自动混合精度训练
NVIDIA从Volta架构之后就增加了专门用于加速矩阵乘法和累加操作的TensorCore硬件单元,在半精度甚至更低精度计算任务中相比传统CUDA核心可以实现数倍加速。
结合混合精度的训练方法可以在充分利用低精度优秀的计算性能和显存占用的同时,保持与单精度训练相近的模型精度。
浮点数的表示

可以直观的看出数值范围主要由指数部分决定。而精度主要由尾数的位数决定。
再看一下对于FP16来说,不同指数位下的数值范围和精度情况: 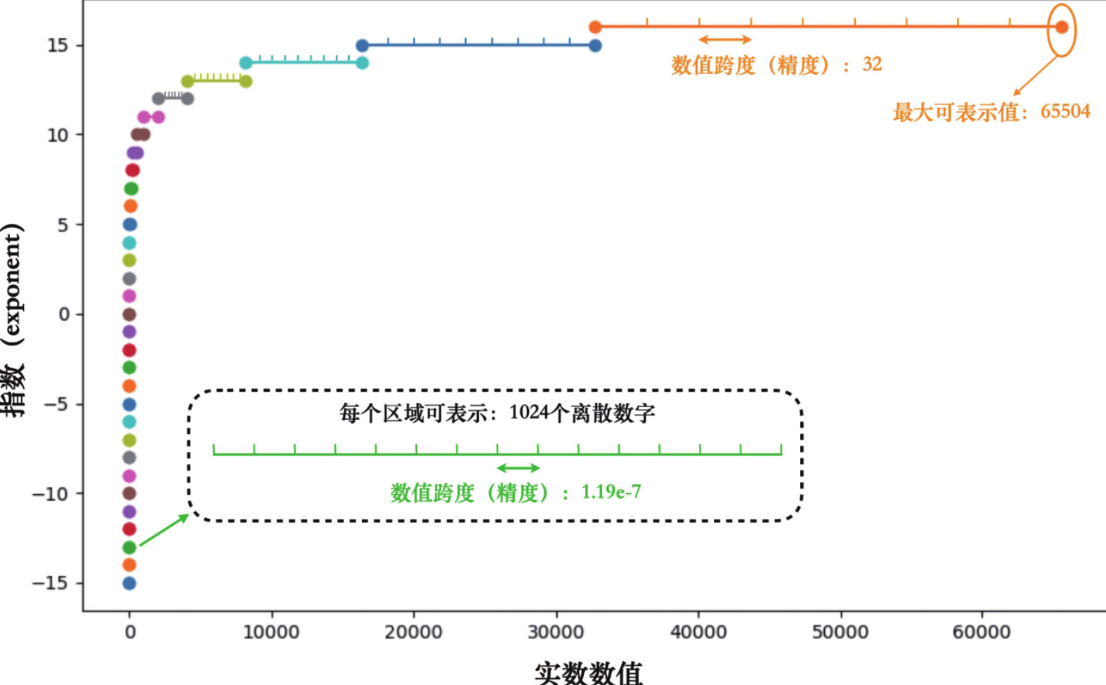
注意在同一指数档位中,不同的尾数就相当于在该档位的最小值和最大值中间均等地插入若干可以表示的数字。当我们想要找到一个实数的对应表示时,必须找到离自己最近的可以表示的数字。比如float16的尾数会在每个档位中插入1024个数字,这样\(2^{6}\)和\(2^{7}\)之间的数字间隔为 \(2^{6} / 1024 = 0.0625\)。所以落在这个档位中的两个实数,如果差异在0.0625以下则会被表示成同一个float16数字,这就是尾数对数值精度的影响。
因此在同一种精度下,在指数档位小的时候精度会更高些(在更小的范围中间插入相同的数量的数字)。
使用低精度数据类型的优缺点
优点
- 计算效率更高:16位浮点数的计算速度通常是32位浮点数的两倍。
- 存储空间更少:16位浮点数仅需32位浮点数一半的存储空间。
- 传输速度更快:较小的存储需求意味着在相同时间内传输更少的数据量,这不仅能加速硬盘读写速度,也有助于提高内存、显存以及多级缓存的读写效率。
缺点
- 数值范围和精度的限制:float16的数值范围和精度较低。
- 额外的数值转换开销:并非所有计算操作都适合使用float16,而在float32与float16之间的数据转换可能会产生额外的性能开销。
- 需要特定硬件支持:为了充分利用float16的优势,必须配备支持半精度运算加速的硬件,如NVIDIA的AI计算卡或RTX30系列以上的显卡。在老旧或不支持float16计算的GPU上,不仅性能提升不明显,还可能因数据转换的额外开销而导致性能下降。
PyTorch的自动混合精度训练
使用FP16在训练时会出现的问题: - 训练初期波动大,容易数值溢出,容易出现NaN或Inf。 - 希望能够自动判断哪些算子适合使用float16加速,并自动对这些算子的输入输出张量进行类型转换。
PyTorch提供了两个核心接口:
torch.autocast和torch.cuda.amp.GradScaler。
torch.autocast可以根据算子类型,自动选择使用半精度(float16)或单精度(float32)进行计算,以适应不同算子对精度的要求,达到较好的性能、精度平衡。
torch.cuda.amp.GradScaler则用于平衡前向张量和反向梯度的数值范围。其基本原理是利用一个放大系数(scale factor),在不引起梯度溢出的情况下尽可能使用较高的放大系数,从而充分利用float16的数值范围。训练过程中如果检测到梯度溢出,GradScaler会自动跳过该次的权重更新,并相应缩小放大系数。如果一段时间内未发生梯度溢出,GradScaler则会尝试增加放大系数,以最大化float16的数值范围利用率。
import torch
import time
import torch.nn as nn
from torch.profiler import profile, ProfilerActivity
from torch.optim import SGD
from torch.utils.data import TensorDataset
class SimpleCNN(nn.Module):
def __init__(self, input_channels):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(
input_channels, 64, kernel_size=3, stride=1, padding=1
)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
self.conv4 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
self.relu = nn.ReLU()
