数据接入准备
对于一些经典任务可以从公共数据集中抽取小规模子集来快速进行收敛性验证,排除代码错误。
### 常用公开数据集 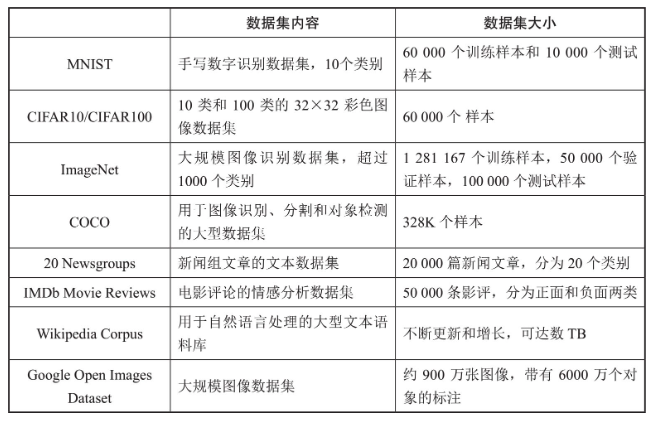
数据集的获取和预处理
获取原始数据
主要包含两个来源: - 公开数据集 - 自定义数据集
原始数据的清洗
一个算法工程师必须具备的关键能力之一是对数据的敏感度:对于特定任务,能够判断数据集可能存在的问题,知道理想数据应呈现的形态,能组织高质量的数据集,并能验证数据的质量。
对于深度学习数据来说,我们可以将数据按照有无标签进行分类。
无标签的数据一般用于无监督学习,这类数据的问题往往出在部分数据自身质量较差。这里只列举一些常见情况: - 图片/视频/图形类数据:低分辨率、高噪声、高曝光。 - 文本类数据:不符合自然语言,含有奇怪的符号、标点、特殊数值等。
有标签的数据则往往用于监督学习,在数据本身质量差的基础上,还会出现标签和数据对不上的问题,也就是所谓的“货不对版”,比如说图片的分类不正确,或者图片的描述不合适。除此以外,还有可能出现一对多的错误,比如同样的图片被贴上了相互冲突的描述等。

大部分数据清洗工作都依赖于脚本进行。为了写作这样的脚本,我们首先要做的是为脏数据划定一条明确的界限。 在对数据进行检查时,有些标准可以简单读取,比如图片分辨率,但是某些标准可能需要借助其他算法或者预训练模型来对数据进行判断。
另外,直接通过预训练的大模型来对数据进行综合打分也是一种数据清洗的方法,本质上是数据蒸馏,需要保证预训练模型的优质性。
数据的离线预处理
数据预处理主要是为了改善数据的质量和结构,以及针对模型对数据进行适配。一些常见的离线数据预处理步骤包括数值范围的标准化、数据编码、数据增强等。
数值范围的标准化
如最小-最大归一化(min-max scaling)或者缩放到正态分布的标准化(standardization)。
需要注意最小-最大归一化需要考虑数据中是否存在极端值,否则会严重影响数据分布。
数据编码
将非数值数据转换为数值格式的过程,比如数据集中的标签数据一般都需要经过数据编码才能输入到模型中。
均衡数据分布
当数据集中某些类别的样本数量远少于其他类别,这种不平衡有可能导致模型在训练过程中对占多数的类别过度拟合,而无法有效学习到少数类别的特征。
数据增强可以通过对原始数据进行一些变换,生成新的数据,从而增加数据集的多样性,提高模型的泛化能力。 在文本处理中,数据增强包括同义词替换、句子重排等; 在图像处理中,数据增强包括旋转、裁剪、翻转、改变亮度、对比度等,还有一些特殊方法,比如mixup、cutout、cutmix、mosaic等。
Python数据处理库
数据的存储
一般来说,一个数据集由三种类型的数据组成: - 核心数据:比如图片、视频、音频、文本等,根据数据集面向的训练任务而定。 - 数据标签或其他补充信息(可选):比如图片分类数据中,每张图片对应的类别标签;比如图片-文字数据集中每个图片对应的文字描述。 - 数据集信息:比如数据集的版本、原始数据来源、预处理方法、参数等。
数据的存储格式多种多样: 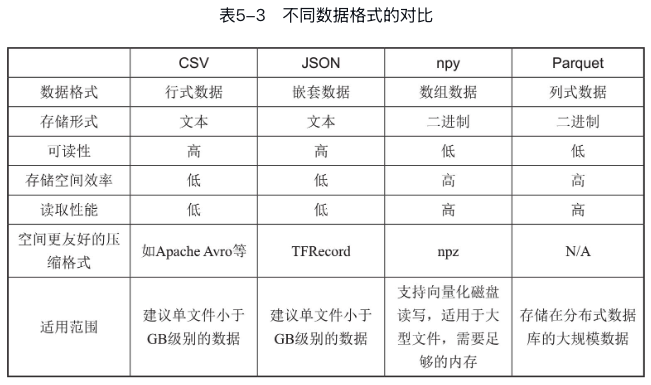
PyTorch与第三方库的交互
通过Python库我们可以将数据从硬盘或服务器上读取到内存中,此时读入内存的数据通常以第三方库数据类型如NumPy ndarray或PIL Image形式存在,PyTorch无法直接解析这些类型。
