Q-former 是 BLIP2 中提出的一个模块,目的在于从视觉编码器中提取出与文本最相关的视觉表示,而这种表示能够为大语言模型所解释。
1.BLIP2
1.1 组成
BLIP-2 由以下三个主要组件组成:
Image Encoder:从输入图片中提取视觉特征。文中采用了两种不同的网络结构:CLIP 训练过的ViT-L/14 和 EVA-CLIP 训练过的 ViT-g/14。
Large Language Model (LLM):大语言模型进行文本生成。文中尝试了两种不同的网络结构:decoderbased LLM 和 encoder-decoder-based LLM。
Q-Former:弥补视觉和语言两种模态间的差异,实现跨模态间的对齐。Q-Former 使用了一组可学习的查询向量(Queries)来从冻结的 Image Encoder 中提取视觉特征,然后传入 LLM供其生成文本。Q-Former 的结构由 Image Transformer 和 Text Transformer 两个子模块构成,它们共享相同的自注意力层:
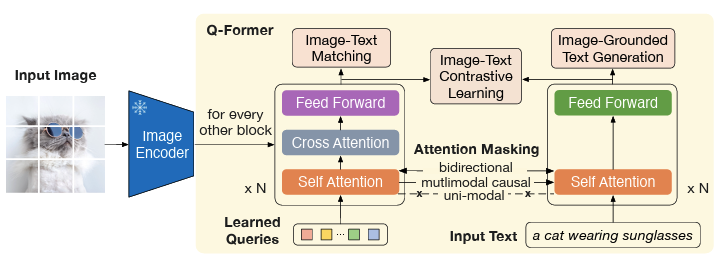
Image Transformer:用于与冻结的图像编码器进行交互,从中提取一定数量的输出特征。
Text Transformer:既可以作为文本编码器,也可以作为文本解码器。它创建一组可学习的 Queries 作为 Image Transformer 的输入,这些 Queries 在 Image Transformer 中通过自注意力层相互作用,并通过交叉注意力层与冻结的图像特征进行交互。
1.2 训练方式
BLIP2基于Q-Former,设计了一套两阶段的训练方式:
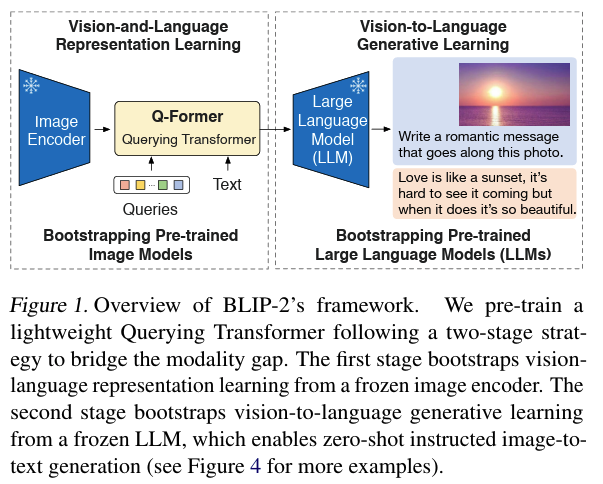
阶段一:表示学习(representation learning),迫使Q-Former学习和文本最相关的视觉表示。
阶段二:生成学习(generative learning),将Q-Former的输出连接到冻结的大语言模型,迫使Q-Former学习到的视觉表示能够为大语言模型所解释。
1.3 推理流程
Image Encoder 接收图像作为输入,输出图像的视觉特征。
Q-Former 接收文本和Image Encoder 输出的图像视觉特征,结合查询向量进行融合,学习与文本相近的视觉特征,输出 LLM 能够理解的视觉表示。
LLM 模型接收 Q-Former 输出的视觉标识,生成对应文本。
2. 预训练
2.1 表示学习阶段
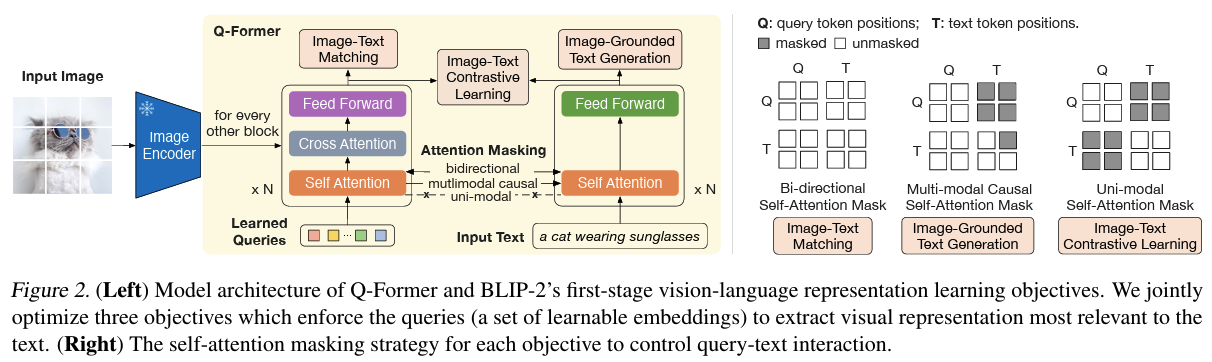
在表示学习阶段,Q-Former 被连接到冻结的 Image Encoder,训练集为图像-文本对。
通过联合优化三个预训练目标,Q-Former 学习到高质量的跨模态对齐表示。
为了控制 Image Transformer 和 Text Transformer 的交互方式, Q-Former 在 Query和 Text 之间采用了不同的注意力掩码策略。
2.1.1 图文对比学习学习(ITC)
ITC 目标旨在学习图像和文本之间的对齐关系,让正样本对(匹配的图像-文本对)的特征在特征空间中距离更近,而负样本对(不匹配的图像-文本对)的特征距离更远。
