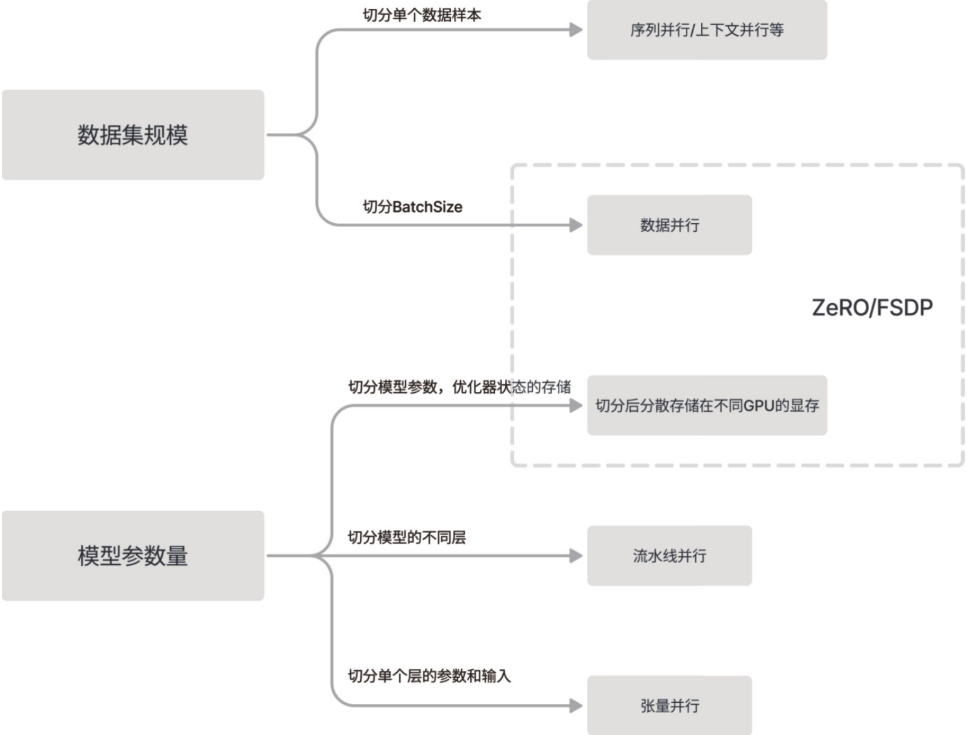
分布式训练的原理
目前流行的分布式策略有很多种,主要分为切数据(data
parallel)和切模型(model
parallel)两个大的方向。不同策略的算法和实现差异较大,但不外乎两个出发点:
-
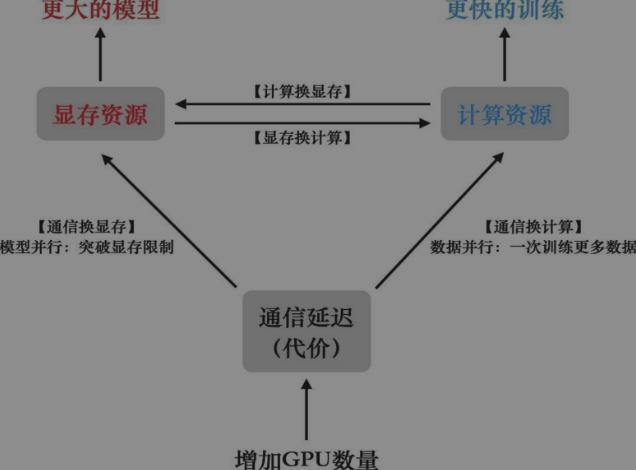
用通信开销来置换更紧缺的资源。分布式系统中每新增一个节点会以额外通信开销为代价带来额外的显存和计算资源,但如何使用这些额外的资源至关重要。如果我们用通信来换取更大的数据处理并行度,从而加速训练过程,这就是数据并行的实现方式;而如果我们用通信来突破单卡的显存容量限制,使其能够处理更大规模的模型,这就是模型并行的策略。因此切分方式的选择主要取决于我们需要通过资源置换来解决的主要矛盾。图8-1揭示不同资源之间通过置换来突破显存或者并行度限制的典型方法。
-
尽量隐藏通信开销。进程间通信和GPU计算使用不同的硬件单元,所以理论上是可以并行执行的。一个有效的设计方案是将通信过程与GPU计算过程进行重叠,以此来掩盖通信的时间开销并减少通信延迟。流水线并行(pipeline
parallel)就是基于这个思路设计的分布式策略,它通过将上一轮训练的通信过程与当前训练的计算过程重合来减少通信过程对GPU计算的阻塞。
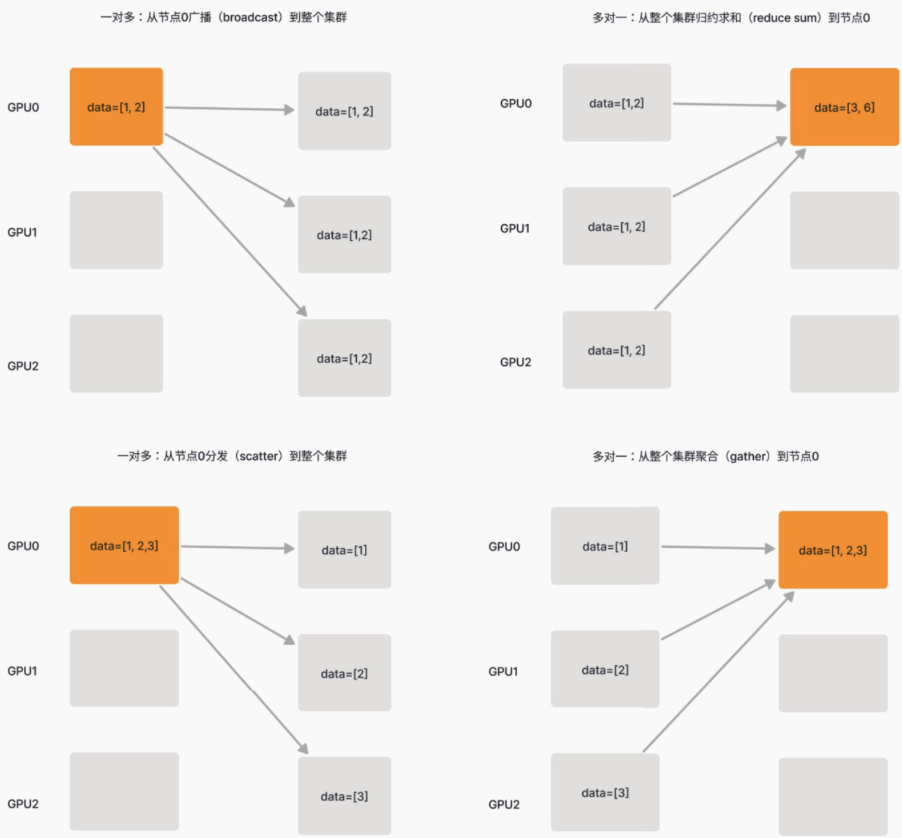
集合通信原语
实际上不同的分布式策略会通信不同类型的数据,但是总体来说以张量数据为主: 数据并行策略主要通信梯度张量; 模型并行则会根据策略不同对模型参数、梯度、优化器状态和激活张量的通信都有可能涉及。
两个节点之间的基本通信(点对点通信)操作一般包括发送(send)和接收(receive),但是涉及需要所有节点参与的集体通信操作,被归为一系列集合通信原语。
广播(broadcast)和分发(scatter)
这两个操作都是从一个节点向整个集群发送信息的操作,区别仅在每个节点收到的内容是整个数据还是数据的一部分。
聚合(gather)和归约(reduce)
gather是scatter的逆操作,它将所有节点的数据收集到一起,而reduce则是将所有节点的数据进行归约操作。
在多对多通信中可以扩展为all gather和all reduce。 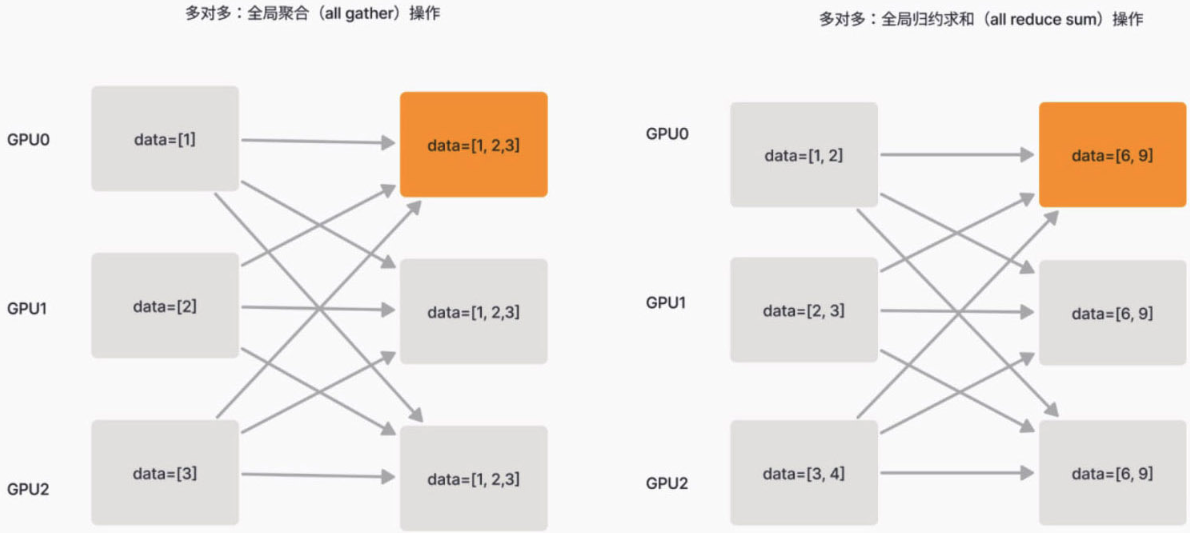
需要注意的是在分布式计算中,有一些通信原语是等价的或者可以相互转换的,比如allreduce与reduce + broadcast, scatter + gather与allgather等,这些等价操作可以根据具体的需求和实现策略进行替换,以优化性能或简化实现。
另外分布式训练的特定策略中还会涉及更多通信原语,如全局广播(all-to-all broadcast)和归约分发(reduce-scatter)操作等。