def forward(self, x):
out = self.relu(self.conv1(x))
out = self.relu(self.conv2(out))
out = self.relu(self.conv3(out))
out = self.relu(self.conv4(out))
return out
def train(dataset, model, use_amp):
optimizer = SGD(model.parameters(), lr=0.1, momentum=0.9)
#----------------------torch.cuda.amp.GradScaler----------------------
scaler = torch.cuda.amp.GradScaler(enabled=use_amp)
for batch_data in dataset:
#----------------------torch.autocast----------------------
with torch.autocast(
device_type="cuda", dtype=torch.float16, enabled=use_amp
):
result = model(batch_data[0])
loss = result.sum()
optimizer.zero_grad()
#----------------------torch.cuda.amp.GradScaler----------------------
scaler.scale(loss).backward() # 对loss进行放大
scaler.step(optimizer) # 更新权重
scaler.update() # 更新放大系数在支持FP16计算的机器上运行以下训练代码,可以发现开启amp后速度提高一倍。
N, C, H, W = 32, 3, 256, 256 # Example dimensions
data = torch.randn(10, N, C, H, W, device="cuda")
dataset = TensorDataset(data)
model = SimpleCNN(C).to("cuda")
# warm up
train(dataset, model, use_amp=False)
torch.cuda.synchronize()
# 测量未使用AMP时的时间和性能图谱
start_time = time.perf_counter()
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
train(dataset, model, use_amp=False)
torch.cuda.synchronize()
prof.export_chrome_trace("traces/PROF_wo_amp.json")
end_time = time.perf_counter()
elapsed = end_time - start_time
print(f"Float32 Time: {elapsed} seconds")
# warm up
train(dataset, model, use_amp=True)
torch.cuda.synchronize()
# 测量使用AMP后的时间和性能图谱
start_time = time.perf_counter()
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof:
train(dataset, model, use_amp=True)
torch.cuda.synchronize()
prof.export_chrome_trace("traces/PROF_amp.json")
end_time = time.perf_counter()
elapsed = end_time - start_time
print(f"Float16 Time: {elapsed} seconds")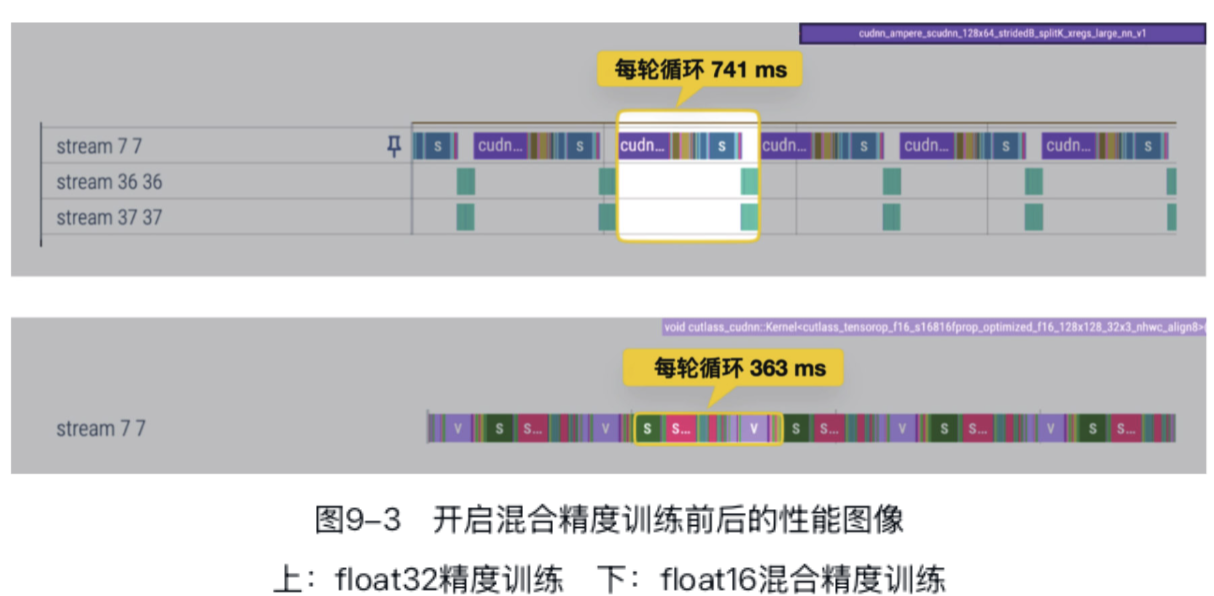
一般来说,自动混合精度在GPU使用率越高的场景中,加速效果越明显。对于GPU使用率很低,以CPU瓶颈为主的训练过程,自动混合精度训练的性能可能反而变差——额外的数据转换开销不可忽视。
自定义高性能算子
