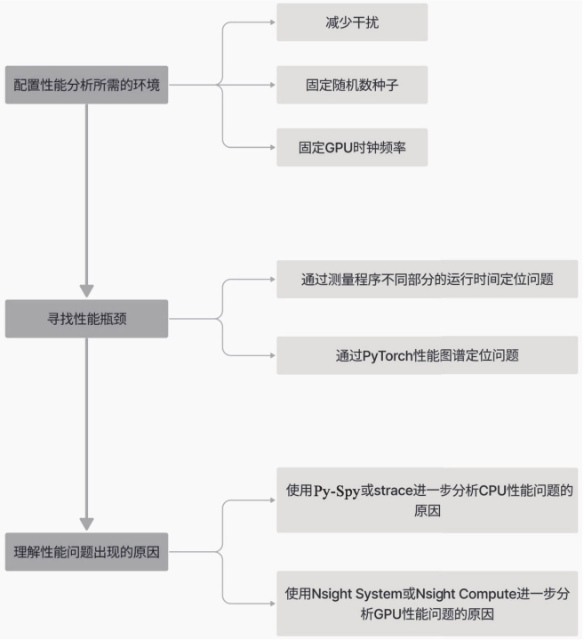
性能瓶颈定位工具
为了保证分析结果的可靠性,对测试环境的稳定性有一定要求。由于程序运行的软件和硬件环境中影响因素较多,本节将根据重要性排序,依次介绍提升测试稳定性的方法。
减少无关程序的干扰
为了保证分析结果的可靠性,对测试环境的稳定性有一定要求。由于程序运行的软件和硬件环境中影响因素较多,本节将根据重要性排序,依次介绍提升测试稳定性的方法。
GPU使用情况
首先可以通过nvidia-smi监控GPU使用情况(nvtop命令提供了更友好的交互界面,适合监督训练过程)
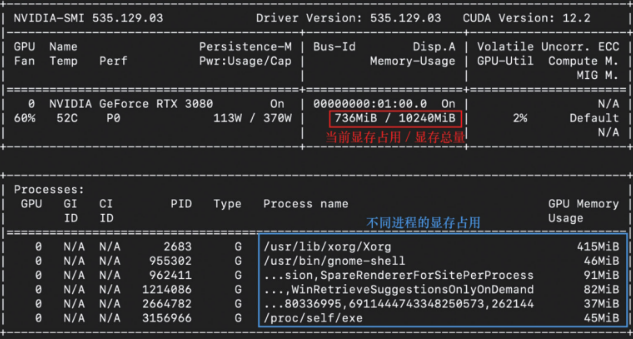
查看相应进程的更多信息:ps aux | grep <PID>
杀掉进程:kill -9 <PID> (-9
表示强制杀死进程)
有条件的读者还应避免在GPU的性能优化过程中使用图形界面,因为图形界面也会占用GPU资源,比如上图中的/usr/bin/Xorg.bin就对应了图形界面进程。可以考虑停止UNIX系统的图形用户界面服务,之后通过另一台机器进行SSH远程登录。
CPU使用情况
可以通过htop这一系统监视工具来查看CPU使用情况。
如果发现CPU使用率偏高——比如大部分CPU核心的占用率长时间在60%~70%以上,还可以通过进程列表来查询使用CPU最多的进程,并决定是否将其终止。
提升PyTorch程序的可重复性
前面着重讨论了如何避免其他程序的干扰,尽可能让目标程序独占计算资源,降低性能波动。 但是程序内部也存在着一定的随机性,如模型权重的随机初始化/Dropout层随机失活,在本小节中,我们会专门介绍约束程序随机性的方法。
在Python生态系统中缺乏一个统一的随机数生成标准库。NumPy、PyTorch和TensorFlow等库在处理随机数生成时,各自有不同的实现和优化方式,因此,没有一个统一的方法可以集中控制Python程序中所有库的随机数种子,在写程序时,需要考虑不同库的随机数生成方式。
这里只介绍Pytorch、NumPy和python标准库random的随机数种子设置方法。
设置PyTorch随机数种子
PyTorch提供了一个torch.manual_seed()接口可以“一键设置”所有后端的随机数生成种子,以确保每次运行代码时,生成的随机数序列都是相同的。
import torch
def generate_random_seq(device):
return torch.rand((3, 3), device=device)
print(
f"""不设置随机种子时,每次运行生成的序列都是不同的
CPU: {generate_random_seq('cpu')}
CUDA: {generate_random_seq('cuda')}"""
)
# 为所有PyTorch后端设置生成随机数的种子
seed = 32
torch.manual_seed(seed)
print(
f"""设置随机种子后,每次运行都会生成相同的序列
CPU: {generate_random_seq('cpu')}
CUDA: {generate_random_seq('cuda')}"""
)设置NumPy随机数种子
numpy提供了numpy.random.seed()接口,可以设置NumPy的随机数种子。
import numpy as np
def generate_random_seq():
return ", ".join([f"{np.random.random():.2f}" for _ in range(10)])
print(f"不设置随机种子时,每次运行生成的序列都是不同的: {generate_random_seq()}")
np.random.seed(32)
print(f"设置随机种子后,每次运行都会生成相同的序列: {generate_random_seq()}")设置python随机数种子
python的random模块提供了random.seed()接口,可以设置python标准库的随机数种子。
import os
import random
def generate_random_seq():
return ", ".join([f"{random.random():.2f}" for _ in range(10)])
print(f"不设置随机种子时,每次运行生成的序列都是不同的: {generate_random_seq()}")
seed = 32
random.seed(seed)