应对数据增长的并行策略
数据并行
基本步骤: -
1.模型初始化:为了确保所有节点上的模型参数保持一致,我们会采用broadcast操作,将主节点(master
node)上的模型参数发送到其他所有节点。这样的操作保证了即便是随机生成的参数,各节点上的模型初始状态也是相同的。
-
2.数据切分:在数据加载过程中,每个训练批次会被平均划分成N份,其中N代表参与计算的节点数量。
-
3.梯度同步:在反向传播完成后,我们通过执行allreduce,将各节点计算得到的梯度进行求和,从而确保所有节点在更新模型参数时使用的是相同的梯度值。
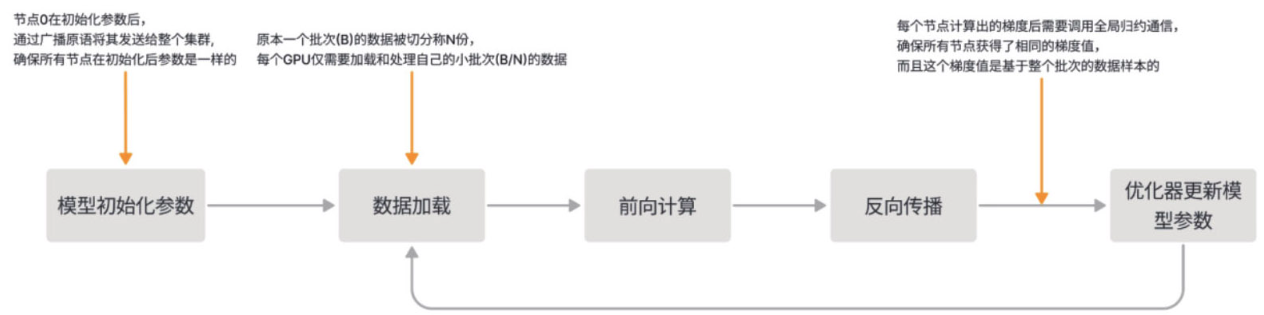 值得注意的是,在第3步中执行的allreduce默认阻塞所有计算节点,直到每个节点获取到一致的梯度值后才会进行模型的更新,这种通常被称为同步的梯度聚合更新。
值得注意的是,在第3步中执行的allreduce默认阻塞所有计算节点,直到每个节点获取到一致的梯度值后才会进行模型的更新,这种通常被称为同步的梯度聚合更新。
手动实现数据并行
首先先看普通单机单卡的训练代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from common import SimpleNet, MyTrainDataset
def train(model, optimizer, train_data, device_id):
model = model.to(device_id)
for i, (src, target) in enumerate(train_data):
src = src.to(device_id)
target = target.to(device_id)
optimizer.zero_grad()
output = model(src)
loss = F.mse_loss(output, target)
loss.backward()
optimizer.step()
print(f"[GPU{device_id}]: batch {i}/{len(train_data)}, loss: {loss}")
def main(device_id):
model = SimpleNet()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
batchsize_per_gpu = 32
dataset = MyTrainDataset(num=2048, size=512)
train_data = DataLoader(dataset, batch_size=batchsize_per_gpu)
train(model, optimizer, train_data, device_id)
