在单卡GPU训练环境中,性能问题主要分为四类: - GPU被阻塞:这是由于数据预处理或传输任务等前置依赖未完成,导致GPU计算资源空闲等待的情况。 - GPU运行效率不高:这通常是因为GPU上的计算任务设计得不够好,未能充分发挥硬件的计算能力。 - 不必要的GPU与CPU间同步:GPU与CPU之间的同步是一个极其费时的操作,用户有时会在无意中频繁使用同步操作,进而严重降低性能。 - 数据传输带宽不足:在GPU与CPU之间传输数据时,如果带宽不足,就会导致数据传输速度变慢,进而影响训练性能。
提高数据任务的并行度
- CPU的预处理要足够快,能够及时给GPU提交计算任务,确保GPU上有大量计算任务在排队,始终有活可以干。
- GPU任务需要的数据总能够在它开始执行前就传输到显存。这样可以尽量减少GPU的空闲时间,让其始终保持在计算状态。
增加数据预处理的并行度
通过增加DataLoader的num_workers参数,可以增加数据预处理的并行度。
案例:
import torch
from torch import nn
from torch.profiler import profile, ProfilerActivity
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(512, 10000)
self.fc2 = nn.Linear(10000, 1000)
self.fc3 = nn.Linear(1000, 10)
def forward(self, x):
out = self.fc1(x)
out = self.fc2(out)
out = self.fc3(out)
return out
assert torch.cuda.is_available()
device = torch.device("cuda")
model = SimpleNet().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
def train(model, optimizer, trainloader, num_iters):
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for i, batch in enumerate(trainloader, 0):
if i >= num_iters:
break
#------同步模式-------------------------#
data = batch[0].cuda()
#------非阻塞模式------------------------#
# data = batch[0].to("cuda", non_blocking=True)
# 前向
optimizer.zero_grad()
output = model(data)
loss = output.sum()
# 反向
loss.backward()
optimizer.step()
prof.export_chrome_trace(f"traces/PROF_workers_{trainloader.num_workers}.json")
#-----------提高数据预处理并行度---------------#
num_workers = 0
