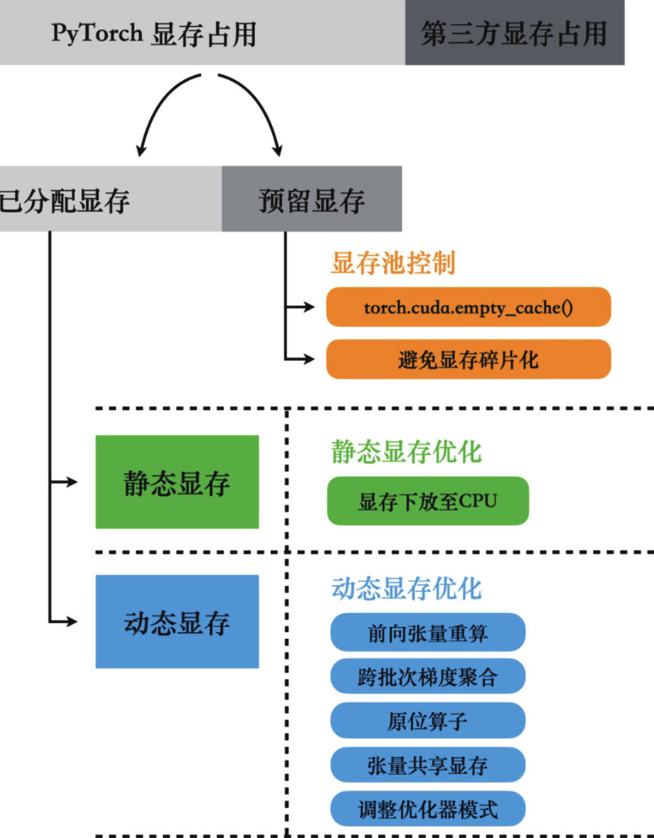
Pytorch的显存管理机制
显存池机制: 每当需要为张量分配显存时,PyTorch不会只申请张量所需的显存大小,而是向驱动一次性申请一块更大的显存空间,这样多出来的显存空间就会被显存池缓存下来。 除此以外,任何张量在销毁后,其占用的显存空间也不会直接归还给GPU驱动,而是同样被显存池缓存下来。
这样的好处在于,当需要再次为新张量分配显存时,就可以从显存池的缓存中进行分配,而不需要效率低下的GPU驱动来从GPU内存中申请。

但是显存池会导致PyTorch总是占用比实际需求更多的显存。大部分情况下显存池额外占用的显存不会太大,但是一旦进行了删除模型、删除大体积张量等释放大量显存的操作后,被缓存下来而无法释放的显存量就非常大了,甚至会影响程序的后续执行。这时需调用torch.cuda.empty_cache()接口,尽可能释放所有完全空闲的显存段。
但是torch.cuda.empty_cache()接口只能释放完全空闲的显存段,而显存池中还可以存在一些碎片段(整个显存段中只有小部分空间被占用)。
通过调小环境变量PYTORCH_CUDA_ALLOC_CONF来拒绝PyTorch分割比该参数大的显存段,可以在显存段剩余空间已经很小时阻止PyTorch继续分割,从而有效阻止显存碎片化。
export PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:128显存的分析方法
Pytorch显存分析API
除了使用nvidia-smi查看显存占用,Pytorch还提供了一些API来查询显存实时数据:
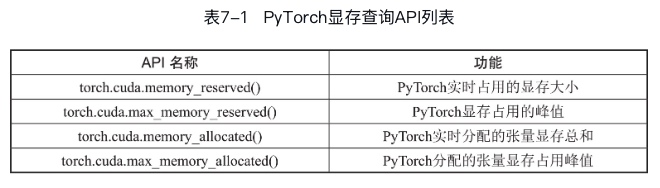 reserved表示PyTorch实际预留的显存大小,但这些预留的显存不一定会立即使用;而allocated表示实际分配给张量的显存。
reserved表示PyTorch实际预留的显存大小,但这些预留的显存不一定会立即使用;而allocated表示实际分配给张量的显存。
import torch
t1 = torch.randn([1024, 1024], device="cuda:0") # 4MB
shape = [256, 1024, 1024, 1] # 1024MB
t2 = torch.randn(shape, device="cuda:0")
print(
f"PyTorch reserved {torch.cuda.memory_reserved()/1024/1024}MB, allocated {torch.cuda.memory_allocated()/1024/1024}MB"
)
# PyTorch reserved 1044.0MB, allocated 1028.0MB一般我们会更加关注如何将峰值显存限制在OOM的边缘,所以cuda.max_memory_allocated()和cuda.max_memory_reserved()这两个API会更有参考价值。
注意使用以上API只能查询Pytorch的显存占用,可能还有其他第三方库调用来CUDA
API来分配管理显存,此时需要使用nvidia-smi来查看。
Pytorch显存分析器
我们还可以利用PyTorch的torch.cuda.memory._record_memory_history()和torch.cuda.memory._dump_snapshot()功能来绘制显存占用在训练过程中的变化曲线。
import torch
torch.cuda.memory._record_memory_history()