if __name__ == "__main__":
device_id = 0
main(device_id)import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from common import SimpleNet, MyTrainDataset
import os
import torch.distributed as dist
import torch.multiprocessing as mp
# (3) 初始化分布式通信组:所有进程将被添加到同一个通信组中,每个进程都会被分配一个唯一的编号(rank),每个编号的进程负责一个特定的GPU
def setup(rank, device_id, world_size, backend):
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
dist.init_process_group(backend, rank=rank, world_size=world_size)
torch.cuda.set_device(device_id)
def train(model, optimizer, train_data, rank, device_id, world_size):
for i, (src, target) in enumerate(train_data):
src = src.to(device_id)
target = target.to(device_id)
optimizer.zero_grad()
output = model(src)
loss = F.mse_loss(output, target)
loss.backward()
# (5) 每个批次训练结束后进行梯度同步:在进行梯度更新之前,所有进程通过allreduce同步梯度数值
grads = [t.grad.data for t in model.parameters()]
for grad in grads:
grad.div_(world_size)
dist.all_reduce(grad, op=dist.ReduceOp.SUM)
optimizer.step()
print(f"[GPU{rank}]: batch {i}/{len(train_data)}, loss: {loss}")
def main(rank, world_size, backend):
device_id = rank
setup(rank, device_id, world_size, backend)
model = SimpleNet().to(device_id)