算子的计算效率成为程序的性能瓶颈,更进一步的优化会面临两个主要挑战: - 1. 缺少全局的计算图:PyTorch主要提供基础算子,但是由于缺少全局的计算图信息无法自动合并计算,这也极大限制了PyTorch在算子层面的优化空间。 - 2. 调度开销:由于动态图模式中每个算子是独立的,因此每次调用都伴随一次调度开销。
在开发者深入了解计算图的前提下,编写自定义算子不仅可以合并多个算子降低调度开销,还可以精细控制GPU的执行,包括线程块的配置以及内存访问模式等。 以flash-attention库为例,它为Transformer模型中的自注意力部分提供了专门的自定义算子,通过优化内存访问模式和充分利用GPU的并行处理功能来提升计算效率。
自定义高性能算子的封装流程
实现一个PyTorch自定义算子包含三个核心步骤,分别是: - 1. [C++/CUDA]算子的多后端代码实现,比如CPU实现、CUDA实现等。 - 2. [Python]将算子注册到Python中,通过Pybind将算子导入到Python。 - 3. [PyTorch]将算子注册到PyTorch中,封装成nn.Module便于在PyTorch中调用。
后面以动手实现一个Sigmoid算子为例,介绍自定义算子的封装流程。(注意:这里实现的没有Pytorch自带的高效,只是为了介绍自定义算子的封装流程)
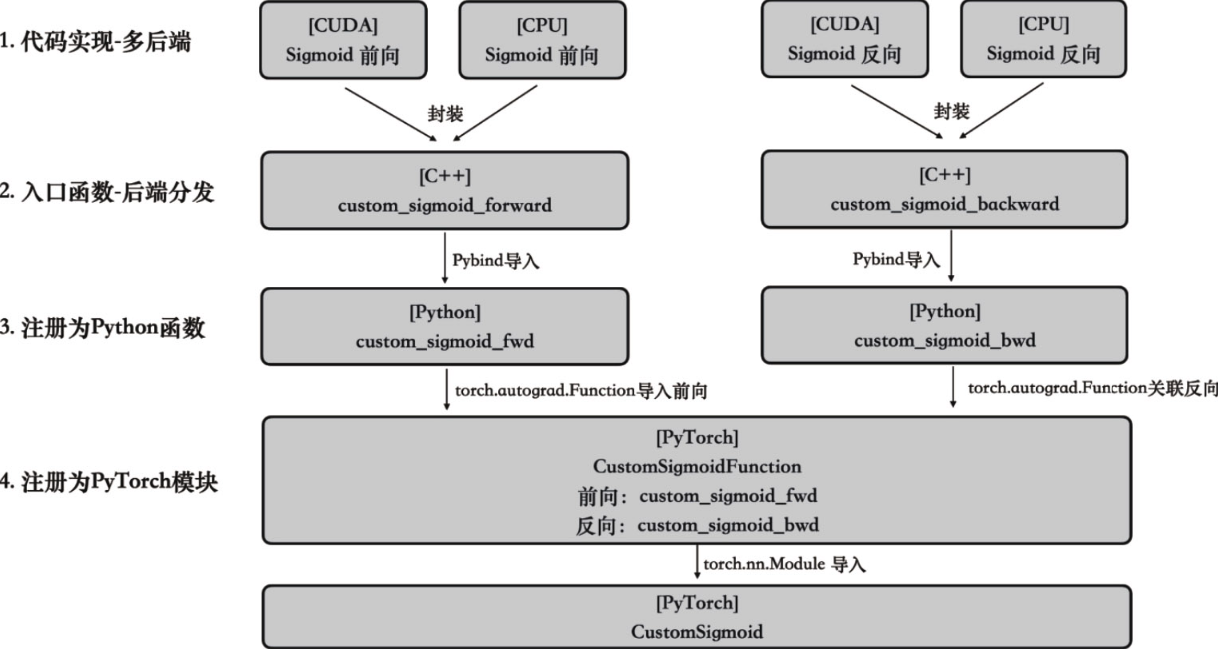
自定义算子的后端实现
首先来定义Sigmoid的CUDA核函数实现,我们将其写在custom_sigmoid_cuda.cu文件中:
// custom_sigmoid_cuda.cu
#include <cuda.h>
#include <cuda_runtime.h>
#include <torch/extension.h> // Pytorch为自定义算子提供的一系列预置函数和接口
#include <iostream>
#include <vector>
template <typename scalar_t>
__global__ void sigmoid_kernel(const scalar_t *__restrict__ input_tensor_data,
scalar_t *__restrict__ output_tensor_data,
size_t total_num_elements) {
// 计算要处理的元素位置
const int element_index = blockIdx.x * blockDim.x + threadIdx.x;
if (element_index < total_num_elements) {
// 在单个元素上进行sigmoid计算
scalar_t x = input_tensor_data[element_index];
scalar_t y = 1.0 / (1.0 + exp(-x));
// 将计算结果写回显存
output_tensor_data[element_index] = y;
}
}接下来要对定义的核函数进行进一步的封装,让它能接受并返回torch::Tensor,这里torch::Tensor就是PyTorch提供的C++层面的张量:
// custom_sigmoid_cuda.cu
torch::Tensor custom_sigmoid_cuda_forward(torch::Tensor input) {
size_t total_num_elements = input.numel();
auto output = torch::zeros_like(input);
// 配置CUDA线程数和线程块数
const int threads = 512;
const int blocks = (total_num_elements + threads - 1) / threads;
// 将实现好的CUDA kernel注册为前向算子的CUDA后端实现
AT_DISPATCH_FLOATING_TYPES(
input.type(), "sigmoid_kernel", ([&] {
sigmoid_kernel<scalar_t><<<blocks, threads>>>(
input.data<scalar_t>(), output.data<scalar_t>(),
total_num_elements);
}));