#-------------------------------------------#
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Resize([512, 512])]
)
trainset = CIFAR10(root="./data", train=True, download=True, transform=transform)
#----------默认在页内存中加载数据---------------#
trainloader = DataLoader(trainset, batch_size=32, num_workers=num_workers)
#------------在锁页内存中加载数据---------------#
#trainloader = DataLoader(trainset, batch_size=32, num_workers=num_workers, pin_memory=True)
train(model, optimizer, trainloader, num_iters=20)如果num_workers=0,性能图谱如下: 
可以看出GPU在MemcpyHtoD的数据拷贝任务之前在等待CPU的数据加载,导致GPU空闲。
如果num_workers=4,性能图谱如下:  明显观察到数据加载的耗时大幅下降,与此同时GPU等待数据加载的时间也缩短到了只有40μs,远低于之前的10ms,这正是多进程并行以及数据预加载共同作用的结果。
明显观察到数据加载的耗时大幅下降,与此同时GPU等待数据加载的时间也缩短到了只有40μs,远低于之前的10ms,这正是多进程并行以及数据预加载共同作用的结果。
使用异步接口提交数据传输任务
GPU在MemcpyHtoD的数据拷贝任务之后到执行具体的算子计算之前,还存在一个空闲时间。
CPU数据传输任务aten::to中,包含了一个同步操作,即cudaStreamSynchronize,这意味数据从主存到显存的拷贝是会阻塞CPU的。
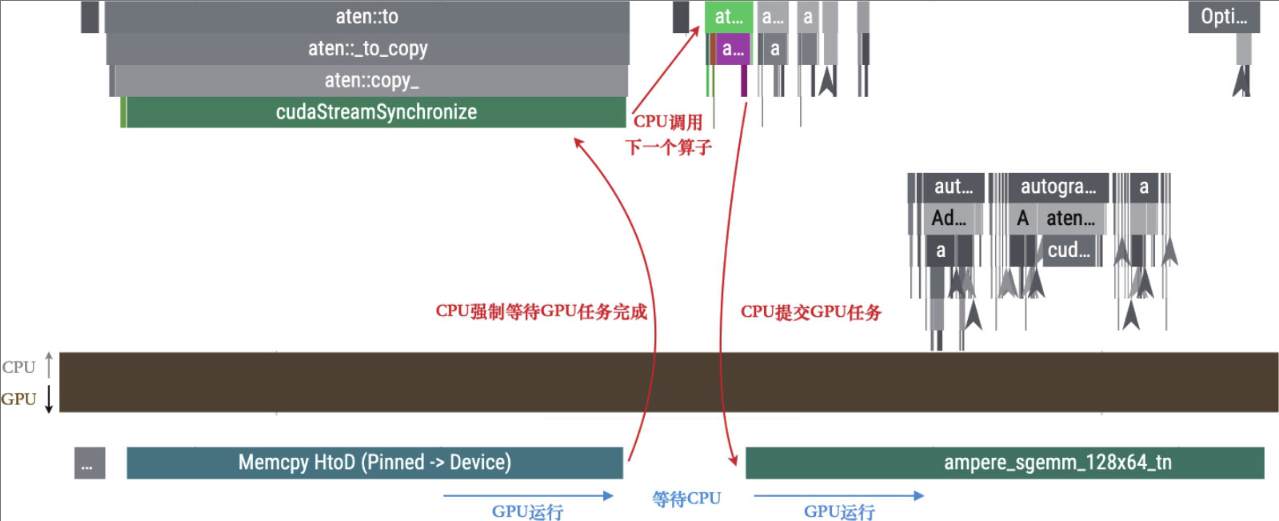
这时因为代码中使用了tensor.to(device)的方法将张量从CPU复制到GPU,默认采取的是同步模式。
为了实现启用非阻塞模式的数据传输(允许在向GPU传输数据的同时,CPU能够继续执行其他任务。),必须同时满足下面两个条件: - 需要传输的数据必须存储在锁页内存(pinned memory)中。锁页内存的物理地址是固定的,不会被操作系统换出到磁盘,从而允许GPU直接访问这部分内存。在PyTorch中创建的张量默认是常规的页内存(pageable memory),但可以通过DataLoader的设置直接将数据加载到锁页内存,或使用tensor.pin_memory()方法手动将张量移动到锁页内存。 - 在调用数据传输时需要设置为非阻塞模式,如tensor.to("cuda",non_blocking=True)。这样数据传输的任务会被提交到GPU的任务队列中,CPU则不需要等待数据传输完成即可继续执行后续代码。
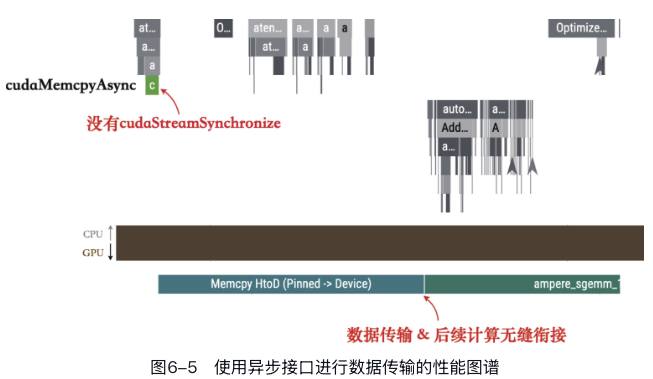
数据传输与GPU计算任务并行
现在GPU在进行数据拷贝与计算时可以无缝衔接了,但是有没有可能让这个两个任务并行起来呢?
