Norm
归一化策略主要是为了加强神经网络训练过程的稳定性,具体来说可以归纳为以下几点:
- 加速收敛:归一化可以减少内部协变量偏移(internal covariate shift)以使得输入数据的分布更加均匀,学习过程中不用再考虑数据分布的影响,尤其是在初始化过程中是的模型可以快速适应,收敛更快。
- 稳定性:归一化策略可以使得梯度更加稳定,减少了梯度爆炸和梯度消失的可能性。
- 缓解过拟合:归一化带有正则化效果(由于批次的随机性引入了噪声),对训练集和测试集的分布差异进行约束,使得模型在训练集和测试集上的表现更加一致,缓解过拟合。
NLP中的Norm
对于批量大小为B,序列长度为L,隐藏维度为H的输入:
LayerNorm
计算每一层中所有激活值的均值 𝝁 和方差 𝝈,从而重新调整激活值的中心和缩放比例:
\[ \mu = \frac{1}{H} \sum_{i=1}^{H} x_{i} \]
\[ \sigma = \sqrt{\frac{1}{H} \sum_{i=1}^{H} (x_{i} - \mu)^{2}} \]
\[ LayerNorm(x) = \frac{x - \mu}{\sigma}\cdot\gamma + \beta \]
其中\(x\)是单个词元的激活值,\(x_{i}\)是索引i上的数值,可以看出,LayerNorm的计算是沿着H维度进行的,对每一层的词元向量进行归一化。
RMSNorm
为了提高层归一化的训练速度,RMSNorm仅利用激活值总和的均方根 RMS(𝒙) 对激活值进行重新缩放。 \[ RMS(x) = \sqrt{\frac{1}{H} \sum_{i=1}^{H} x_{i}^{2}} \]
\[ RMSNorm(x) = \frac{x}{RMS(x)}\cdot\gamma \]
DeepNorm
DeepNorm 在 LayerNorm 的基础上,在残差连接中对之前的激活值 𝒙 按照一定比例 𝛼 进行放缩。通过这一简单的操作,Transformer 的层数可以被成功地扩展至 1,000 层,进而有效提升了模型性能与训练稳定性。
\[ DeepNorm(x) = LayerNorm(\alpha\cdot x + sublayer(x)) \]
其中sublayer(x)是残差连接中的前馈神经网络或者注意力块。
CV中的Norm
假设输入为B,H,W,C,其中B是batch size,H和W是空间维度,C是通道数。
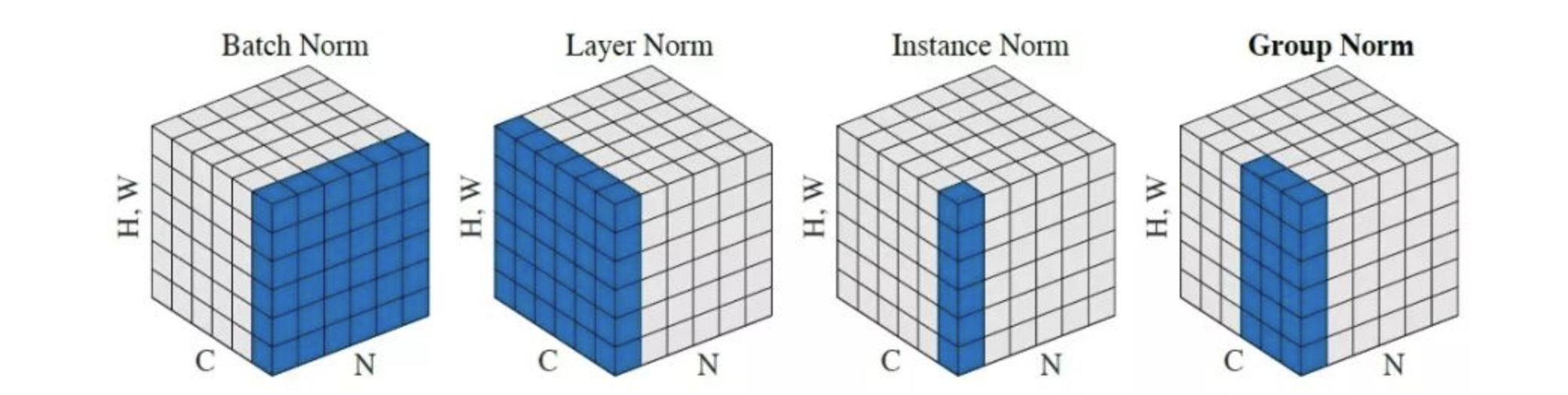
BatchNorm
跨样本的归一化:针对每个神经元,使数据在进入激活函数之前,沿着通道计算每个batch的均值、方差,‘强迫’数据保持均值为0,方差为1的正态分布。
LayerNorm
单个样本跨通道的归一化:对单个样本,计算所有通道在一起的均值、方差,然后跨通道进行归一化。
InstanceNorm
单个样本单通道的归一化:对单个样本,计算单通道的均值、方差,然后按照通道各自进行归一化。
GroupNorm
将通道分组,每个组内计算均值、方差,然后组内归一化。