print(f"设置随机种子后,每次运行都会生成相同的序列: {generate_random_seq()}")其他随机性因素
虽然设置随机数种子能控制一部分Python代码的随机性,但并不能完全消除随机性。因为随机性的来源很多,比如哈希算法就是其中之一。如果用到了基于哈希算法的如hash()函数,或者set的遍历,为了确保程序的可复现性,就需要设置环境变量PYTHONHASHSEED,代码如下。
python -c 'print(hash("hello"))' # 跑多次结果是不一样的
PYTHONHASHSEED=0 python -c 'print(hash("hello"))' #跑多次结果是一样的甚至有一些随机性是无法控制的,例如使用Python的glob模块获取的文件列表顺序可能是不确定的,这个顺序会受到操作系统和文件系统类型等多种因素的影响。如果在调试过程中需要可复现性,要求文件以特定顺序出现,那么我们就需要在获取文件列表后,手动对这些文件进行排序。
约束GPU算子的随机性
GPU的计算特点与CPU存在一些差别,这尤其体现在数值精度方面。
首先在硬件底层,浮点运算的机制及其硬件实现可能导致结合律在某些情况下不适用,由于其并行处理的特性,进行大量的数值累加时,累加的顺序可能不固定,从而可能进一步放大这种数值差异。
其次,NVIDIA提供的cuDNN加速库还在软件层面上进一步加重了数值的不确定性。以卷积算法为例,cuDNN提供了不同版本的卷积实现方法,会根据情况临时选择其中性能最高的一种进行卷积计算,这就导致其计算结果更加的不可控。除此以外,如果算子实现过程中用到了随机采样的算法,那么采样的随机性同样也会对结果产生影响。
不过对于cuDNN相关的操作,PyTorch还是提供了torch.backends.cudnn.deterministic和torch.backends.cudnn.benchmark接口,二者结合使用可以最大程度提高GPU计算结果的稳定性,使用方法如下所示:
torch.backends.cudnn.deterministic = True # 确保算子使用确定性算法
torch.backends.cudnn.benchmark = False # 禁用自动优化(如卷积算法)但是这两个接口都可能导致GPU计算性能下降,所以尽量只在需要调试程序或者进行性能分析时开启。
完整的随机性约束脚本
使用以下脚本可以一键设置前文介绍的所有随机种子,代码如下:
def set_seed(seed: int = 37) -> None:
np.random.seed(seed)
random.seed(seed)
torch.manual_seed(seed) # 适用于所有PyTorch后端,包括CPU和所有CUDA设备
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
os.environ["PYTHONHASHSEED"] = str(seed)
print(f"设置随机数种子为{seed}")控制GPU频率
GPU在实际运行过程中会根据芯片状态动态调整显存频率和基础频率来自动平衡性能和功耗。对于性能分析而言,我们需要GPU始终保持在相同的频率进行测试,从而降低数据波动。可以使用如下指令来锁定GPU的频率:
# 查询 GPU显存频率、流处理器频率、图形频率
nvidia-smi --query-gpu=pstate,clocks.mem,clocks.sm,clocks.gr --format=csv
# clocks.current.memory [MHz], clocks.current.sm [MHz], clocks.current.graphics [MHz]
# 9751 MHz, 1695 MHz, 1695 MHz
# 查询GPU支持的clock组合
nvidia-smi --query-supported-clocks=gpu_name,mem,gr --format=csv
# 设置persistent mode,可以减少GPU初始化延迟
sudo nvidia-smi -pm 1
# 固定GPU时钟
nvidia-smi -ac 9751,1530 # <memory, graphics>注意AI GPU如V100、A100等是支持锁频功能的,但一些家用级别GPU可能不支持锁频(如RTX3090、4090系列),这时锁频指令会显示下述信息:
Setting applications clocks is not supported for GPU 00000000:1A:00.0.