而无论是第三方库的还是Python原生的,都必须转化为张量后才能用于训练。PyTorch为了便于使用NumPy数据,特别提供了将NumPy ndarray转换为张量的接口。对于其他无直接接口的库如Pandas等,建议先转换为NumPy ndarray再导入到PyTorch。
import numpy as np
import torch
x = np.zeros((3, 3))
y = torch.from_numpy(x)
print(y, type(y))
# tensor([[0., 0., 0.],
# [0., 0., 0.],
# [0., 0., 0.]], dtype=torch.float64) <class 'torch.Tensor'>但是当PyTorch无法复用原始numpy.ndarray的内存时,from_numpy会报错:
import numpy as np
import torch
x = np.random.random(size=(4, 4, 2))
y = np.flip(x, axis=0) # 翻转x的第一个维度,导致stride为负
# 报错
# ValueError: At least one stride in the given numpy array is negative,
# and tensors with negative strides are not currently supported.
# (You can probably work around this by making a copy of your array with array.copy().)
torch.from_numpy(y)
# 创建副本后能够正常运行
torch.from_numpy(y.copy())数据集的加载与使用
一般的串行加载方法:使用json、csv等库函数读取标签信息,使用PIL等库来加载图片数据,最后再使用如tensor.from_numpy()等接口将数据转化为张量数据送入模型。
然而在进行大规模训练的时候,串行的数据加载和预处理就会显著阻塞模型运算,严重影响训练效率,高效的方法是:在模型进行GPU运算的同时,CPU能异步准备好一下轮的训练数据。
PyTorch中使用Dataset类和Dataloader类来支持上述数据加载过程的优化。
Dataset描述了读取单个数据的方法以及必要的预处理,输出的是单个张量。DataLoader则定义了批量读取数据的方法,包括BatchSize、预读取、多进程读取等,输出的结果是一批张量。

Dataset封装
PyTorch框架提供了两种类型的数据集抽象:映射式数据集(map style dataset)和迭代式数据集(iterable style dataset),它们在数据的访问和适用场景上有所不同。
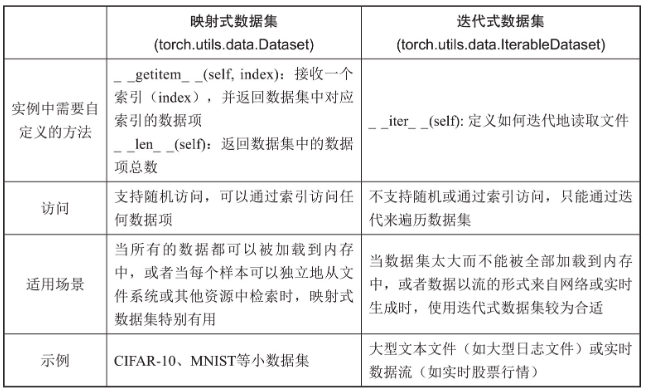
Pytorch已经将许多常见数据集预封装成Dataset类,比如torchvision.datasets.CIFAR10,可以直接调用。
import torchvision.datasets as datasets
import torchvision.transforms as transforms