我们可以采取类似CPU预加载数据的策略:在当前训练轮次进行的同时,预先把下一轮训练所需的数据从CPU复制到GPU上。要做到这一点,我们需要通过配置不同的GPU计算流(CUDA Stream)来创建一个并行的数据拷贝任务。
def train(model, optimizer, trainloader, num_iters):
# Create two CUDA streams
stream1 = torch.cuda.Stream()
stream2 = torch.cuda.Stream()
submit_stream = stream1
running_stream = stream2
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for i, batch in enumerate(trainloader, 0):
if i >= num_iters:
break
with torch.cuda.stream(submit_stream):
data = batch[0].cuda(non_blocking=True)
submit_stream.wait_stream(running_stream)
# Forward pass
optimizer.zero_grad()
output = model(data)
loss = output.sum()
# Backward pass and optimize
loss.backward()
optimizer.step()
# Alternate between the two streams
submit_stream = stream2 if submit_stream == stream1 else stream1
running_stream = stream2 if running_stream == stream1 else stream1
prof.export_chrome_trace(f"PROF_double_buffering_wait_after_data.json")引入了submit_stream.wait_stream(running_stream)来进行GPU队列间的同步和等待,保证两个GPU队列的重叠部分仅限于数据传输,而计算部分不发生重叠。
这一技巧与推理中常用的双重缓冲(double buffering)优化有些相似。

需要注意的是,双重缓冲主要是加快数据的拷贝速度,因此在数据量较小、数据传输用时较短的场景中,效果可能不太明显。此外,它也可能带来GPU队列间同步的额外开销,有时可能会导致性能略有下降。
提高GPU计算任务的效率
我们可以用模型浮点运算利用率(model FLOPS utilization,MFU)来衡量GPU的使用效率:
\[ MFU = \frac{实际使用FLOPS}{GPU理论最高FLOPS} \]
关于GPU计算优化,主要包括: - (1)GPU算子执行时间太短,或算子中的计算过于简单,导致为该算子调度的额外开销甚至超过了计算本身,使得性价比较低。 - (2)GPU算子的并行度不足,未能充分利用GPU中大量的线程块资源导致浪费。 - (3)GPU算子使用了不合适的内存布局,增加了额外的访存开销。 - (4)GPU算子的具体实现还有改进的空间。
本节只讨论针对(1)和(2)进行优化。
最大Batch Size
一个算子的CUDA核函数实现通常只针对输入张量的[C,H,W]维度,而不会直接涉及Batch维度的计算。
也就是说BatchSize与算子CUDA代码的实现是独立的,提升BatchSize并不能直接提升CUDA核函数的性能。然而它可以增加GPU使用的线程块(block)数量,一次性完成多个样本的计算。本质上来说,BatchSize是通过增加计算并行度的方式来提高算子计算效率的。
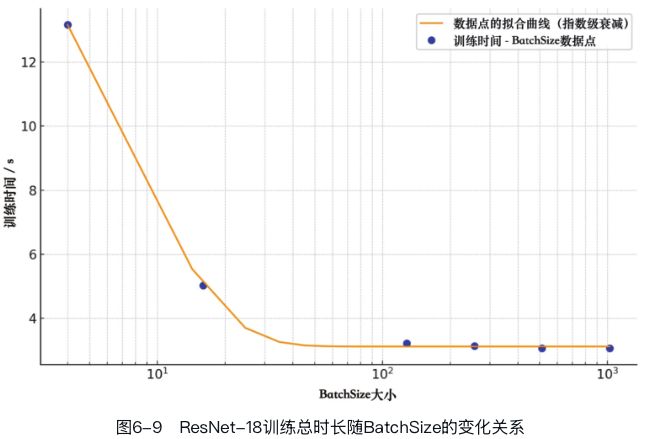 从图中看出BatchSize通过增加GPU的计算并行度来提高性能,但这种并行度受到GPU线程块总数的限制。
从图中看出BatchSize通过增加GPU的计算并行度来提高性能,但这种并行度受到GPU线程块总数的限制。
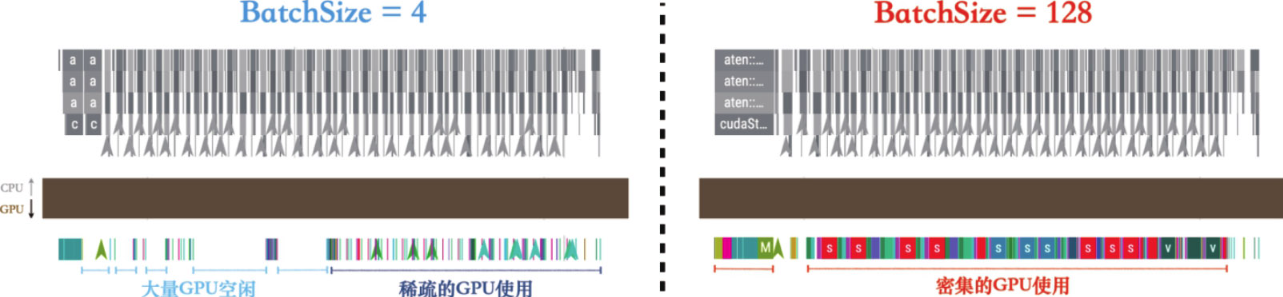
但是较大的BatchSize可能会影响模型的泛化能力,尽管这也受到训练集大小、组成、网络结构和训练方法等因素的影响。
实际上,许多大型模型使用较大的BatchSize,这也表明在大数据集上,较大的BatchSize的负面影响可能会有所减轻。 选择BatchSize时,需要在模型质量和训练速度之间找到平衡。
使用融合算子