Treating as warning and moving on.控制CPU的状态和频率
一个CPU的性能状态被划分为不同的等级,称为性能状态(Performance state, P-state)。每个P-state对应于一组特定的工作频率和电压。
在进行性能测量时,我们希望固定P-state和CPU频率,确保在每次运行基准测试时处理器以相同的性能状态运行。
首先需要安装cpufrequtils软件包,并通过设置最大、最小频率来间接控制住CPU的状态,代码如下:
sudo apt-get install cpufrequtils
# 设置最大、最小频率
sudo cpufreq-set -r -g performance # 设置为性能模式, -r 表示所有CPU核心 -g 表示性能模式
sudo cpufreq-set -r -d 2Ghz # 设置最小频率为2GHz
sudo cpufreq-set -r -u 2Ghz # 设置最大频率为2GHz# 查询
cpufreq-info
# 或者
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_cur_freq
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_max_freq另外,还可以在驱动或BIOS层面进一步关闭一些对性能有影响的CPU特性,例如: - 设置max_cstate为1来阻止CPU进入低功耗状态,在计算机系统中C-state是指处理器的不同功耗状态,其中C0表示处理器处于活动状态,而C1、C2、C3等表示不同的睡眠状态,功耗逐渐降低。 - 可以关闭超线程和睿频等高级功能。
# 查询C_state
cat /sys/module/intel_idle/parameters/max_cstate
# 查询turbo状态
cat /sys/devices/system/cpu/intel_pstate/no_turbo精确测量程序运行时间
计量CPU程序的运行时间--time模块
time.time()或者time.perf_counter()计算两个时间戳的间隔。
import time
start = time.perf_counter()
# 程序运行
end = time.perf_counter()
print(f"程序运行时间: {end - start}秒")warmup和多次运行取平均
计算机程序具有冷启动效应。具体到训练过程来说,一般最初几轮训练的单轮耗时要显著多于平稳运行时每轮的耗时,这主要是设备初始化、缓存命中、代码初次加载等诸多因素导致的。因此如果希望得到一致性更强的性能测试结果,就需要在正式测量前先进行几轮热身(warmup),从而让系统达到稳定状态。除了程序预热以外,还应该测试多轮训练取平均值,进一步增加测试结果的稳定性。
import time
import torch
def my_work():
# 需要计时的操作
sz = 64
x = torch.randn((sz, sz))
if __name__ == "__main__":
# 热身
num_warmup = 5