with torch.inference_mode(): # 禁用所有与反向传播相关的额外显存分配操作
shape = [256, 1024, 1024, 1]
x1 = torch.randn(shape, device="cuda:0")
x2 = torch.randn(shape, device="cuda:0")
# Multiplication
y = x1 * x2
torch.cuda.memory._dump_snapshot("traces/vram_profile_example.pickle")将结果上传到PyTorch Memory
Visualization,可以得到显存占用在训练过程中的变化曲线。 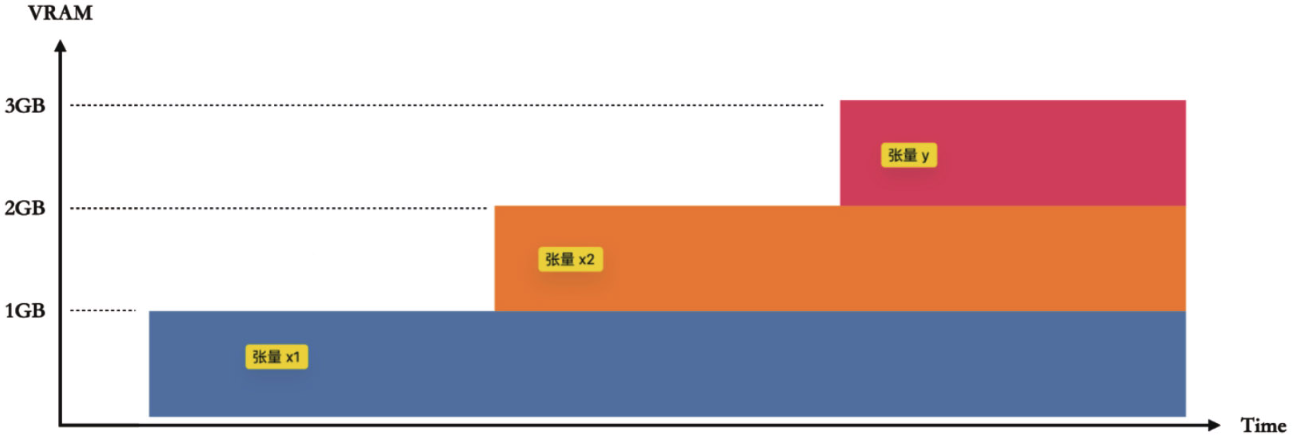 点击条幅触发相应显存分配的程序调用栈,从而了解该显存分配与哪些Python代码对应。
点击条幅触发相应显存分配的程序调用栈,从而了解该显存分配与哪些Python代码对应。
训练过程中的显存占用
训练时的显存占用主要分为两类: - 静态占用:模型参数、优化器状态、梯度等固定占用 - 动态占用:临时显存占用(中间激活值等)
import torch
torch.cuda.memory._record_memory_history()
with torch.inference_mode():
shape = [256, 1024, 1024, 1]
weight = torch.randn(shape, device="cuda:0") # (1)
data = torch.randn(shape, device="cuda:0") # (2)
x = data * weight # (3)
x = x * weight # (4)
x = x.sum()
torch.cuda.memory._dump_snapshot("traces/double_muls_inference.pickle")示例代码的显存占用图: 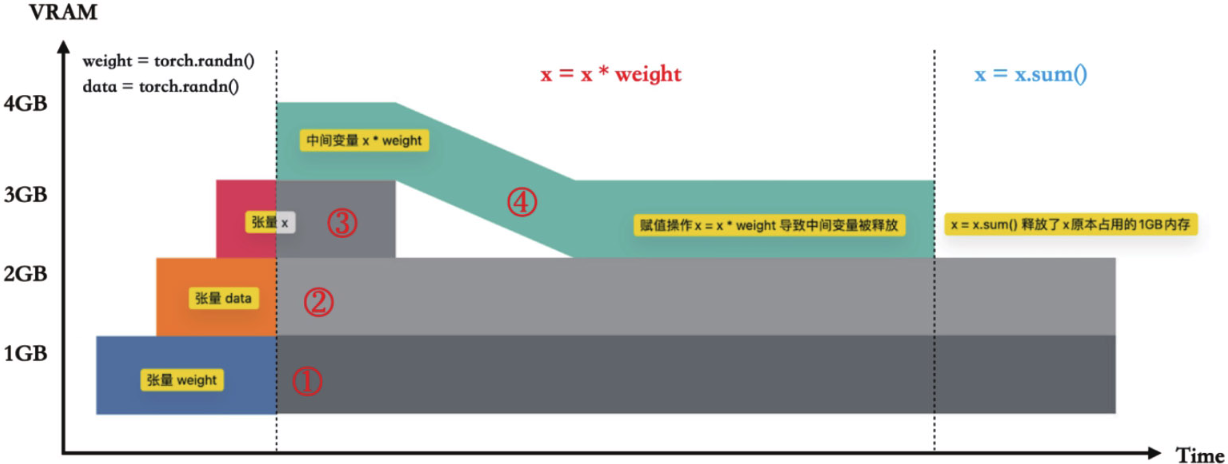
再结合反向过程看看完整的显存占用:
import torch
import torch.optim as optim
torch.cuda.memory._record_memory_history()
shape = [256, 1024, 1024, 1]
weight = torch.randn(shape, requires_grad=True, device="cuda:0")
data = torch.randn(shape, requires_grad=False, device="cuda:0")
x = data * weight
x = x * weight
x = x.sum()
torch.cuda.memory._dump_snapshot("triple_muls_fwd.pickle")
optimizer = optim.SGD([weight], lr=0.01)
optimizer.zero_grad()
x.backward()
optimizer.step()
torch.cuda.memory._dump_snapshot("traces/double_muls_full.pickle")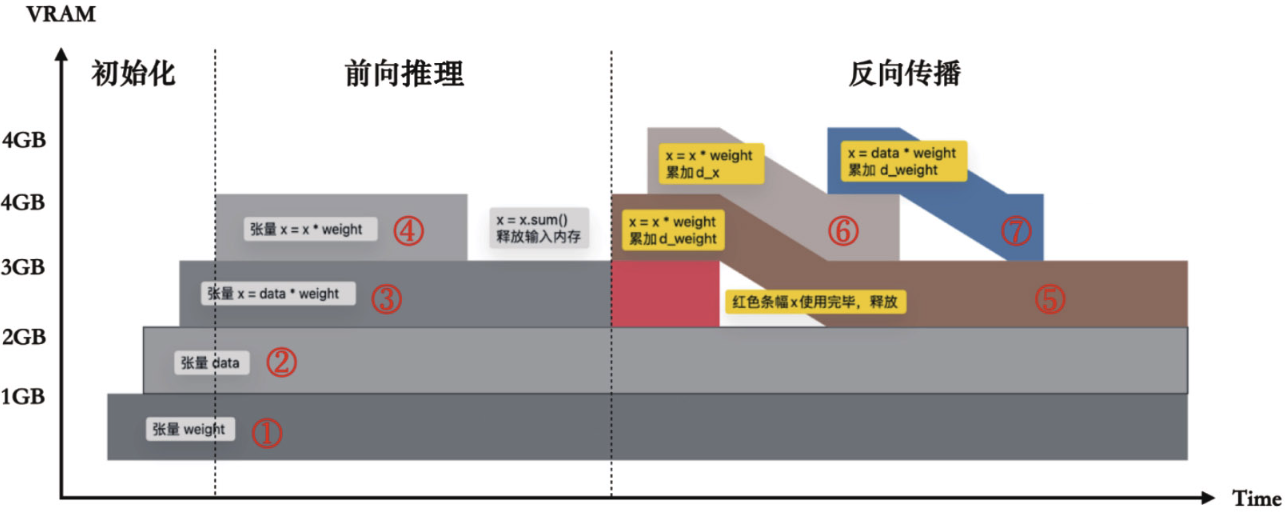