PyTorch的灵活性也意味着PyTorch中的GPU算子比较轻量,每个算子调用都需要经过一系列层级的调用流程:从Python到C++,再到CUDA执行,然后将结果返回C++,最后回到Python。
因此,本节将专注于如何通过改变代码写法,合并相邻的算子调用来减少这些调度开销。
一种有效的策略是手动合并算子,这通常需要一定的数学技巧来将多个相邻的算子融合成一个单一的算子。 一个典型的例子是合并多个连续的逐元素操作(elementwise operations),例如:
import torch
x = torch.rand(3, 3)
y = torch.rand(3, 3)
z = x * y
z1 = z + x
# 可以将上面的计算合并为一个算子,结果是等价的
z2 = torch.addcmul(x, x, y) import torch
a = torch.rand(4, 4)
b = torch.rand(4, 4)
c = torch.rand(4, 4)
x = torch.matmul(a, b)
x1 = x + c
# 可以将上面的计算合并为一个算子,结果是等价的
x2 = torch.addmm(c, a, b)除了依靠数学知识手动融合多个算子之外,PyTorch还在torch.nn.utils.fusion模块下提供了一系列常用的算子融合的接口。
例如,fuse_linear_bn_eval接口能够将相邻的Linear算子和BatchNorm算子合并为一个新的Linear算子。
import torch
import torch.nn as nn
from torch.profiler import profile, ProfilerActivity
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.linear = nn.Linear(100, 50)
self.bn = nn.BatchNorm1d(50)
def forward(self, x):
return self.bn(self.linear(x))
@torch.no_grad()
def run(data, model, num_iters, name):
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for _ in range(num_iters):
original_output = model(input_tensor)
prof.export_chrome_trace(f"traces/PROF_cuda_{name}.json")
model = SimpleModel().to(torch.device("cuda:0"))
model.eval()
input_tensor = torch.randn(4, 100, device="cuda:0")
# 融合前
run(input_tensor, model, num_iters=20, name="no_fusion")
# 融合后
fused_model = torch.nn.utils.fusion.fuse_linear_bn_eval(model.linear, model.bn)
run(input_tensor, fused_model, num_iters=20, name="fusion")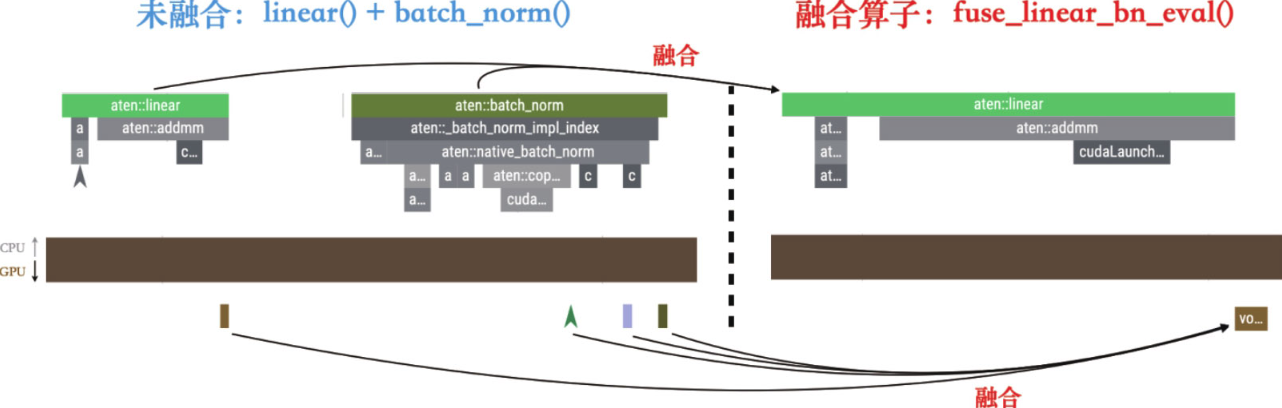
算子融合是优化深度学习网络的一种非常常见的方法,它有助于提升网络运行效率和减少资源消耗。尽管如此,PyTorch的原生接口中并没有提供太多关于算子融合的直接支持,通常需要依赖手动融合算子,而这一过程可能耗时较长。
在实际训练中,常见的算子融合方法包括使用torch.compile和引入高性能自定义算子,但这些方法的原理相对复杂,更详尽的讨论和应用将在后面高级优化方法中进行。
减少CPU和GPU间的同步
PyTorch中的一些写法会隐式地进行同步,这常常是PyTorch程序性能的“隐藏杀手”。绝大多数隐式同步其实有一个共性,那便是想要在Python中使用GPU张量的值。

torch.nonzero()造成同步的例子:
import torch
import torch.nn as nn
from torch.profiler import profile, ProfilerActivity
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = nn.Linear(1000, 5000)