for i in range(num_warmup):
start = time.perf_counter()
my_work()
end = time.perf_counter()
t = end - start
print(f"热身#{i}: {t * 1000 :.6f}ms")
# 多次运行取平均
repeat = 30
start = time.perf_counter()
for _ in range(repeat):
my_work()
end = time.perf_counter()
t = (end - start) / repeat
print(f"{repeat}次取平均: {t * 1000:.6f}ms")
# 热身#0: 0.317707ms
# 热身#1: 0.023586ms
# 热身#2: 0.016913ms
# 热身#3: 0.016409ms
# 热身#4: 0.015868ms
# 30次取平均: 0.014164ms利用CPU/GPU同步计量GPU的运行时间--torch.cuda.synchronize()
如大模型动力引擎-PyTorch所述,CPU和GPU之间的操作是异步的。由于Python解释器在CPU上运行,使用time.perf_counter()记录的时间实际上是CPU的时间戳。
若CPU没有等待GPU任务完成就记录时间的话,测量结果就是错的,通常会比实际程序运行时间短很多。
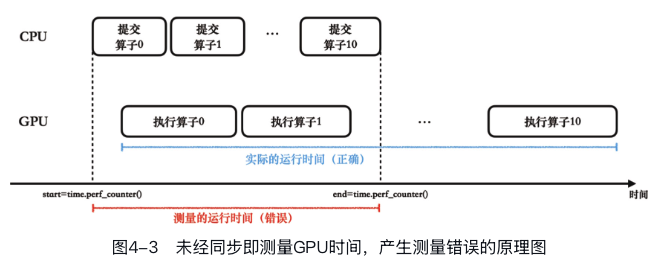
因此必须让CPU先等待GPU运行完成,也就是调用torch.cuda.synchronize()结束再记录时间戳。代码如下所示:
import time
import torch
sz = 512
N = 10
shape = (sz, sz, sz)
x = torch.randn(dtype=torch.float, size=shape, device="cuda")
y = torch.randn(dtype=torch.float, size=shape, device="cuda")
torch.cuda.synchronize()
start = time.perf_counter()
for _ in range(N):
z = x * y
# 同步
torch.cuda.synchronize()
end = time.perf_counter()
print(f"{N}次运行取平均: {(end - start) / N}s")精确计量GPU的运行时间--torch.cuda.Event()
联合使用torch.cuda.synchronize()和time.perf_counter()来计量GPU程序的运行时间会因为同步过程产生一定延迟,所以使用上面的CPU时间戳间隔测量的GPU耗时是要略长于GPU算子实际运行时间的。
可以通过建立torch.cuda.Event()对象,随后利用其record()方法在GPU队列中进行标记,最后通过两个CUDA
Event的时间间隔来测量GPU运行时间:
import torch
sz = 512
shape = (sz, sz, sz)