- 相似度计算
- Text Transformer 的文本嵌入是[CLS] 标记的输出嵌入\(T_{cls}\),而 Query 嵌入包含多个输出嵌入\(Q_i\)。计算每个 Query 嵌入与文本嵌入的相似度,选择最高的一个作为图像-文本相似度。
- 通常使用点积相似度 \(s(Q_i,T_{cls})=Q_i^T T_{cls}\)。
- 单模态自注意力掩码(uni-modal self-attention mask):为了避免信息泄漏,ITC 采用单模态自注意力掩码,禁止 Query 和 Text 之间的直接交互。
- 损失函数:NCE loss
2.1.2 基于图像的文本生成(ITG)
ITG 的目标是在给定输入图像作为条件的情况下,训练 Q-Former 生成文本,迫使 Query 提取包含文本信息的视觉特征。
- 由于 Q-Former 的架构不允许冻结的图像编码器和文本标记之间的直接交互,生成文本所需的信息必须由 Query 提取,并通过自注意力层传递给文本标记。
- 多模态因果注意力掩码(multi-modal causal attention mask):ITG 采用多模态因果注意力掩码,允许 Query相互关注,但不能关注Text 标记。每个 Text 标记可以处理所有 Query 及其前面的 Text 标记。
- 将[CLS] 标记替换为新的[DEC] 标记,作为第一个文本标记来指示解码任务。
- 损失函数:交叉熵损失
2.1.3 图文匹配学习(ITM)
ITM 的目标是细粒度判断图文对是否匹配,从而增强模态对齐的局部一致性。
- 将Image Transformer 输出的每个query 嵌入输入到一个二分类线性分类器中,获得对应的logit。将所有logit 平均,计算匹配分数。
- ITM 使用双向自注意力掩码(bi-directional self-attention mask),允许所有 Query 和 Text 之间相互关注。
- 损失函数:交叉熵损失
2.2 生成学习阶段
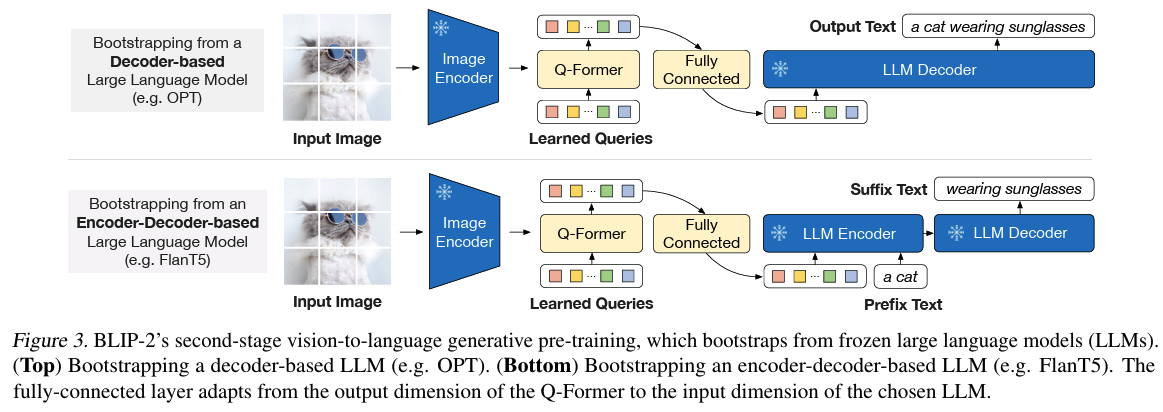
在生成学习阶段,Q-Former 被连接到冻结的LLM,以利用LLM 的语言生成能力。具体步骤如下:
特征投影:使用全连接层将 Q-Former 输出的 Query 嵌入线性投影到与 LLM 文本嵌入相同的维度。
输入构造:将投影后的 Query 嵌入添加到输入文本嵌入的前面。
生成任务:由于 Q-Former 已经过预训练,能够提取包含语言信息的视觉表示,因此它可以作为信息瓶颈,将最有用的信息传递给 LLM,同时过滤不相关的视觉信息,减轻 LLM 学习视觉-语言对齐的负担。
BLIP2 试验了两种类型的 LLM:
基于解码器的LLM:使用语言建模损失进行预训练,冻结的 LLM 根据 Q-Former 的视觉表示生成文本。
基于编码器-解码器的LLM:使用前缀语言建模损失进行预训练,将文本分为前缀和后缀两部分。前缀文本与视觉表示连接作为 LLM 编码器的输入,后缀文本作为 LLM 解码器的生成目标(类似LLM前缀编码器+解码器架构)
参考文献
BLIP2: https://arxiv.org/abs/2301.12597