self.linear2 = nn.Linear(5000, 10000)
self.linear3 = nn.Linear(10000, 10000)
self.relu = nn.ReLU()
def forward(self, x):
output = self.relu(self.linear1(x))
output = self.relu(self.linear2(output))
output = self.relu(self.linear3(output))
#----------------隐式同步----------------#
nonzero = torch.nonzero(output)
return nonzero
def run(data, model):
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for _ in range(10):
model(data)
prof.export_chrome_trace("traces/PROF_nonzero.json")
data = torch.randn(1, 1000, device="cuda")
model = Model().to(torch.device("cuda"))
run(data, model)
cudaMemcpyAsync,这是一个GPU到CPU的数据拷贝(memcpy device to host)。 torch.nonzero()算子会返回一个新的张量,其中包含输入张量中所有非零元素的索引,也就是它们在输入张量中的位置。需要确保nonzero的输入张量的值运算完毕,计算出非零元素的个数后再将这个数字从GPU传回CPU上。
降低程序中的额外开销
Python接口调用开销
当我们使用PyTorch的任何操作时,都会触及两层逻辑:一是上层的Python接口,提供灵活性和易用性;二是底层的C++实现,用于保证计算效率。由于第3章提到的PyTorch的CPU和GPU异步执行机制,开发者有时可能不会意识到调用PyTorch API所隐含的性能开销。
在对性能有极高要求的推理场景中,我们可能会考虑放弃使用Python,转而直接采用C++等静态语言,以最小化调度开销。然而,在更加注重灵活性和易用性的训练场景中,我们可以将Python层的额外开销视为一种“易用税”,这是在开发效率和程序性能之间达成平衡的必要成本。
避免张量的创建开销
张量的创建和销毁,特别是涉及显存管理的操作,这些都是开销较大的操作。PyTorch内部的缓存池机制可以在一定程度上改善由动态张量分配引起的性能问题,但它并不能完全解决这一问题。 #### 直接在GPU上创建张量而不是CPU 案例:
import torch
import torch.nn as nn
from torch.profiler import profile, ProfilerActivity
def tensor_creation(num_iters, create_on_gpu):
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
shape = (10, 6400)
for i in range(num_iters):
#------------------------------------------------------------#
if create_on_gpu:
data = torch.randn(shape, device="cuda") # 直接在GPU上创建张量
else:
data = torch.randn(shape).to("cuda") # 先在CPU上创建张量,然后拷贝到GPU
#------------------------------------------------------------#
prof.export_chrome_trace(
f"traces/PROF_tensor_creation_on_gpu_{create_on_gpu}.json"
)
# 情况1. 先在CPU上创建Tensor然后拷贝到GPU
tensor_creation(20, create_on_gpu=False)
# 情况2. 直接在GPU上创建Tensor
tensor_creation(20, create_on_gpu=True)
 在本例中使用torch.randn().to("cuda")的写法耗时265μs,而使用torch.randn(device="cuda")的写法则只需要12μs。
在本例中使用torch.randn().to("cuda")的写法耗时265μs,而使用torch.randn(device="cuda")的写法则只需要12μs。