x = torch.randn(dtype=torch.float, size=shape, device="cuda")
y = torch.randn(dtype=torch.float, size=shape, device="cuda")
start = torch.cuda.Event(enable_timing=True) # -enable_timing=True 表示启用时间测量
end = torch.cuda.Event(enable_timing=True)
start.record()
z = x + y
end.record()
print(f"用时{start.elapsed_time(end)}ms")PyTorch的性能分析器--torch.profiler
PyTorch原生的torch.profiler在与Perfetto UI进行联用之后能够很好地兼顾使用的易用性和性能指标的信息量。
性能分析
import torch
import torchvision.models as models
from torch.profiler import profile, record_function, ProfilerActivity
model = models.resnet18().cuda()
inputs = torch.randn(5, 3, 224, 224, device="cuda")
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA]) as prof: # 指定分析CPU和GPU
with record_function("model_inference"): # 对不同代码段进行标记
model(inputs)
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10)) # 打印分析结果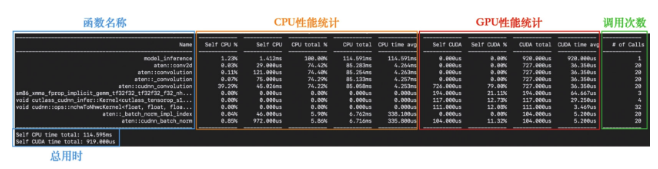
显存分析
torch.profiler可以追踪每个算子在执行时分配的显存大小,可以间接用来定位显存峰值出现的位置:
import torch
import torchvision.models as models
from torch.profiler import profile, record_function, ProfilerActivity
model = models.resnet18().cuda()
inputs = torch.randn(5, 3, 224, 224, device="cuda")
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], profile_memory=True) as prof:
model(inputs)
print(prof.key_averages().table(sort_by="self_cuda_memory_usage", row_limit=5))
不过这里的信息比较笼统,只能对每个算子的内存占用有个大致了解,如果想要专门对显存进行优化,则推荐使用PyTorch原生的显存工具torch.cuda.memory._record_memory_history()。(后续讲解)