return output;
}反向传播的核函数和封装类似:
// custom_sigmoid_cuda.cu
template <typename scalar_t>
__global__ void sigmoid_grad_kernel(
const scalar_t *__restrict__ output_tensor,
const scalar_t *__restrict__ output_grad_tensor,
scalar_t *__restrict__ input_grad_tensor, size_t total_num_elements) {
// 计算要处理的元素位置
const int element_index = blockIdx.x * blockDim.x + threadIdx.x;
if (element_index < total_num_elements) {
// 在单个元素上进行sigmoid的梯度计算
scalar_t output_grad = output_grad_tensor[element_index];
scalar_t output = output_tensor[element_index];
scalar_t input_grad = (1.0 - output) * output * output_grad;
// 将计算结果写回显存
input_grad_tensor[element_index] = input_grad;
}
}
torch::Tensor custom_sigmoid_cuda_backward(torch::Tensor output,
torch::Tensor output_grad) {
size_t total_num_elements = output_grad.numel();
auto input_grad = torch::zeros_like(output_grad);
const int threads = 512;
const int blocks = (total_num_elements + threads - 1) / threads;
// 将实现好的CUDA kernel注册为反向算子的CUDA后端实现
AT_DISPATCH_FLOATING_TYPES(
output_grad.type(), "sigmoid_grad_kernel", ([&] {
sigmoid_grad_kernel<scalar_t><<<blocks, threads>>>(
output.data<scalar_t>(), output_grad.data<scalar_t>(),
input_grad.data<scalar_t>(), total_num_elements);
}));
return input_grad;
}自定义算子导入Python
到此为止,实现了Sigmoid算子的CUDA后端代码,用类似的方法还可以实现Sigmoid的CPU或者其他后端代码。 但是我们最终需要根据Python中的torch.device来决定调用哪个后端的代码,所以这里还需要实现一层代码分发的机制。 下面的代码是一个简易的Sigmoid CPU后端的实现,并且会根据输入张量的后端来决定调用算子的CUDA实现或是CPU实现:
// custom_sigmoid.cpp
#include <torch/extension.h>
#include <iostream>
#include <vector>
// forward declarations or include the header
torch::Tensor custom_sigmoid_cuda_forward(torch::Tensor input);
torch::Tensor custom_sigmoid_cuda_backward(torch::Tensor output,
torch::Tensor output_grad);
// 简易的sigmoid前向算子的CPU后端实现
torch::Tensor custom_sigmoid_cpu_forward(torch::Tensor input) {
return 1.0 / (1 + torch::exp(-input));
}
// 简易的sigmoid反向算子的CPU后端实现