注意与之前不同的是,红色条幅在此过程中的存在时间更长,一直持续到反向传播的中段才结束。红色条幅代表x = x weight中临时输出变量的显存,没有在运算结束后立刻释放的原因在于,x = x weight里的乘法算子需要保存输出张量的数值以进行反向计算,所以这个临时变量被保存到了反向算子的成员中(见下述公式)。 \[ [MulForward]out=x*y [MulBackward]d_x=d_out*y [MulBackward]d_y=d_out*x \]
通用显存复用方法
使用原位操作算子
PyTorch还提供了一系列的原位操作算子。这些算子的特点是它们直接对输入张量的显存进行修改,而不需要为输出张量分配额外的显存,从而显著降低算子调用的显存占用。
但是如果在计算梯度时,反向传播算法依赖于前向传播中的某个张量,而这个张量被原位操作修改过,那么梯度的计算就可能出现错误。 为了应对这种情况,PyTorch引入了一种基于版本的检查机制。每当张量的值通过原位操作发生改变,它的版本号就会增加。在进行反向传播时,如果发现所依赖的张量版本已经不是最新的,则会立即停止并抛出错误信息。这种机制确保了梯度计算的准确性和数据的一致性。
使用共享存储
Pytorch在将一个张量赋值给另一个张量时,一般是浅拷贝,即共享同一块显存。
除了赋值操作外,PyTorch还提供了视图(view)操作,与赋值操作中仅仅创建一个张量的引用不同,视图操作返回的是一个新的张量,该张量与输入张量共享底层的显存数据(子集数据)。 ## 有代价的显存优化技巧 ### 跨批次梯度累加 如果受限于硬件资源,无法达到理想的BatchSize,可以通过牺牲一些训练速度来增加BatchSize,即使用跨批次梯度累加(cross-batch gradient accumulation)。 这种方法的核心是降低优化器梯度更新的频率——通过累积多轮训练的梯度,最后再一起更新,从而实现增大BatchSize的效果。
import torch
import torch.optim as optim
torch.manual_seed(1000)
N = 128
Total_N = 512
dataset = torch.randn([Total_N, 32, 1024], requires_grad=False)
weight = torch.randn([1024, 32], requires_grad=True, device="cuda:0")
optimizer = optim.SGD([weight], lr=0.01)
num_iters = int(Total_N / 256)
steps = 2
for i in range(num_iters):
# ---------------模拟一个批次的训练start---------------
optimizer.zero_grad()
for j in range(steps):
offset = i * 256 + N * j
input = dataset[offset : offset + N, :, :].to(torch.device("cuda:0"))
y = input.matmul(weight)
loss = y.sum()
loss.backward()
optimizer.step()
# ---------------模拟一个批次的训练end---------------
print(weight.sum())
print(f"显存分配的峰值: {torch.cuda.max_memory_allocated()/1024/1024}MB")
# 输出:
# tensor(2096.2283, device='cuda:0', grad_fn=<SumBackward0>)
# 显存分配的峰值: 49.00048828125MB即使重算前向张量
PyTorch通常会将某些前向张量直接存储到反向算子中,以便在反向传播时使用。这会导致这些前向张量无法被释放,持续占用显存直到相应的反向计算完成为止。