使用原位操作
大部分PyTorch操作默认会为返回张量创建新的内存,但大部分张量在创造出来之后只使用一次即被销毁,这样多少会造成资源的浪费。
原位操作作不会生成新的输出张量,而是直接在输入张量上进行修改。由于省去了内存的创建过程,原位操作通常在性能上更为高效。
import torch
from torch.profiler import profile, ProfilerActivity
def run(data, use_inplace):
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for i in range(2):
#------------------------------------------------------------#
if use_inplace:
data.mul_(2) # 原位操作,一般以_结尾
else:
output = data.mul(2) # 非原位操作
#------------------------------------------------------------#
prof.export_chrome_trace(f"traces/PROF_use_inplace_{use_inplace}.json")
shape = (32, 32, 256, 256)
# Non-Inplace
data1 = torch.randn(shape, device="cuda:0")
run(data1, use_inplace=False)
# Inplace
data2 = torch.randn(shape, device="cuda:0")
run(data2, use_inplace=True)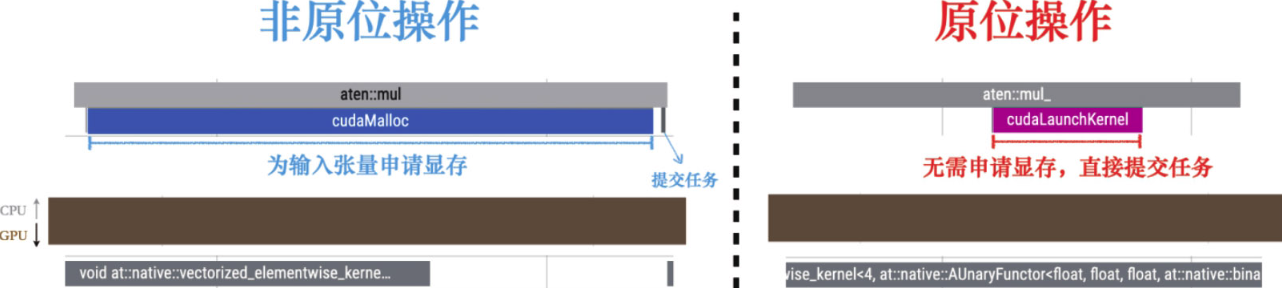
关闭不必要的梯度计算
在某些模型微调的场景中,我们通常在一个预训练的模型上添加一个自定义的小型模块。在这种情况下,预训练模型的参数会被冻结,只对新增的自定义模块进行训练。 对于这部分仅需要前向传播的代码,通常使用torch.no_grad()这个上下文管理器。在这个上下文管理器的范围内,所有创建的张量的requires_grad属性都被标志为False,这些张量参与的计算操作不会被跟踪历史,也就是不会在反向传播中计算梯度。
另一种不需要反向梯度更新的场景是纯推理代码,这样的使用场景下往往所有的代码段都只承担前向传播的任务,整个运行过程中完全不涉及反向传播。 一般此时会将模型设置为评估模式,即调用model.eval()。此操作主要改变某些层的行为:例如,在推理模式下,BatchNormalization层将不会更新统计数据,且Dropout层不会执行随机丢弃功能。这是确保在推理时获得准确结果的必要步骤,尽管它对性能的提升并不显著。
为了加速推理过程,PyTorch提供了torch.inference_mode()接口,这是比torch.no_grad()更为激进的面向推理预测代码的优化,除了不生成反向算子以外,还会关闭一系列只在反向过程起作用的检查或设置,比如原位算子的版本检测机制等。
import torch
import torch.nn as nn
import time
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.conv2(x)
return x
def infer(input_data, num_iters, use_inference_mode):
start = time.perf_counter()
with torch.inference_mode(mode=use_inference_mode):
for _ in range(num_iters):
output = model(input_data)
torch.cuda.synchronize()
end = time.perf_counter()
return (end - start) * 1000
model = SimpleCNN().to(torch.device("cuda:0"))
input_data = torch.randn(1, 3, 224, 224, device="cuda:0")
# ---------------------------------开启Inference Mode---------------------------------#
infer(input_data, num_iters=10, use_inference_mode=True) # warm up