torch::Tensor custom_sigmoid_cpu_backward(torch::Tensor output,
torch::Tensor output_grad) {
return (1 - output) * output * output_grad;
}
// 进行前向算子的后端实现分发
torch::Tensor custom_sigmoid_forward(torch::Tensor input) {
TORCH_CHECK(input.is_contiguous(), "input must be contiguous")
if (input.device().is_cuda()) {
return custom_sigmoid_cuda_forward(input);
} else {
return custom_sigmoid_cpu_forward(input);
}
}
// 进行反向算子的后端实现分发
torch::Tensor custom_sigmoid_backward(torch::Tensor output,
torch::Tensor grad_output) {
TORCH_CHECK(grad_output.is_contiguous(), "input must be contiguous")
if (output.device().is_cuda()) {
return custom_sigmoid_cuda_backward(output, grad_output);
} else {
return custom_sigmoid_cpu_backward(output, grad_output);
}
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
// 注册算子以便在Python中调用
m.def("sigmoid_fwd", &custom_sigmoid_forward, "Custom sigmoid forward");
m.def("sigmoid_bwd", &custom_sigmoid_backward, "Custom sigmoid backward");
}自定义算子导入PyTorch
为了能最终在PyTorch中使用我们编写的算子,还需要写一个setup.py文件来编译并最终以Python模块的形式,导入到PyTorch中:
# setup.py
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CppExtension
setup(
name="custom_ops",
ext_modules=[
CppExtension(
"custom_ops",
[
"custom_sigmoid.cpp",
"custom_sigmoid_cuda.cu",
],
extra_compile_args={"cxx": ["-g"], "nvcc": ["-O2"]},
)
],
cmdclass={"build_ext": BuildExtension},
)python setup.py install# custom_sigmoid_op.py
import torch
from torch.autograd import Function
# custom_ops 便是我们自定义的Python扩展模块,包含了C++中编写的自定义sigmoid算子
import custom_ops
class CustomSigmoidFunction(Function):
@staticmethod
def forward(ctx, input):
# 调用自定义算子的前向操作
output = custom_ops.sigmoid_fwd(input)
ctx.save_for_backward(output)
return output
@staticmethod
def backward(ctx, grad_output):
(output,) = ctx.saved_tensors
# 调用自定义算子的反向操作
grad_input = custom_ops.sigmoid_bwd(output, grad_output.contiguous())
return grad_input
class CustomSigmoid(torch.nn.Module):
def forward(self, input):