# (4) 初始化模型并参数同步:训练开始前由编号为0的节点将模型的初始参数同步到整个集群。
params = [t.detach() for t in model.parameters()]
for param in params:
dist.broadcast(param, 0)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
batchsize_per_gpu = 4096
dataset = MyTrainDataset(num=40960, size=512)
# (1) 数据分割:采用了PyTorch的DistributedSampler工具,它可以确保每个GPU获得独一无二且互不重叠的数据子集
sampler = torch.utils.data.distributed.DistributedSampler(
dataset, num_replicas=world_size, rank=rank
)
train_data = DataLoader(dataset, batch_size=batchsize_per_gpu, sampler=sampler)
train(model, optimizer, train_data, rank, device_id, world_size)
if __name__ == "__main__":
# (2) 多进程启动和管理:采用torch.multiprocessing.spawn启动多个进程,并指定每个进程的rank和world_size
world_size = 2
mp.spawn(main, args=(world_size, "nccl"), nprocs=world_size, join=True)PyTorch的DDP封装
上述手动的实现方式虽然可以实现数据并行,但是存在以下问题: -
1.模型中的每个参数张量都进行了一次单独的allreduce操作。在大规模模型中,通常存在成百上千个参数张量。如果在梯度聚合过程中,对每个参数梯度进行单独的allreduce通信,通信操作的启动和结束的开销会非常大。
-
2.所有allreduce操作一直等待所有层的反向传播完成后才开始执行。然而以模型中的fc3算子为例,实际上在该层完成反向传播之后,我们就可以立即对fc3的参数梯度进行归约操作,而无须等待整个模型的反向传播完全结束。
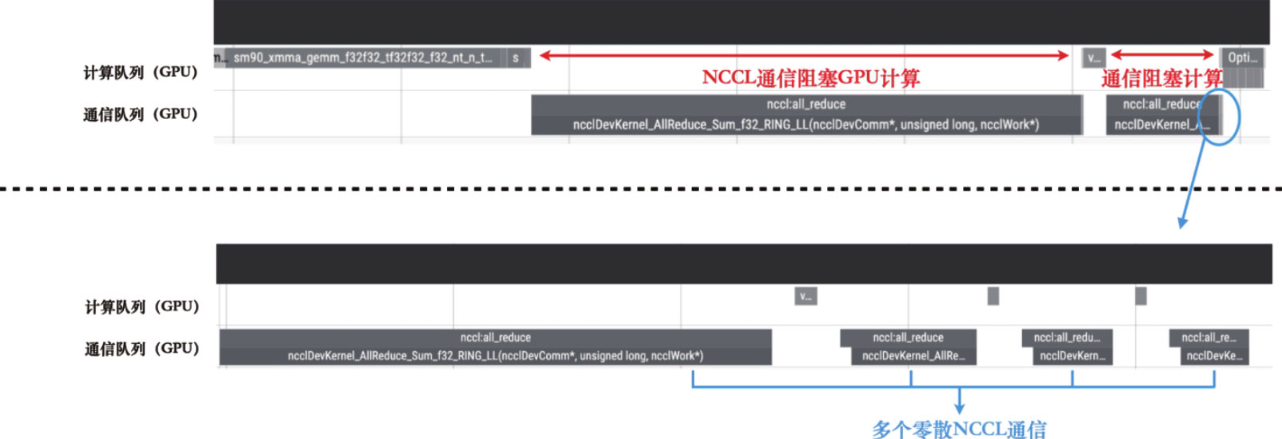
PyTorch的DistributedDataParallel(DDP)以及基于它开发的如accelerate这类高级封装工具,可以自动完成数据并行训练的细节,并提供更简洁的接口。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from common import SimpleNet, MyTrainDataset