可视化性能图谱
导出用于可视化分析的文件:
prof.export_chrome_trace("profiler_export_trace.json")

如何定位性能瓶颈
PyTorch Profiler还可以记录调用栈信息,对于将问题定位回Python代码非常有帮助。对于绝大多数场景而言,我们可以通过如下标准流程来查找性能瓶颈: - (1)观察GPU队列,如果GPU队列整体都非常稀疏,那么性能瓶颈在CPU上。 - (2)观察GPU队列,如果任务队列密集,而没有显著空白区域,说明GPU满载,那么性能瓶颈在GPU算子。 - (3)观察GPU队列,如果任务队列密集,同时存在GPU空闲区域,则需要放大空闲区域进行进一步观察。 - (4)观察GPU空闲区域,查看空闲前后GPU任务以及CPU任务详情,并以此推断导致GPU队列阻塞的原因。
定位瓶颈的示例:
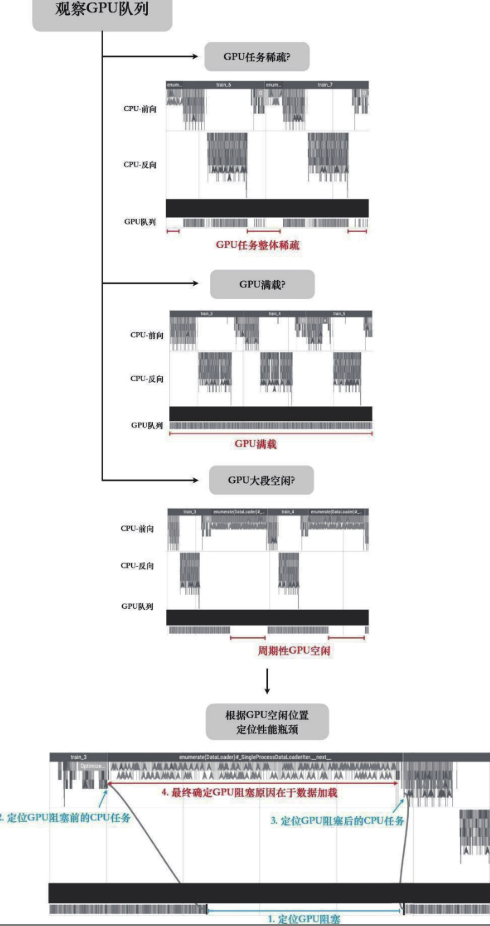
GPU专业分析工具
对于绝大多数性能分析的场景使用PyTorch Profiler就绰绰有余了,然而当需要进行更高级的优化时,我们可能希望拿到更加深入底层的性能数据。在这些情况下,我们需要转向NVIDIA官方提供的更为专业的性能分析工具。因此在本节我们重点介绍Nsight Systems和Nsight Compute两种专业分析工具。
Nsight Systems
- Nsight Systems是非侵入式的性能分析工具,不需要对代码进行任何改动;PyTorch Profiler则需要在代码中添加torch.profiler等函数。
- Nsight Systems能够显示更详细的信息,包括操作系统、CUDA API、通信等层面的信息,对多GPU性能分析的支持也更加完善。
Nsight Compute
Nsight Systems是对PyTorch Profiler的补充,二者还是属于相同层级的分析工具;Nsight Compute则是完全专注于底层GPU内核函数的性能指标的分析工具。Nsight Compute提供的信息多而庞杂,同时收集性能信息的速度非常慢,所以往往只用来分析较小的代码段。具体到训练过程来说,一般只有在优化CUDA算子时才会考虑使用Nsight Compute用于定位算子内部的性能瓶颈。
我们用Nsight Compute分析一个完整模型的训练过程,尽管它多用于分析单个算子,代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(20, 50, 5)
self.fc1 = nn.Linear(50 * 4 * 4, 500)
self.fc2 = nn.Linear(500, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = self.pool(torch.relu(self.conv2(x)))
x = x.view(-1, 50 * 4 * 4)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