return CustomSigmoidFunction.apply(input)在Python中使用自定义算子
到此为止,我们完成了所有自定义算子的注册流程。接下来可以像使用其他PyTorch原生算子一样,在PyTorch中调用我们注册的自定义算子,让我们来实际测试一下:
# main.py
import torch
import torch.nn.functional as F
import numpy as np
from custom_sigmoid_op import CustomSigmoid
def run(np_input, sigmoid_op, device="cuda"):
x = torch.tensor(np_input, dtype=torch.double, device=device, requires_grad=True)
output = sigmoid_op(x)
loss = torch.sum(output)
loss.backward()
return output.clone(), x.grad.clone()
custom_sigmoid = CustomSigmoid()
device = "cuda"
np_input = np.random.randn(10, 20)
# 确保自定义算子各个后端的计算结果与PyTorch原生sigmoid算子的结果是一致的
for device in ["cpu", "cuda"]:
sigmoid_out_torch, sigmoid_grad_torch = run(np_input, torch.sigmoid, device)
sigmoid_out_custom, sigmoid_grad_custom = run(np_input, custom_sigmoid, device)
# Compare results
if torch.allclose(sigmoid_out_torch, sigmoid_out_custom) and torch.allclose(
sigmoid_grad_torch, sigmoid_grad_custom
):
print(f"Pass on {device}")
else:
print(f"Error: results mismatch on {device}")基于计算图的性能优化
torch.compile
torch.compile是一个极其复杂的系统,它覆盖了诸多领域,包括计算图的提取、优化以及跨后端的代码生成。
但实际使用并不需要深入了解所有的实现细节,因为启用它只需简单一行代码。
让我们用一个例子来展示torch.compile的开启方法,并观察其性能优化效果:
import torch
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(1000, 20000)
def forward(self, x):
x = torch.relu(self.fc1(x))
y = x
for _ in range(50):
y = y * x
return y
# 未经优化的模型
model = SimpleNet().cuda()
# 打开torch.compile追踪模型的执行过程并自动优化
compiled_model = torch.compile(model)
def timed(fn):
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
start.record()
result = fn()
end.record()
torch.cuda.synchronize()
return result, start.elapsed_time(end) / 1000
N_ITERS = 5
def benchmark(model):
times = []
for i in range(N_ITERS):
input_data = torch.randn(1000, 1000, device="cuda")
_, time = timed(lambda: model(input_data))
times.append(time)
return times
print("eager模式", benchmark(model))
print("打开torch.compile后", benchmark(compiled_model))