此时可以通过torch.utils.checkpoint接口来做到这一点,在反向传播时重新计算这些前向张量,而不是直接存储它们。
import torch
import torch.nn as nn
from torch.utils.checkpoint import checkpoint_sequential
model = nn.Sequential(
nn.Linear(1000, 40000),
nn.ReLU(),
nn.Linear(40000, 1000),
nn.ReLU(),
nn.Linear(1000, 5),
nn.ReLU(),
).to("cuda")
input_var = torch.randn(10, 1000, device="cuda", requires_grad=True)
segments = 2
modules = [module for k, module in model._modules.items()] # 将模型分成若干段,在每段的前向传播结束后丢弃中间激活值,并在反向传播时重新计算这些值。
# (1). 使用checkpoint技术
out = checkpoint_sequential(modules, segments, input_var)
model.zero_grad()
out.sum().backward()
print(f"使用checkpoint技术显存分配峰值: {torch.cuda.max_memory_allocated()/1024/1024}MB")
# 使用checkpoint技术显存分配峰值: 628.63671875MB
out_checkpointed = out.data.clone()
grad_checkpointed = {}
for name, param in model.named_parameters():
grad_checkpointed[name] = param.grad.data.clone()
# (2). 不使用checkpoint技术
original = model
x = input_var.clone().detach_()
out = original(x)
out_not_checkpointed = out.data.clone()
original.zero_grad()
out.sum().backward()
print(f"不使用checkpoint技术显存分配峰值: {torch.cuda.max_memory_allocated()/1024/1024}MB")
# 不使用checkpoint技术显存分配峰值: 936.17431640625MB
grad_not_checkpointed = {}
for name, param in model.named_parameters():
grad_not_checkpointed[name] = param.grad.data.clone()
# 对比使用和不使用checkpoint技术计算出来的梯度都是一样的
assert torch.allclose(out_checkpointed, out_not_checkpointed)
for name in grad_checkpointed:
assert torch.allclose(grad_checkpointed[name], grad_not_checkpointed[name])将GPU显存下放至CPU内存