runtime = infer(input_data, num_iters=100, use_inference_mode=True)
print(f"开启Inference Mode用时: {runtime}s")
# ---------------------------------关闭Inference Mode---------------------------------#
infer(input_data, num_iters=10, use_inference_mode=False) # warm up
runtime = infer(input_data, num_iters=100, use_inference_mode=False)
print(f"关闭Inference Mode用时: {runtime}s")有代价的性能优化
使用低精度数据进行拷贝
采用异步方式可以减少GPU等待CPU数据拷贝的时间,但是没有加速拷贝本身,对于大尺寸的输入张量,或者使用很大BatchSize的场景,数据拷贝本身会消耗相当长的时间。
因此可以采用低精度数据进行拷贝,可以参考常用的量化压缩方法来将高精度数据转化为低精度数据,读入到GPU后再转化回高精度数据参与训练;或者使用对GPU友好的编解码算法——读取编码压缩后的数据,然后在GPU上进行解码等。
import torch
import torch.nn as nn
from torch.profiler import profile, ProfilerActivity
def data_copy(data, dtype_name=""):
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for _ in range(10):
output = data.to("cuda:0", non_blocking=False)
prof.export_chrome_trace(f"traces/PROF_data_copy_{dtype_name}.json")
# Float precision
data1 = torch.randn(4, 32, 32, 1024, dtype=torch.float32)
data_copy(data1, "float32")
# Uint8 precision
data2 = torch.randint(0, 255, (4, 32, 32, 1024), dtype=torch.uint8)
data_copy(data2, "uint8")
在条件允许的时候应该尽量使用无损的压缩技术,然而实际应用中大部分量化压缩算法以及部分编解码算法都是有损压缩。因此在决定使用低精度数据前还需要仔细验证。对于一些没有明确数值界限的数据来说,量化压缩到低精度数据可能对于训练结果和收敛性是有损伤的。
使用性能特化的优化器
在训练任务中,一般不会将反向传播计算出来的梯度直接累加到模型参数上,而是通过优化器(optimizer)来控制参数更新的数值。一般来说优化器会对梯度进行一系列加工,随后计算出参数更新的具体数值。
PyTorch针对每种优化器,提供了三种不同的梯度更新实现:for-loop、for-each、fused。
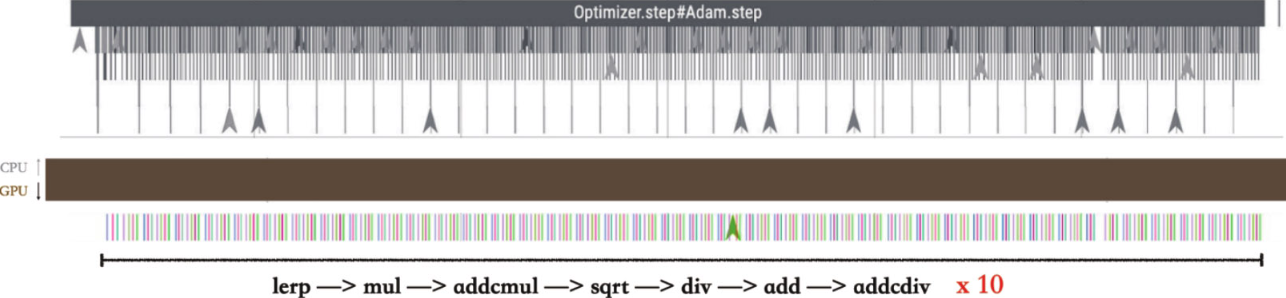
for-loop
or-loop是最为偏重于节省显存的实现,但是性能比较差。举例说明其实现原理:假如使用SGD方法更新10个参数——从w1到w10,则for-loop会使用Python中的串行循环,每次更新其中一个权重,SGD的梯度更新方式通常包括一次乘法和一次加法:
# 伪代码
for w in [w1, w2, ..., w10]:
w = w - lr * w.grad在PyTorch中,由于动态图的局限性,所有算子计算都不能自动融合,因此更新所有参数需要调用10次乘法算子和10次加法算子。这总计20次算子的调用成本可能远大于底层CUDA乘法、CUDA加法计算。特别是在参数数量非常多的时候,反复的算子调用会极大地损耗性能。为了解决这个问题,PyTorch进一步引入了for-each方法。
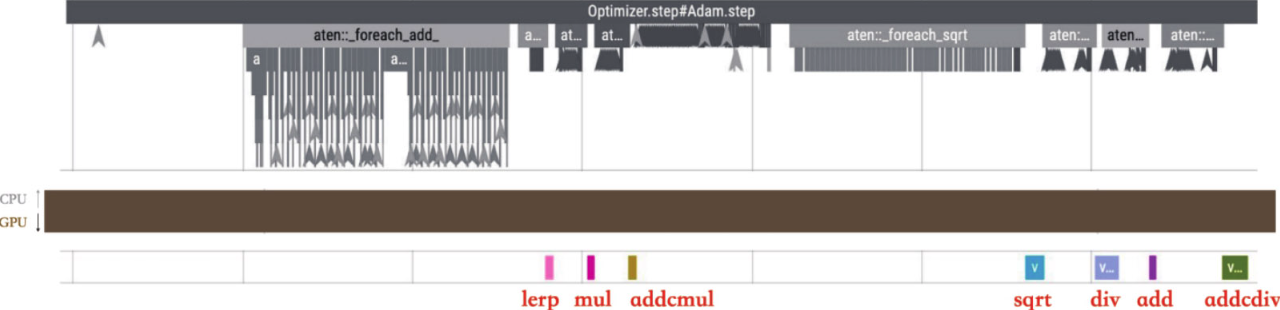
for-each和fused
for-each是相对偏重于性能的方法,但其占用的显存会更多。 由于所有参数更新都是相互独立的,我们可以先把10个参数合并到一个张量中,这样就只需要对这个合并张量调用1次乘法算子和1次加法算子即可。 虽然实际计算量没有变化,但是极大地降低了算子反复调用的次数,提高了性能。