# 输出
# eager模式 [1.1121439208984376, 0.01659187126159668, 0.01635430335998535, 0.016350208282470705, 0.016306175231933593]
# 打开torch.compile后 [1.79336083984375, 0.002367487907409668, 0.0022937600612640383, 0.002292736053466797, 0.002288640022277832]性能的提升其实主要有两个来源: - 一方面是计算图一旦编译好,其生成的代码会被缓存起来,后续循环中可以直接调用编译好的计算图,而省去了算子单独调用的额外开销; - 另一方面则是torch.compile进行了一定的图优化,包括而不限于算子的融合、替换等,其最终生成的高性能triton算子也是性能提升的来源之一。
torch.compile还有一些常见的参数: - fullgraph=True:开启完整的计算图优化,包括控制流、条件分支等;一旦计算图发生中断,系统会立即报错,帮助用户及时发现并处理潜在的图断裂问题 - dynamic=True:开启动态图优化,支持对动态图中张量形状不断变化的场景; - mode="reduce-overhead":减少从CPU到GPU的调用次数(CUDA graph能够通过记录一系列GPU操作,如内核执行和内存拷贝,创建一个可重用的GPU操作序列)
计算图的提取
计算图在有些情况下会和实际的python代码逻辑相关,比如:
class DataDependentNet(nn.Module):
def __init__(self):
super(DataDependentNet, self).__init__()
self.linear1 = nn.Linear(10, 5)
self.linear2 = nn.Linear(5, 2)
self.linear3 = nn.Linear(5, 3)
def forward(self, x):
tmp = F.relu(self.linear1(x))
# 有数据依赖的控制流:如果x的第一个元素大于0.5,使用linear2,否则使用linear3
if tmp[0, 0] > 0.5:
return self.linear2(tmp)
else:
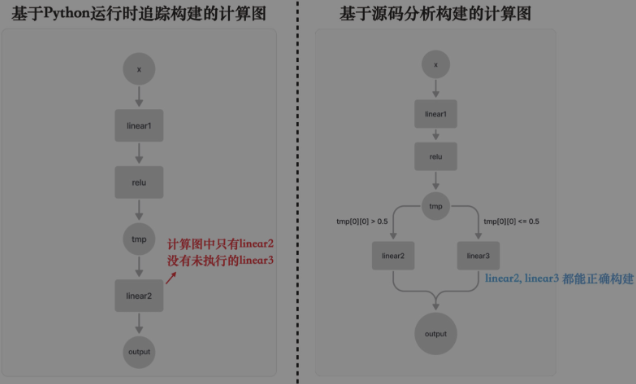
return self.linear3(tmp)基于Python运行时的跟踪(tracing)方法本质上是在模型执行过程中动态捕捉计算图, 也就是通过监视PyTorch操作的执行,来实时记录这些操作及其上下游之间的依赖关系。 这种方法能够准确捕获模型实际执行时的行为,并且几乎可以无视控制流的影响——只捕获实际执行的分支即可,未被执行的分支就不放在计算图里了。 如图中左半部分所示,我们仅捕捉到了linear2这个操作,linear3操作由于其分支没有被执行便没有出现在计算图中。 JIT tracing、lazy tensor和torch.compile都是基于跟踪的方法。
基于源码分析的方法能够识别Python中的控制流结构,如if-else和for循环,同时将所有相关操作提取至同一计算图中,从而最大化保持图的完整性。 这种方法的典型工具是TorchScript。拥有一张完整计算图的全局信息对图优化极为有利。 然而,在实际应用中,TorchScript很难完全支持所有Python语言特性,使用时可能需要对原始代码进行调整,这可能影响代码的结构和灵活性。 总的来说,当TorchScript能够顺利运行时,它能提供非常优异的性能,但为了让它能跑起来,用户可能需要在代码的编写上做出较大的妥协。
我们再来看看torch.compile的计算图提取以及优化过程: - 1.
字节码分析:Python代码在执行前会被编译成字节码,这是一种平台无关的中间表示形式。CPython提供了内部接口,可以在运行时分析这些字节码。
- 2. 捕获张量操作:
使用torch.compile和Torch
Dynamo技术,PyTorch在运行时捕获张量操作 - 3.
动态生成计算图:根据实际运行时的数据和操作,动态生成计算图。
- 4.
优化计算图:生成的计算图可以被进一步优化,以提高执行效率,优化过程可能包括操作融合、内存优化、常量折叠等。
- 5.