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.CIFAR10(
root="./data", train=True, download=True, transform=transform
)
test_dataset = datasets.CIFAR10(
root="./data", train=False, download=True, transform=transform
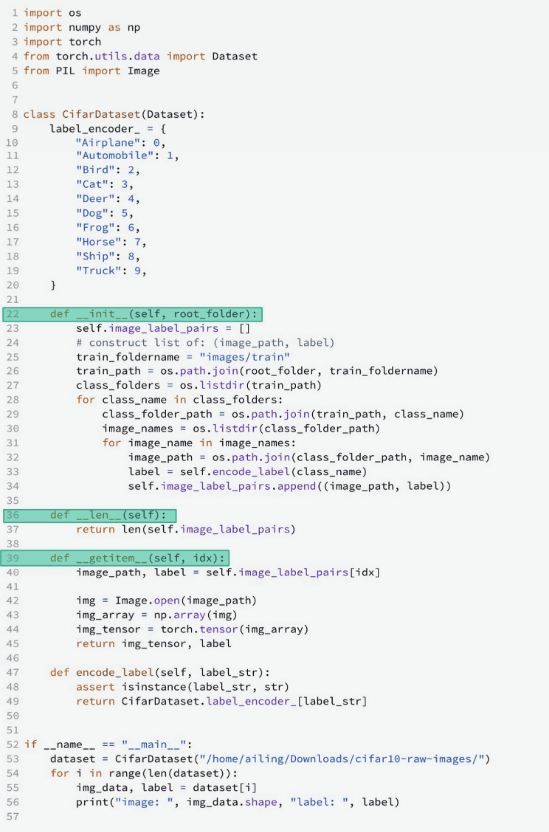
)对于自定义数据集则需要自己对数据进行Dataset封装,我们以本地下载的Cifar10数据集为例,进行Dataset封装。
大概方式是:定义一个继承自Dataset类的CifarDataset。然后为CifarDataset实现下面三个方法: - __init__方法:构造指向每个数据路径的列表,比如在上例中我们构造了“图片路径-标签”的列表。我们没有直接读取图片,这是防止内存被过多数据挤爆。 - __len__方法:返回数据集中的样本数。 - __getitem__方法:根据索引读取图片数据,并将数据转换为PyTorch张量。
DataLoader封装
与模型训练相关的数据加载操作,如对数据集进行采样并批量加载数据、使用多个子进程来并行加载数据等都在Dataloader类中有良好的实现和封装。
 - batch_size:指定每个批次中的样本数量。 -
shuffle:是sampler参数的“快捷键”。shuffle=False相当于顺序采样,即sampler=SequentialSampler;而shuffle=True相当于随机采样即sampler=RandomSampler。如果需要自定义更为复杂的采样策略,用户也可以实现一个Sampler类,并指定Dataloader的sampler参数。
- num_workers:加载数据时使用的子进程数量。 -
drop_last:当数据集中的样本数量不能被batch_size整除时,是否忽略最后一个不完整的批次。
- batch_size:指定每个批次中的样本数量。 -
shuffle:是sampler参数的“快捷键”。shuffle=False相当于顺序采样,即sampler=SequentialSampler;而shuffle=True相当于随机采样即sampler=RandomSampler。如果需要自定义更为复杂的采样策略,用户也可以实现一个Sampler类,并指定Dataloader的sampler参数。
- num_workers:加载数据时使用的子进程数量。 -
drop_last:当数据集中的样本数量不能被batch_size整除时,是否忽略最后一个不完整的批次。
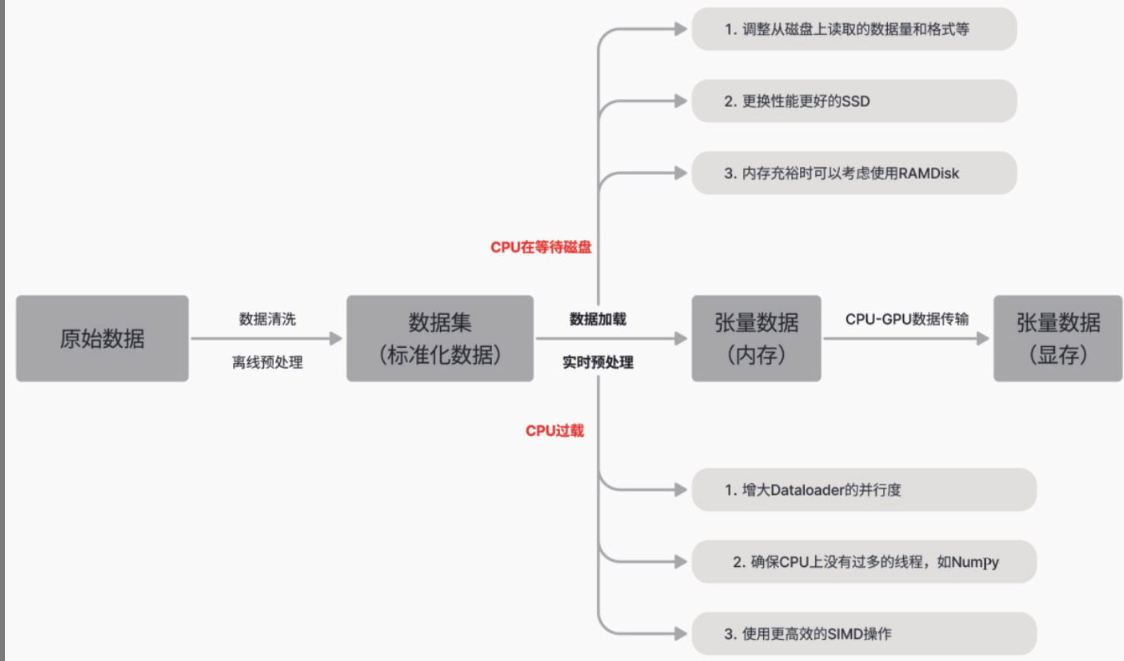
数据加载性能分析
首先需要明确数据部分的性能优化目标是保持GPU持续工作,避免因数据等待导致GPU空闲。GPU空闲可能由多种因素引起,如从硬盘读取数据到内存的延时、CPU预处理时间过长,或是数据从CPU传输到GPU的速度慢等。
注意只需优化到确保GPU运行不被阻塞,在GPU任务已经排队的情况下,过度提交任务不仅不会提升GPU的运行速度,还可能因CPU资源争夺而引起性能下降。
充分利用CPU的多核资源
使用htop命令查看CPU活动状态,如果有“一核工作,多核围观”的情况,则说明CPU的核数没有充分利用,可以通过增加num_workers来充分利用CPU的多核资源。