但是对一些更复杂的优化器来说,比如包含了若干乘法、除法、加减法、平方开方等运算的Adam优化器而言,即使使用了for-each方法之后依然还有很多算子调用。 fused方法在for-each的基础上,进一步将优化器的所有计算都合并成一个算子,所以能够达到最佳的计算性能,但是其显存占用也比较高。
import torch
from torch.profiler import profile, ProfilerActivity
class SimpleNet(torch.nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fcs = torch.nn.ModuleList(torch.nn.Linear(200, 200) for i in range(20))
def forward(self, x):
for i in range(len(self.fcs)):
x = torch.relu(self.fcs[i](x))
return x
def train(net, optimizer, opt_name=""):
data = torch.randn(64, 200, device="cuda:0")
target = torch.randint(0, 1, (64,), device="cuda:0")
criterion = torch.nn.CrossEntropyLoss()
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
for _ in range(5):
optimizer.zero_grad()
output = net(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
prof.export_chrome_trace(f"traces/PROF_perf_{opt_name}.json")
# ----------------------For-loop----------------------#
net = SimpleNet().to(torch.device("cuda:0"))
adam_for_loop = torch.optim.Adam(
net.parameters(), lr=0.01, foreach=False, fused=False
)
train(net, adam_for_loop, opt_name="for_loop")
# ----------------------For-each----------------------#
net = SimpleNet().to(torch.device("cuda:0"))
adam_for_each = torch.optim.Adam(
net.parameters(), lr=0.01, foreach=True, fused=False
)
train(net, adam_for_each, opt_name="for_each")
# ----------------------Fused----------------------#
net = SimpleNet().to(torch.device("cuda:0"))
adam_fused = torch.optim.Adam(net.parameters(), lr=0.01, foreach=False, fused=True)
train(net, adam_fused, opt_name="fused")for-loop每次只更新一个参数,如图所示for-loop实现会循环调用add、lerp、mul、addcmul等算子:
for-each实现则会将add、lerp、mul、addcmul……这些独立的调用按类型合并,所以GPU队列中只会看到7个融合算子对应的计算任务:
fused则采用了更为激进的融合策略,可以看到算子调用次数减少到了两次,分别为两个巨大的融合算子,这导致优化器的CPU延迟被压缩到非常短,在性能上更具优势。

小结
 本章讲述的性能优化方法,其优化上限是将GPU队列中的“气泡”完全消除——也就是让GPU达到满载状态,但这并不是性能优化的终点。
本章讲述的性能优化方法,其优化上限是将GPU队列中的“气泡”完全消除——也就是让GPU达到满载状态,但这并不是性能优化的终点。
在GPU达到满载之后,我们还可以借助高级优化方法中的技巧来进一步优化GPU计算效率。
最后当我们将训练性能优化到极限之后,还可以采用分布式系统中数据并行的策略再次对模型训练进行加速。