import os
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
# (3) 初始化分布式通信组
def setup(rank, device_id, world_size, backend):
os.environ["MASTER_ADDR"] = "127.0.0.1"
os.environ["MASTER_PORT"] = "29500"
dist.init_process_group(backend, rank=rank, world_size=world_size)
torch.cuda.set_device(device_id)
def train(model, optimizer, train_data, rank, device_id):
for i, (src, target) in enumerate(train_data):
src = src.to(device_id)
target = target.to(device_id)
optimizer.zero_grad()
output = model(src)
loss = F.mse_loss(output, target)
loss.backward()
optimizer.step()
print(f"[GPU{rank}]: batch {i}/{len(train_data)}, loss: {loss}")
def main(rank, world_size, backend):
device_id = rank
setup(rank, device_id, world_size, backend)
model = SimpleNet().to(device_id)
# (4) 使用DDP封装模型,DDP会自动进行模型的初始化参数同步和批次训练结束后的梯度同步
model = DDP(model, device_ids=[device_id])
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2)
batchsize_per_gpu = 32
dataset = MyTrainDataset(num=2048, size=512)
# (1) 数据分割
sampler = torch.utils.data.distributed.DistributedSampler(
dataset, num_replicas=world_size, rank=rank
)
train_data = DataLoader(dataset, batch_size=batchsize_per_gpu, sampler=sampler)
train(model, optimizer, train_data, rank, device_id)