net = SimpleCNN().to("cuda")
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for i in range(10):
inputs = torch.randn(32, 1, 28, 28, device="cuda")
labels = torch.randint(0, 10, (32,), device="cuda")
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
当Nsight Compute完成分析后,首先出现的界面是一个总结界面(summary):
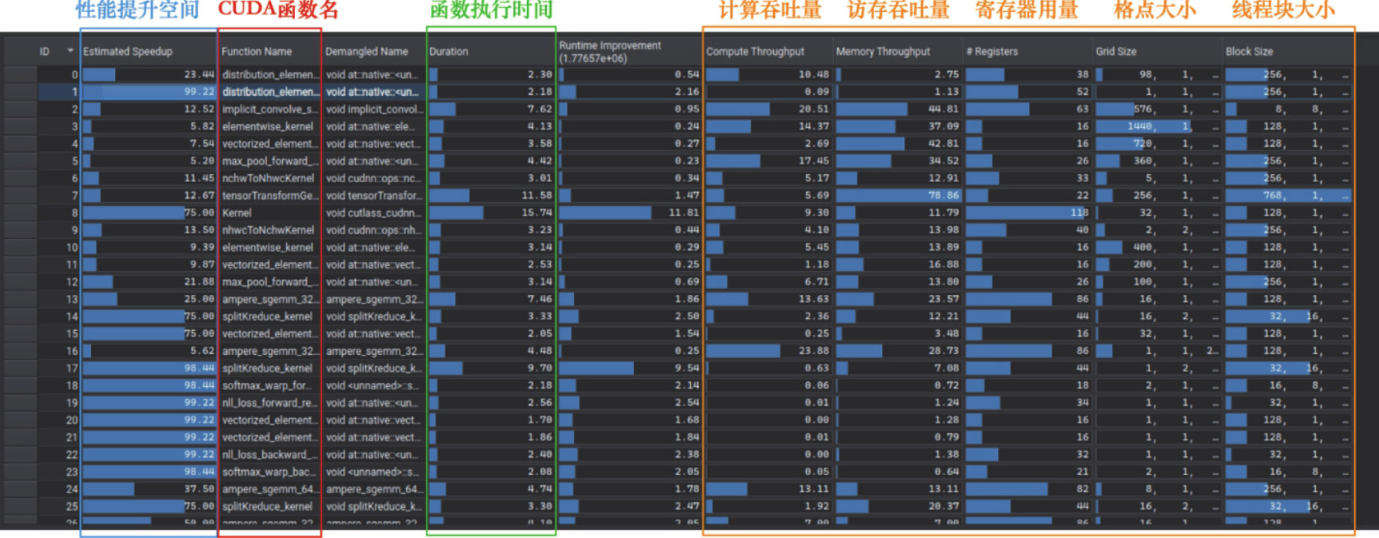
让我们双击其中任意一个函数名称,进入细节(details)视图,这时我们会看到大量硬件相关的性能信息:
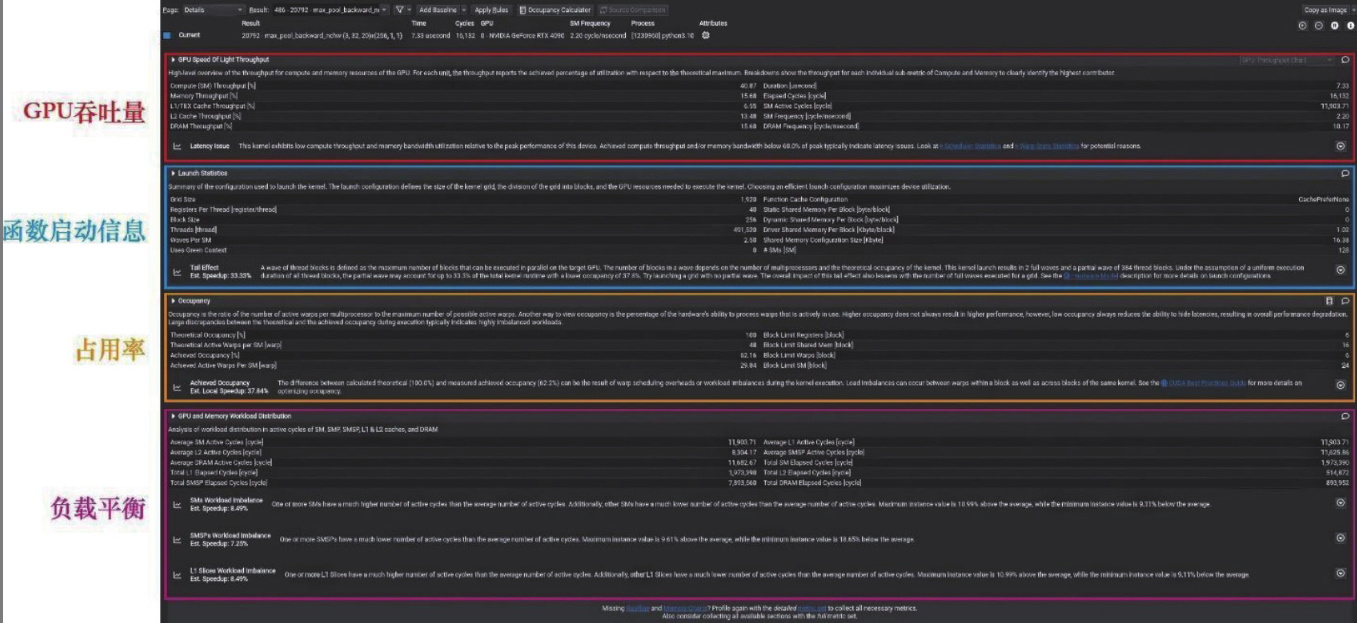 首先是最上方的区域,这个区域反映的是执行过程中,GPU不同硬件单元的吞吐量。一般来说吞吐量最高的硬件单元就是该CUDA函数的性能瓶颈,以此可以判断CUDA函数属于计算密集型还是访存密集型。
首先是最上方的区域,这个区域反映的是执行过程中,GPU不同硬件单元的吞吐量。一般来说吞吐量最高的硬件单元就是该CUDA函数的性能瓶颈,以此可以判断CUDA函数属于计算密集型还是访存密集型。
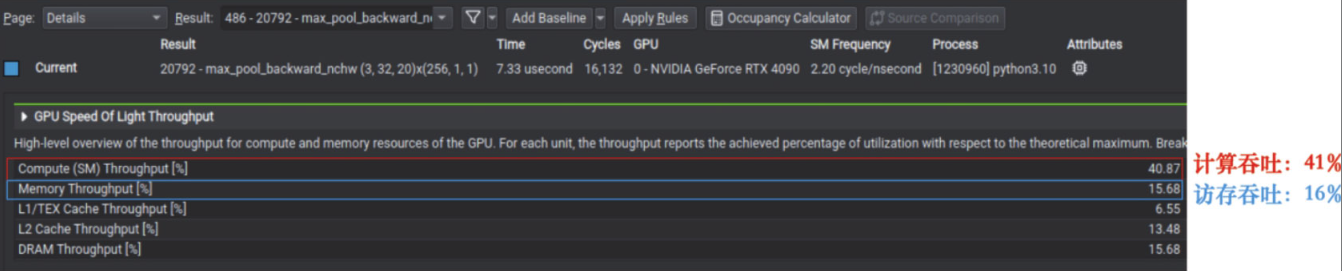
具体来说,如果我们观察一个池化函数(pooling)的硬件使用率情况,如图所示,就会发现其计算吞吐量(Compute
Throughput)要远高于访存吞吐量(Memory
Throughput),说明当前这个池化函数是计算密集型的,但这有些反直觉。从计算特点来看,池化函数每次需要读取一块很大的数据区域,但是对这些数据的计算却比较简单,因此理应是访存密集型为主。从这个例子我们就可以看出Nsight
Compute带来的价值,它能够定位表现异常的算子、提供性能分析数据,并最终帮助我们完成算子优化:
接下来让我们将注意力移动到CUDA函数启动信息(Launch
Statistics)部分,这里展示的是每个CUDA函数在执行时的相关配置,比如说格点数量(Grid
Size)、线程块大小(Block
Size)、总线程数(Threads)等,这部分信息可以用来反映算子是否充分利用了GPU的资源:
 比如说图中算子的问题就在于配置的格点数量太少,没能充分使用GPU的流式多处理器(SM)。在图中蓝色框的位置处,还可以看到Nsight
Compute对此给出的提示,GPU支持128个并行的多处理器核心,但是这个CUDA函数只调用了40个,所以还有性能优化的空间。
比如说图中算子的问题就在于配置的格点数量太少,没能充分使用GPU的流式多处理器(SM)。在图中蓝色框的位置处,还可以看到Nsight
Compute对此给出的提示,GPU支持128个并行的多处理器核心,但是这个CUDA函数只调用了40个,所以还有性能优化的空间。
最后让我们观察占用率区域(Warp