但是要注意子进程过多可能导致内存占用过多、I/O阻塞等副作用。
优化CPU上的计算负载
如果开启多进程优化后,GPU仍在等待数据,且CPU上的数据加载和处理时间过长,特别是htop中CPU核心都达到满载状态,这说明在CPU上进行的数据预处理和转换的计算量过重,在三方库的实现中很常见。
这时也还有优化空间,比如: - 使用更高效的第三方算法或库,如使用Pillow-SIMD(单指令多数据)替换Pillow; - 把计算密集型的数据处理转为离线预处理,把转换后的数据存储在硬盘上备用; - 如果有一些确实无法预先进行处理的操作,可以考虑将该操作从CPU移至计算能力更强大的GPU进行。
减少不必要的CPU线程
Numpy的线程池
Numpy的计算操作默认会使用CPU的多线程,往往会把CPU全部核心集中在自己身上,挤占其他进程的计算资源。
一种常见情况是NumPy与PyTorch DataLoader的数据加载进程发生冲突。DataLoader使用多个进程加载数据,每个数据加载进程在import numpy的时候都会为NumPy独立地创建N(N = CPU核数)个线程,过多的CPU线程会导致内存使用增加、不必要的上下文切换开销和资源的争用,从而降低程序的执行效率。
因此我们建议使用NumPy进行预处理的读者适当地限制NumPy的线程数量,这可以通过设置环境变量来实现,但请注意该操作一定要在import numpy之前,代码如下:
from os import environ
# 控制NumPy底层库创建的线程数量
N_THREADS = "4"
environ["OMP_NUM_THREADS"] = N_THREADS
environ["OPENBLAS_NUM_THREADS"] = N_THREADS
environ["MKL_NUM_THREADS"] = N_THREADS
environ["VECLIB_MAXIMUM_THREADS"] = N_THREADS
environ["NUMEXPR_NUM_THREADS"] = N_THREADS
import numpy as np
import pdb
pdb.set_trace()
x = np.zeros((1024, 1024))可以通过iostat工具检测磁盘的I/O负载:
iostat -xtck 2 # 每隔2秒输出一次磁盘I/O负载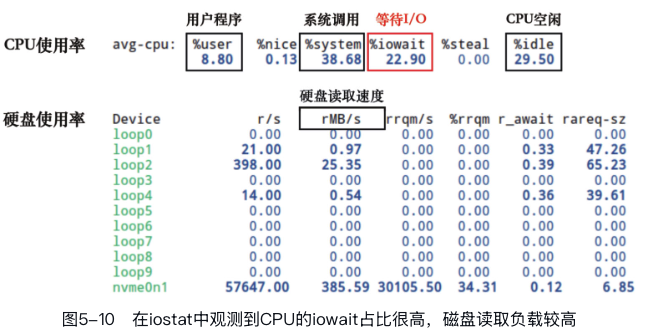
I/O占比过高,说明存储设备成为瓶颈,可以考虑以下思路缓解: - (1)用内存来换取显著提高的数据加载速度:例如使用mmap将文件的一部分直接映射到内存中,然后通过指针访问文件中的数据,而无须显式的I/O操作。这减少了I/O操作的开销,提高了数据访问速度。特别是在随机访问文件的不同部分时,mmap表现出色。当然在内存容量允许的情况下甚至可以考虑使用内存盘(RAMDisk)技术,使用RAM来虚拟磁盘,用内存来换取显著提高的数据加载速度。 - (2)优化硬盘的读写模式:在2.2小节中,我们介绍了硬盘的两种读写模式,其中连续读写模式的性能远超随机读写模式。因此,我们可以通过将离散数据合并到少量的二进制文件或TFRecord中,将随机读写转化为连续读写,从而成倍地提高读写效率。 - (3)更换更快的SSD硬件:如NVMe SSD等。
小结