if __name__ == "__main__":
# (2) 多进程启动和管理
world_size = 2
mp.spawn(main, args=(world_size, "nccl"), nprocs=world_size, join=True)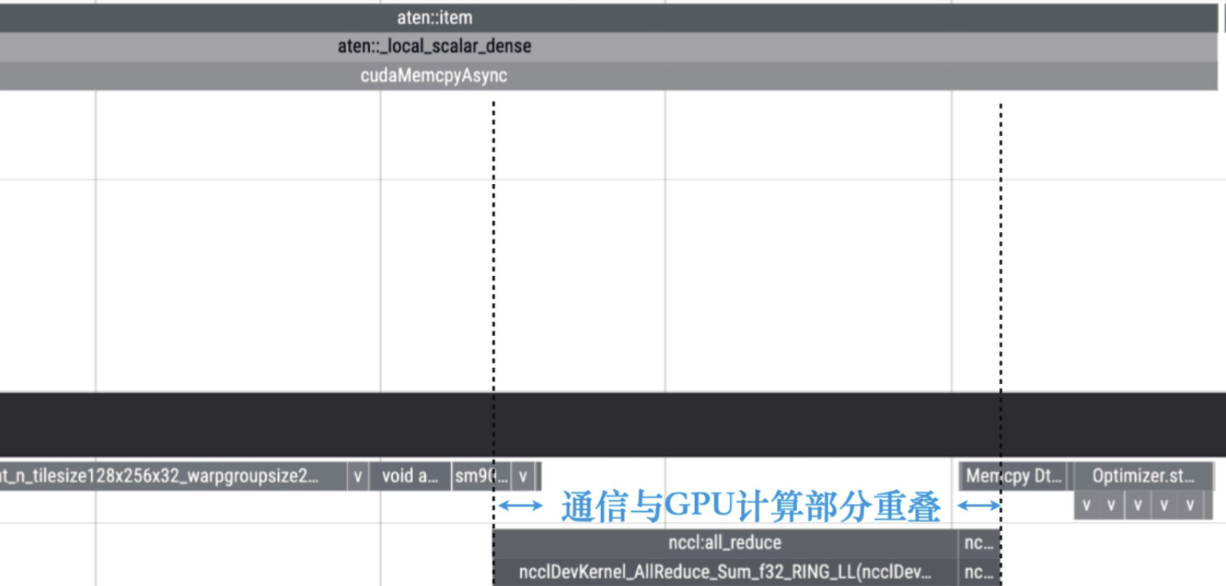 使用torch.profiler对基于DDP的代码进行性能分析,我们注意到基于DDP的实现自动进行了上面的提到的两个优化:
-
分组传输:为了减少每个参数独立进行allreduce操作所带来的通信开销,可以利用分组传输(Bucketing)技术。该技术自动将模型中的所有算子参数分成几个组,每组的参数梯度被合并成一个较大的张量后再执行通信。这样,每组内的梯度计算完成后只需执行一次通信操作,从而大幅降低了通信次数,提高了训练效率。
-
重叠计算和通信:梯度计算较早完成的组会优先启动通信操作,这一过程与后续层的梯度计算重叠,从而大幅减少了由通信引起的延迟。
使用torch.profiler对基于DDP的代码进行性能分析,我们注意到基于DDP的实现自动进行了上面的提到的两个优化:
-
分组传输:为了减少每个参数独立进行allreduce操作所带来的通信开销,可以利用分组传输(Bucketing)技术。该技术自动将模型中的所有算子参数分成几个组,每组的参数梯度被合并成一个较大的张量后再执行通信。这样,每组内的梯度计算完成后只需执行一次通信操作,从而大幅降低了通信次数,提高了训练效率。
-
重叠计算和通信:梯度计算较早完成的组会优先启动通信操作,这一过程与后续层的梯度计算重叠,从而大幅减少了由通信引起的延迟。
在复杂的大规模训练场景中,除了DDP已提供的通用优化措施外,可能还需要根据具体的硬件配置和实际需求进行定制化的优化。以下是一些可供参考的优化策略: - 降低通信量:通过梯度压缩技术减少传输数据量,例如量化、稀疏化或低秩近似,从而降低通信成本。 - 拓扑感知策略:根据计算节点的网络拓扑结构设计更高效的通信操作,优化数据传输过程。
数据并行的性价比
为了评估分布式系统的性能增益,在处理同样的数据量的前提下,可以使用加速比这一指标来进行衡量。 \[ 加速比 = \frac{单机单卡的训练时间}{N个节点分布式训练的时间} \] 在没有通信开销的理想情况下,加速比应该等于N,即分布式训练的加速比与节点数量成正比。
但是随着节点数量的增加,节点间的通信量和通信次数通常也会相应增加,这导致通信延迟逐渐增大。一旦增加节点带来的通信开销抵消了并行计算带来的好处,再扩展下去就得不偿失了。
使用PyTorch的DistributedDataParallel模块中提供的register_comm_hook()接口,我们可以将DDP中默认的节点通信函数替换为自定义函数,从而获取更精确的通信开销数据。
