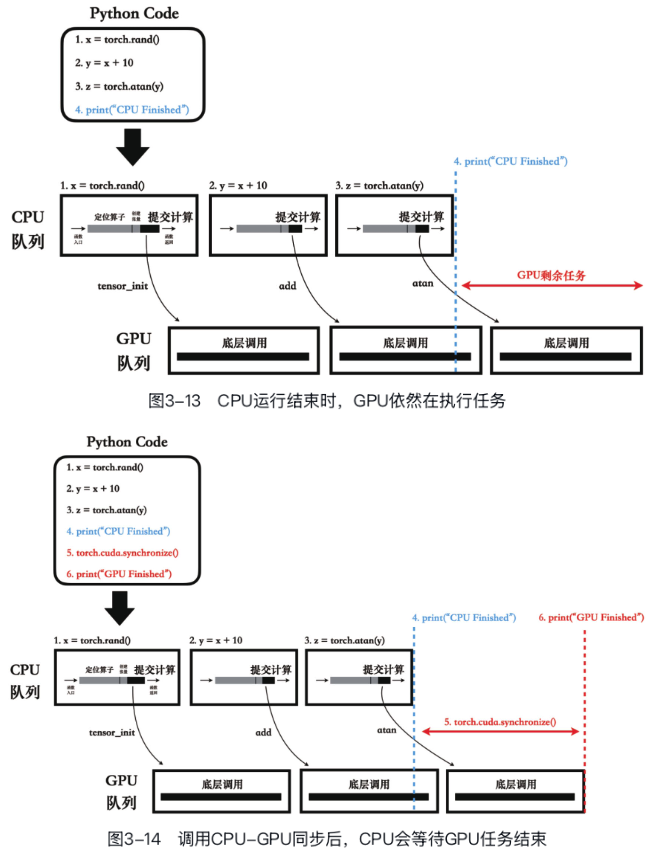
除了来自用户的手动显式调用同步操作,PyTorch的一些操作也会隐式地调用同步操作。 比如,当我们调用torch.nn.functional.softmax()时,PyTorch会自动将计算任务提交给GPU,并隐式地调用torch.cuda.synchronize()。