InstanceNorm和GroupNorm常用于图像风格迁移
LN 在CV和NLP中的区别
CV中的LN是单个样本按照C、H、W共同计算均值和方差, 而NLP中的LN是单个词元按照H维度计算均值和方差。 可以看出,NLP中的LN归一化的粒度比CV中的LN更细。
如果把CV中的输入BxCx(HxW)类比NLP中的输入BxLxH,那么CV中的IntanceNorm才相当于NLP中的LN。
为什么NLP中不用BN
BN难以处理可变长度的序列数据和小批次数据。 - 可变长度的序列数据:BN对于不同长度的序列数据中的填充部分,会计算出错误的均值和方差,导致性能下降。 - 小批次数据:BN需要较大的批次大小才能获得稳定的均值和方差,否则会导致性能下降,而transformer中一般batch size较小,所以BN效果不好。
LN则没有这些问题,因为LN是沿着H维度计算均值和方差,与序列长度无关,因此可以处理可变长度的序列数据和小批次数据。
为什么CV中BN比LN更常用
- 批次大小:CV中一般batch size较大,BN效果较好。
- 卷积操作:卷积神经网络(CNN)中的卷积操作通常在空间维度上共享权重,BN可以在每个通道上进行归一化,这与卷积操作的特性相匹配。
激活函数
激活函数应该具备哪些特性?
- 必须
- 非线性
- 定义域全体实数
- 几乎处处可微,最好导数计算简单
- 最好有
- 非饱和,防止出现梯度对数据变化不敏感,导致梯度消失, 但有反例:sigmoid/tanh
- 无上界有下界:无上界同上,有下界有助于正则效果。
- 单调,导数符号不变,梯度更新方向稳定,但有反例:GELU
- 带有非零负值梯度,梯度更新效率快, 但有反例:ReLU
常见激活函数
- Sigmoid/tanh 梯度饱和问题,sigmoid的范围在0-1中,在一些需要预测结果也在0-1的任务中用,比如bbox的偏移预测。
- ReLU 带有非零负值或者原点平滑的版本:
- LeakyReLU
- SiLU: x*sigmoid(x)
- Swish:x * (1 / (1 + np.exp(-beta * x))), beta=1时就是SiLU,很多时候也直接把SiLU作为Swish。
- GELU: x*norm.cdf(x), cdf为标准状态发布的分布函数,往左趋于0,往右趋于1。
- Mish:x*tanh(ln(1+epx(x)))
- GLU(门控线性单元): sigmoid(W1(x)) 逐元素乘以
W2(x)-----------两个不同的线性层,三个权重矩阵(x经过SwiGlu后再过一个线性层,总共三个权重矩阵。由于原始FFN中参数量为8h^2
(两个线性层,每个4h2),改为SwiGLU后的单个权重大小为8h2
/3。)
- SwiGLU: GLU中的激活函数变为Swish
- GeGLU: GLU中的激活函数变为GELU
- softmax 多分类问题(转为不同类别的概率)
大模型中使用SwiGLU的好处(除了类似ReLU的好处):并行计算:sigmoid(W1(x)) 和 W2(x) 可以并行计算。