生成高效执行代码:优化后的计算图用于生成更高效的执行代码,执行时将取代原来Python解释器中的函数调用。
- 6.
回退机制:如果遇到难以转换成图的代码,torch.compile会中断图的构建,程序会回退到标准的Python解释器来处理。
- 7.
透明的用户体验:对用户而言,整个过程是透明的。用户仍然编写标准的Python代码,但在执行过程中,torch.compile自动识别并优化可改进的部分。
- 8. AOT
Autograd技术:torch.compile不仅捕获用户的前向代码,还能捕获反向传播的计算图。
通过这些步骤,torch.compile在不改变用户代码的情况下,自动优化PyTorch程序的执行效率。
图的优化和后端代码
不管是基于运行时跟踪还是基于源码分析的方法,在获得计算图之后,torch.compile利用后端(如默认的inductor后端)来执行的优化是几乎一致的。 这些优化主要基于后端的特定策略和硬件的技术,而不是传统编译器所采用的标准优化流程。
例如,当前的代码生成主要关注提高算子的计算效率,这需要通过算子融合、数据布局转换以及利用特定硬件的指令集来实现。 这样做的目的是为了减轻开发者手动编写每个自定义算子的负担。
之前的示例代码中使用PyTorch
profiler打印其性能图谱,从图中以看出torch.compile在底层生成了triton算子,
该算子将原本的乘法算子、ReLU算子融合在了一起。 
在设置环境变量TORCH_COMPILE_DEBUG=1后重新执行代码我们还可以看到torch.compile生成的triton代码,
比如下面代码是由inductor后端生成的将relu和50个mul算子融合成一个算子的triton代码。
@pointwise(
size_hints=[33554432],
filename=__file__,
triton_meta={
"signature": {0: "*fp32", 1: "*fp32", 2: "i32"},
"device": 0,
"device_type": "cuda",
"constants": {},
"configs": [
instance_descriptor(
divisible_by_16=(0, 1, 2),
equal_to_1=(),
ids_of_folded_args=(),
divisible_by_8=(2,),
)
],
},
inductor_meta={
"autotune_hints": set(),
"kernel_name": "triton_poi_fused_mul_relu_0",
"mutated_arg_names": ["in_out_ptr0"],
},
min_elem_per_thread=0,
)
@triton.jit
def triton_(in_out_ptr0, in_ptr0, xnumel, XBLOCK: tl.constexpr):
xnumel = 20000000
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:]
xmask = xindex < xnumel
x0 = xindex
tmp0 = tl.load(in_ptr0 + (x0), xmask)
tmp1 = triton_helpers.maximum(0, tmp0)
tmp2 = tmp1 * tmp1
tmp3 = tmp2 * tmp1
... # 篇幅原因省略中间的行
tmp49 = tmp48 * tmp1
tmp50 = tmp49 * tmp1
tmp51 = tmp50 * tmp1
tl.store(in_out_ptr0 + (x0), tmp51, xmask)小结
实际开发中,建议按照如下顺序来尝试这些高级优化技巧: - 首先推荐尝试使用torch.compile,因为其开启方法简单且几乎没有副作用。 只需在训练模型外层添加torch.compile,并观察性能变化即可。 如果性能下降或torch.compile提示“回退到Eager模式”,则说明当前网络结构无法直接被torch.compile优化
其次,推荐尝试自动混合精度训练,因为半精度训练通常能显著提升性能。 尽管对收敛性和模型质量可能有一定影响,但大多数模型在开启自动混合精度训练后,仍能达到与单精度训练相似的结果。 然而,使用自动混合精度训练时应保持谨慎,需要仔细验证收敛性。因此,自动混合精度训练是一种有潜在风险的优化方法。
最后,尝试自定义算子的优先级,其投入产出比相对较低且不确定性较大。 通常仅建议在需要极致性能优化的场景下尝试自定义算子。 熟悉CUDA和CPU加速且具备高性能计算背景的开发者,可以通过自行编写高性能算子来优化特定应用场景。 另一种选择是使用开源算子库,不过第三方算子库往往存在局限性或副作用,未必能直接应用于自己的模型,且实际优化效果不可控。