- 模型参数下放:当模型太大而无法完全装入显存时,可以将部分模型参数、优化器参数暂时存储在内存中。在训练过程中,只在有需要的时候临时加载到显存里,计算完成后马上从显存中移除。
- 激活张量下放:训练过程中产生的所有激活张量默认存储在内存中,只在需要参与计算时才加载到显存里,计算完成后将所有激活张量再次存放回内存。
import torch
import torch.nn as nn
class LargeModel(nn.Module):
def __init__(self):
super(LargeModel, self).__init__()
self.layer1 = nn.Linear(50000, 50000)
self.layer2 = nn.Linear(50000, 50000)
# OOM on a GPU with 24GB
# def forward(self, x):
# x = self.layer1(x)
# x = torch.relu(x)
# x = self.layer2(x)
# x = torch.relu(x)
# return x
def forward(self, x):
self.layer1.to("cuda")
x = self.layer1(x)
x = torch.relu(x)
self.layer1.to("cpu")
self.layer2.to("cuda")
x = self.layer2(x)
x = torch.relu(x)
self.layer2.to("cpu")
return x
model = LargeModel().to("cuda")
input_data = torch.randn(10, 50000).to("cuda")
output = model(input_data)
print(f"前向过程中GPU显存占用峰值: {torch.cuda.max_memory_allocated()/1024/1024/1024}GB")
# 前向过程中GPU显存占用峰值: 9.328798770904541GB
loss = output.sum()
loss.backward()动态下放-加载的主要性能瓶颈是CPU和GPU之间的数据传输。如果数据传输不够高效,则一定会对性能产生很大影响。因此需要在数据传输延迟和显存节约之间做好平衡。PyTorch和相关的生态系统(如NVIDIA的Apex库)提供了一些工具来帮助用户实现上述动态下放-加载资源的策略,以便在有限的资源下训练大型模型。
降低优化器的显存占用
优化器往往也是显存占用的大头,这里主要来源有两个:一个是优化器内置的状态变量,另一个则是优化器进行参数更新时的运行内存占用。
可以通过optimizer.state_dict()接口查看优化器为每个参数保存的状态变量。对于显存非常紧张的情况,选择占用额外显存较少的优化器,如SGD等,可以帮助快速突破显存瓶颈,但会对结果产生影响。
另外,之前介绍过PyTorch优化器的不同计算模式,也就是for-loop、for-each、fused三种不同的实现方法。这三种方法本质上是在性能和显存之间寻找一种平衡,其中for-loop显存用量最少,当然代价是其性能也是三种模型里最差的。
优化Python代码减少显存占用
Python垃圾回收机制
Python存在两层垃圾回收机制。
第一层机制通过引用计数来判定变量是否为垃圾。简单来说,一个变量每被使用一次,其计数增一;每次使用完毕,计数减一。当计数为0时,该变量就会被回收。 然而,一旦出现相互之间循环引用的变量时,它们的引用计数永远不会下降到零,为此,Python又引入了第二层循环垃圾回收机制。