Occupancy)。这部分信息反映了多线程在GPU上执行时,实际的并行程度。比如图中存在的问题是线程使用率不高,理论上可以同时并行48个线程组,实际上只有10个,仅达到了理论并行度的20%。从提示中可以看出,导致该现象的原因可能有两类。一种可能是每个线程中的计算任务过于简单,导致线程束的创建和调度开销要显著大于线程计算任务的开销,所以优化方向是让多个简单线程合并成一个计算量较大的线程。另一种可能性则是线程束的负载不均衡,比如CUDA代码中存在大量线程发散,导致不同分支的线程束无法同步执行——这就需要我们结合CUDA代码进行具体分析。

CPU性能分析工具
Py-Spy
Py-Spy是非侵入式的,意味着我们不需要修改任何一行Python代码,即可通过如下命令开启CPU分析:
py-spy record -o profile.svg python train.py
火焰图的每个竖条都表示一组调用栈,上面是栈底、下面是栈顶。一般来说Python函数名称会出现在靠近栈底的位置,而栈顶一般是一些底层的C++函数名称。当把鼠标移动到火焰图的某个函数上时,还会在后面显示该函数对应的代码位置以及采样数。采样数本质上和运行时间只差一个系数,这个系数就是采样间隔,默认情况下采样间隔是100 samples/s,因此采样数除以100就是函数实际运行的时间了。从图中可以快速找到numpy_heavy_computation对应的运行时间,这就是我们代码中NumPy计算对应的CPU调用。Py-Spy是对所有Python原生程序以及第三方库都适用的分析工具,非常适合用来专门对CPU任务进行分析。
strace
有时候在Py-Spy的火焰图中可以观测到一些函数明显占用了过长的时间,却不知道系统在干什么。这时,使用strace来查看程序与操作系统之间的实时交互,如文件操作、内存管理和网络通信等,通常能带来极大的帮助。strace是一个在Linux环境中极其实用的诊断和调试工具,它能够追踪并记录程序执行的所有系统调用,包括每个调用的函数名、传递的参数以及返回值。 strace的使用方法也很直接,既可以通过strace启动一个程序,也可以追踪一个正在运行的进程,代码如下所示。
# 通过strace运行一个程序
strace python train.py
# 追踪一个正在运行的进程
strace -p <pid>在使用strace追踪程序时,有一些常见的与性能相关的系统调用值得我们特殊关注: - 文件相关的系统调用,如open/close/read/write/lseek等 - 网络通信相关的系统调用,如socket/bind/listen/send/recv等 - 进程控制相关的系统调用,如fork/execve/wait等 - 内存管理相关的系统调用,如mmap/munmap/brk等
strace可以有效地帮助开发者了解程序在运行时的行为,特别是用于诊断程序的性能异常等。
小结
本章主要介绍如何定位性能瓶颈,具体包括三个步骤: - 配置一个稳定且可复现的软硬件环境。 - 通过计时或观察PyTorch性能图谱来发现性能问题。 - 使用底层硬件和系统相关的性能分析工具来剖析问题的根本原因。一旦找到了性能问题并理解其原因,就可以参考第6章中的性能优化方法进行优化。此外,还可以参考第9章中的高级优化方法进行进一步优化。