其他数据维度的切分
前面介绍的都是在BatchSize维度上对数据进行切分,对于文本、视频等长序列数据,其序列长度(sequence length)也会对训练性能和显存占用产生很大影响。一个典型的例子是基于Transformer的大型语言模型在处理超长文本时,由于其自注意力机制,中间变量所需的显存会随序列长度的增长而成平方级的增加,这很容易超过单个GPU的显存容量。因此,除了数据并行之外,还可能需要采用序列并行(sequence parallel)、上下文并行(context parallel)等策略来处理单个样本中的长序列。
应对模型增长的并行策略

静态显存切分
单卡环境中,往往只能通过将静态显存下放到CPU来缓解显存压力,但在多GPU环境中,得益于NVLink或InfiniBand, GPU间的通信效率要远超GPU-CPU间的通信效率,因此,将静态显存分块存储在不同的GPU上,本质上是将持续占用显存的静态数据转变为动态的“按需分配”,从而有效降低单GPU显存占用的峰值。
在分布式训练中,静态显存的分块存储常作为显存优化手段与其他分布式策略结合使用:

Deepspeed和Fairscale推出的ZeRO和FSDP策略均基于此思路开发,以ZeRO策略为例,其显存切分实现了三个级别的优化: - ZeRO-1:切分优化器状态分散到多个GPU上存储。 - ZeRO-2:切分梯度和优化器状态分散到多个GPU上存储。 - ZeRO-3:切分梯度、优化器状态和模型参数分散到多个GPU上存储。
ZeRO策略在PyTorch以及之前提到的Accelerate和Deepspeed框架中均有对应的实现。

以上图中的7.5B模型为例,假设我们有N=64块GPU进行数据并行训练, - 在ZeRO-1阶段,优化器的状态量首先被分散存储到所有GPU中,此时单张GPU上的内存使用量骤降到(4+4+8/64)7.5=60.9GB。 - ZeRO-2阶段进一步地将模型的梯度也分散存储,此时单张GPU上的内存使用量便是(4+(4+8)/64)7.5=31.4GB。 - ZeRO-3阶段将模型的参数也分散存储到N个节点,此时每张GPU的内存消耗只有(4+4+8)/64*7.5=1.875GB。
动态显存切分
模型并行/流水线并行
由于深度学习模型的结构天然是一层一层连起来的,因此一个直观的切分方法是将不同的模型层分配到不同的GPU上,每个GPU只负责模型几个层的计算。例如,可以将神经网络的前几层放置在一个GPU上,随后的几层放在另一个GPU上,依此类推。这样,整个模型被分成几个阶段,阶段之间由通信串联起来,像一条流水线一样处理一批一批的数据,因此这种方法被称为流水线并行(pipeline parallel)。
如图所示一个模型共有7层,其中第4层的计算需求最大,其他层较小,我们可以在层间进行切分,如将前3层、中间1层和最后3层分别放到不同的GPU上进行处理,并通过节点通信将处理结果同步到下一个GPU中参与后续计算。