循环垃圾回收机制实现了检测循环依赖的算法,能够打破循环依赖对引用计数造成的破坏。该机制的触发时机是不固定的,它依赖于自上次垃圾回收以来分配的新变量数量。实际上,该机制还包括变量年龄组和不同的阈值设置,但这些细节已经超出了本章讨论范围。我们只需要知道循环垃圾回收机制的触发频率不高,不能保证资源被即时释放掉。 ### 避免出现循环依赖 循环依赖常见于PyTorch编程中自定义Python类型的相互嵌套,特别是在子节点持有对父节点的引用情况。以下代码展示了这种情况:
import torch
import gc
class Module1(torch.nn.Module):
def __init__(self):
super(Module1, self).__init__()
self.saved = Module2(self) # Module1对象保存了对Module2对象的引用
self.tensor = torch.randn(1024, 1024, device="cuda")
class Module2(torch.nn.Module):
def __init__(self, module):
super(Module2, self).__init__()
self.saved = module # Module2对象也保存了对Module1对象的饮用
self.tensor = torch.randn(1024, 1024, device="cuda")
net = Module1()
print("Memory allocated: ", torch.cuda.memory_allocated(0))
del net # 即便使用del命令手动删除变量,也不能立即释放其资源。
print("Memory allocated after delete: ", torch.cuda.memory_allocated(0))
gc.collect() # 手动触发循环垃圾回收机制,这时才能释放被卷入循环依赖的变量们
print("Memory allocated after gc: ", torch.cuda.memory_allocated(0))再来看看以下这个例子,开发者可能会使用self.model = model等写法,让自定义类型持有model变量,从而方便随时访问。然而,一旦使用不当就会导致循环依赖:
import torch
class CustomLayer(torch.nn.Module):
def __init__(self, model):
super(CustomLayer, self).__init__()
self.model = model # 自定义类型持有model变量
class MyModel(torch.nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.custom_layer = CustomLayer(self) # CustomLayer对象持有MyModel对象的引用, 而MyModel对象又持有CustomLayer对象的引用, 从而形成循环依赖。
model = MyModel()谨慎使用全局作用域
除了循环依赖以外,全局作用域中的张量也是导致显存资源不能被释放的重要原因。与局部变量不同,全局变量的生命周期通常延续至程序结束,从而导致持续的资源占用,这是任何垃圾回收机制都不能解决的。
全局变量包括定义在脚本最外层的变量、使用global关键字声明的变量等。
为减少全局变量造成的资源占用,只能通过del手动清理这些变量,清理后显存占用才能降至零。
小结