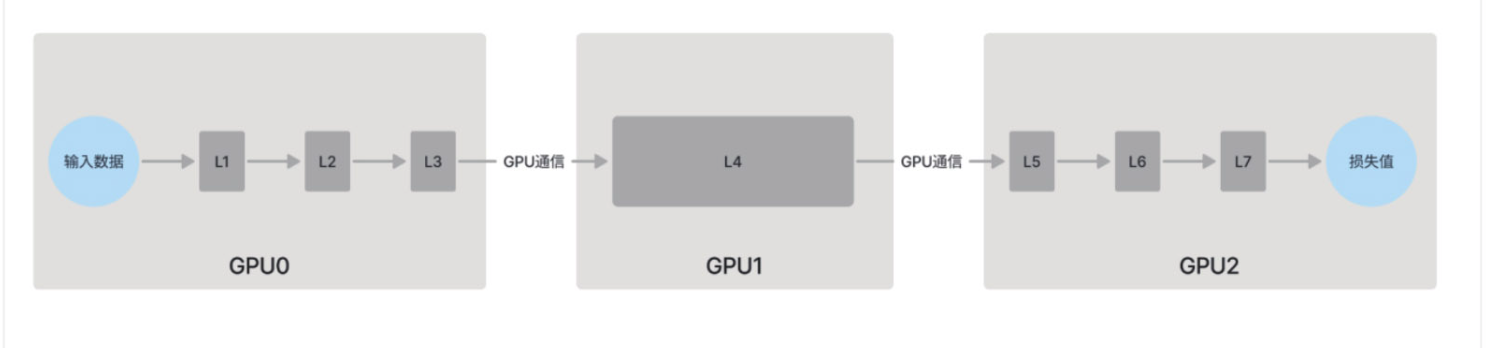
很明显这种串行的执行方式会导致GPU利用率不均衡,通过跟踪一个数据批次在模型中的处理过程,我们可以看到GPU大部分时间处于闲置状态(“气泡”)。
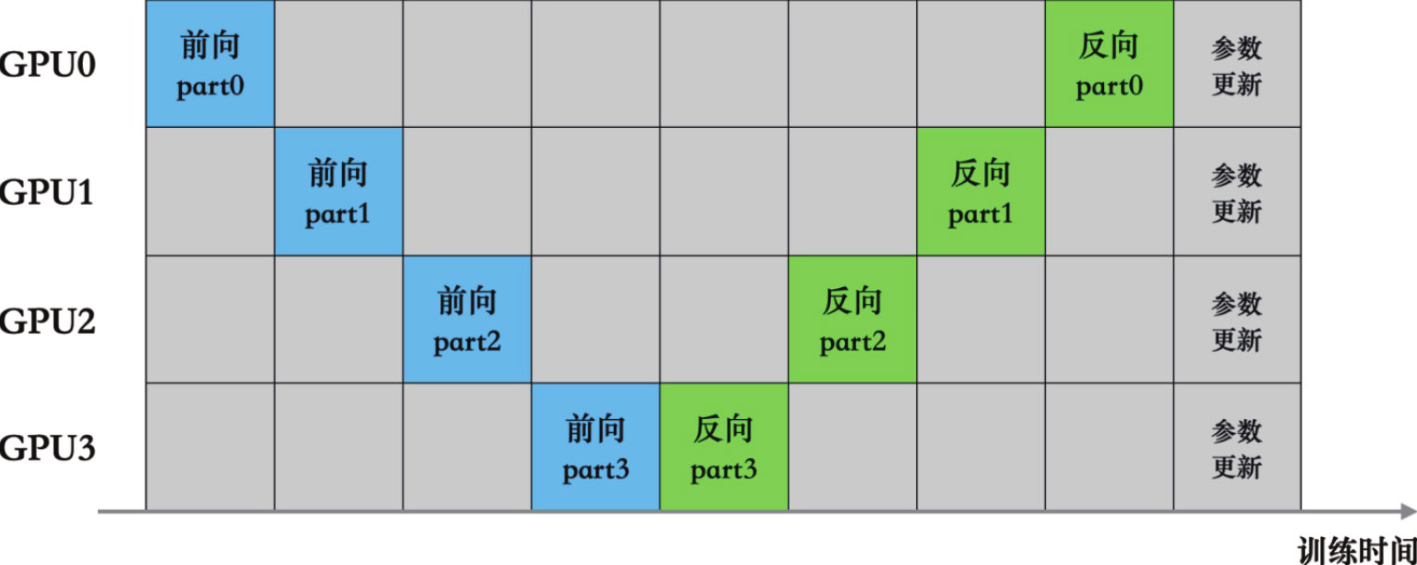
为了提高效率可以将大的批次数据分为若干个小批次,每个节点每次仅处理一个小批次,这样在原先等待的气泡时间里就可以处理下一个批次的数据(Gpipe)。 甚至可以让每个节点交替进行前向和反向计算,这样可以尽早地启动反向运算的流水线,缩短中间节点的等待时间(PipeDream)。
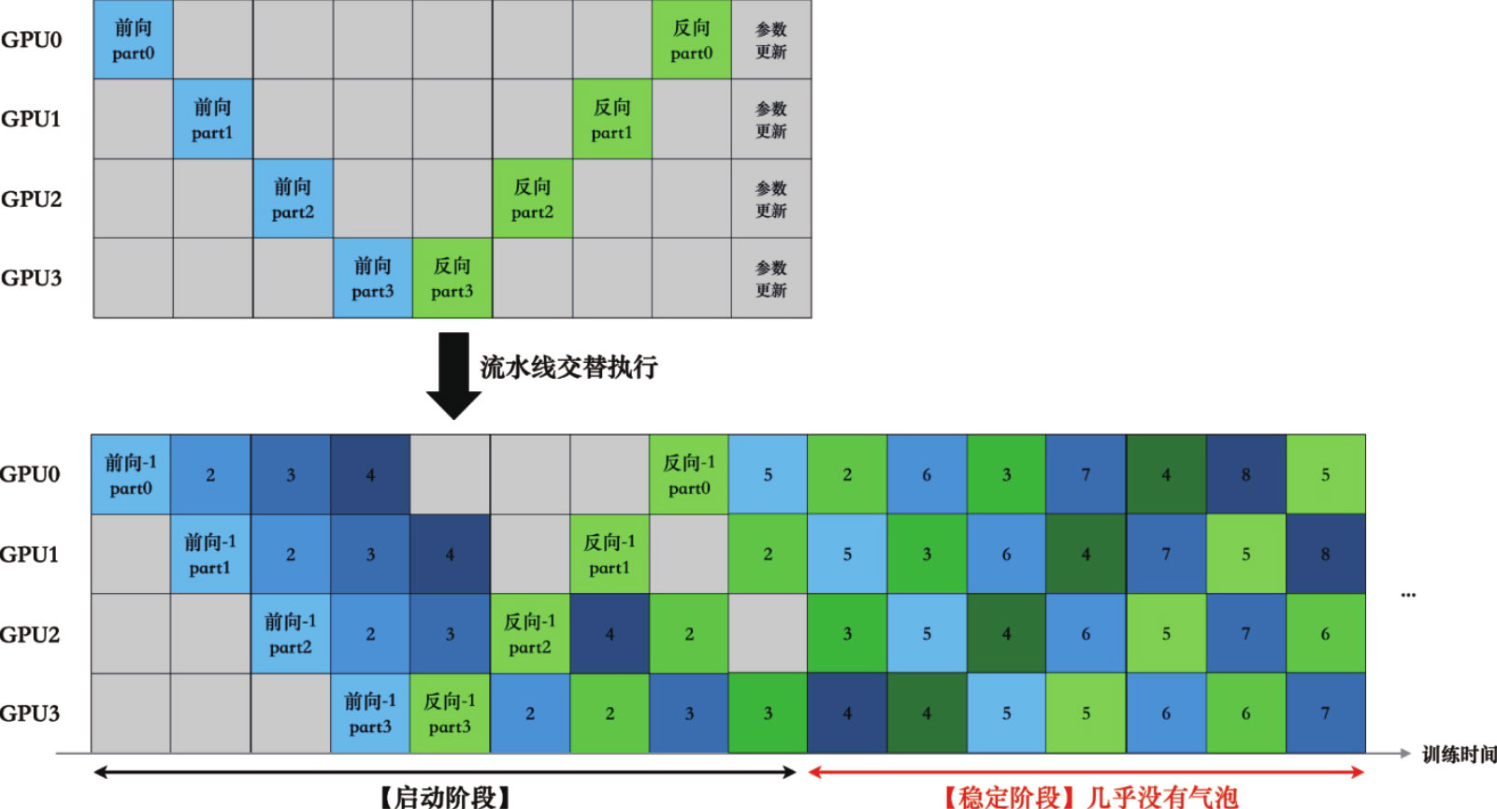 如图展示了一个被划分成4个阶段的模型,每个阶段在一台GPU上运行。同时一个批次的数据也被分为4个小批次,依次从GPU0开始计算,逐步传播到GPU3并计算损失值,一旦GPU3完成了第一个小批次的前向传递,它立刻就会对同一个小批次执行反向传递,然后开始在后续小批次之间交替进行前向和反向传递。
随着反向传递开始向流水线中较早的阶段传播,每个阶段开始在不同小批次之间交替进行前向和反向传递,因此“气泡”可以被有效消除。
如图展示了一个被划分成4个阶段的模型,每个阶段在一台GPU上运行。同时一个批次的数据也被分为4个小批次,依次从GPU0开始计算,逐步传播到GPU3并计算损失值,一旦GPU3完成了第一个小批次的前向传递,它立刻就会对同一个小批次执行反向传递,然后开始在后续小批次之间交替进行前向和反向传递。
随着反向传递开始向流水线中较早的阶段传播,每个阶段开始在不同小批次之间交替进行前向和反向传递,因此“气泡”可以被有效消除。
张量并行
但是当模型中显存占用最大的层无法在单个GPU上运行时,流水线并行策略就无法继续使用。
张量并行(tensor parallel)策略主要是通过矩阵乘法的分块计算,实现单卡无法容纳的大型矩阵乘法操作。比如要实现下矩阵乘法Y=X×W,在参数矩阵W非常大甚至超出单张卡的显存容量时,我们可以把它在特定维度(列或者行)上切分到多张卡上,最后通过all-gather/all-reduce操作汇总,结果在数学上都与直接做Y=X×W等价。
按列切块的计算过程: 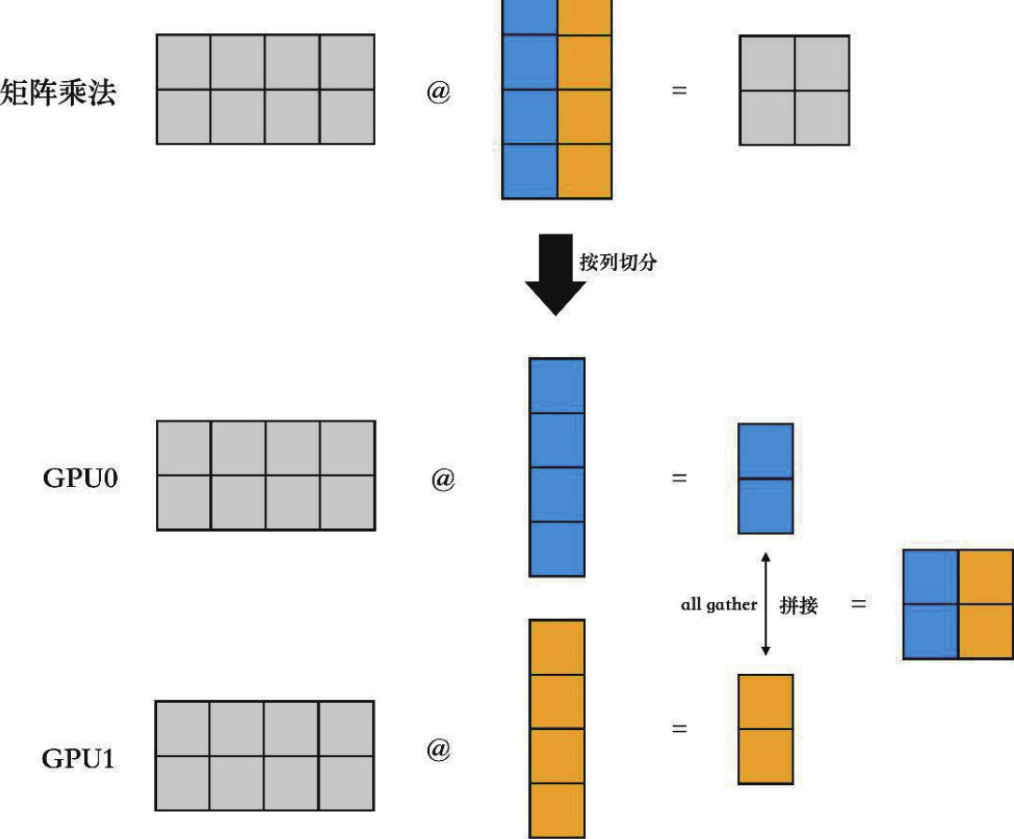
按行切块的计算过程: 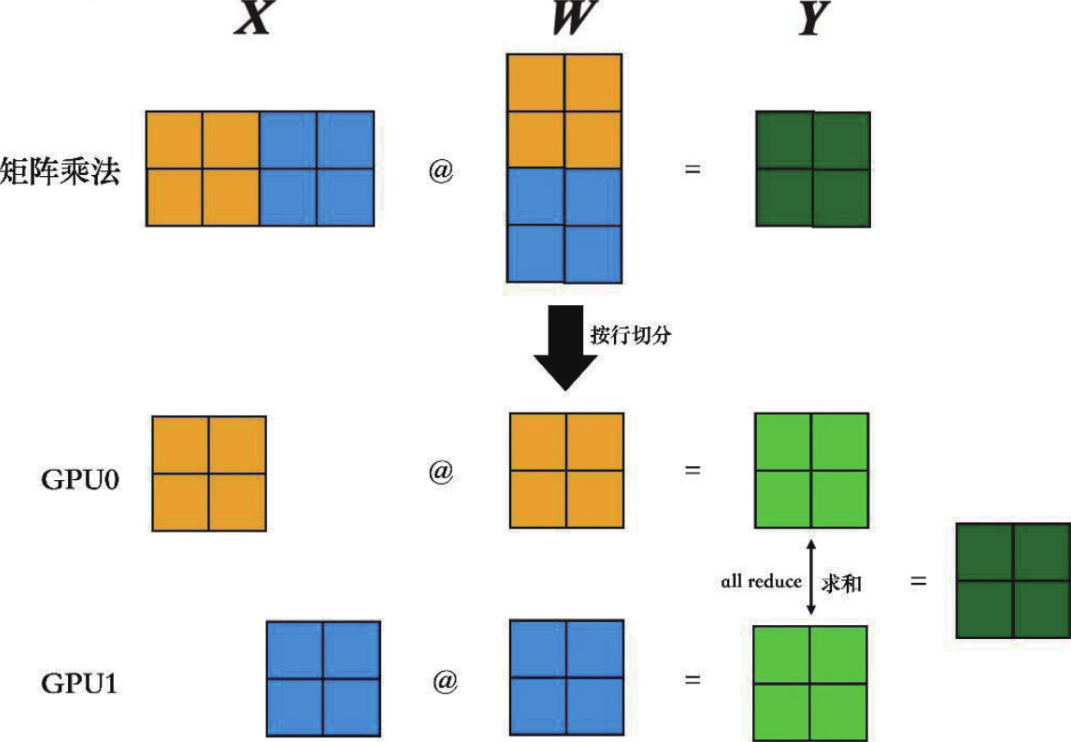
与流水线并行能在多台机器协同训练不同,张量并行需要传输大量数据,当这种传输需要通过网络设备跨机器进行时,受限的网络带宽会严重阻碍张量并行训练的效率。因此,张量并行通常只在配备了NVLink的单机多卡范围中使用。
小结