背景
多模态理解与生成是一个新兴的研究领域,许多研究项目已经展示了在优化生成和理解基准测试中联合优化的潜力。然而,现有的模型大多只在标准的图像生成和理解任务中的图像-文本配对数据上进行训练,导致学术模型与专有系统(如GPT-4o和Gemini 2.0)之间存在显著差距。论文认为,缩小这一差距的关键在于使用精心设计的多模态交错数据进行扩展。
模型
设计
结构
广义因果注意力
Dense/MoE/MoT
数据
Text
Vision-Text Paired Data
VLM
T2I
Vision-Text Interleaved Data
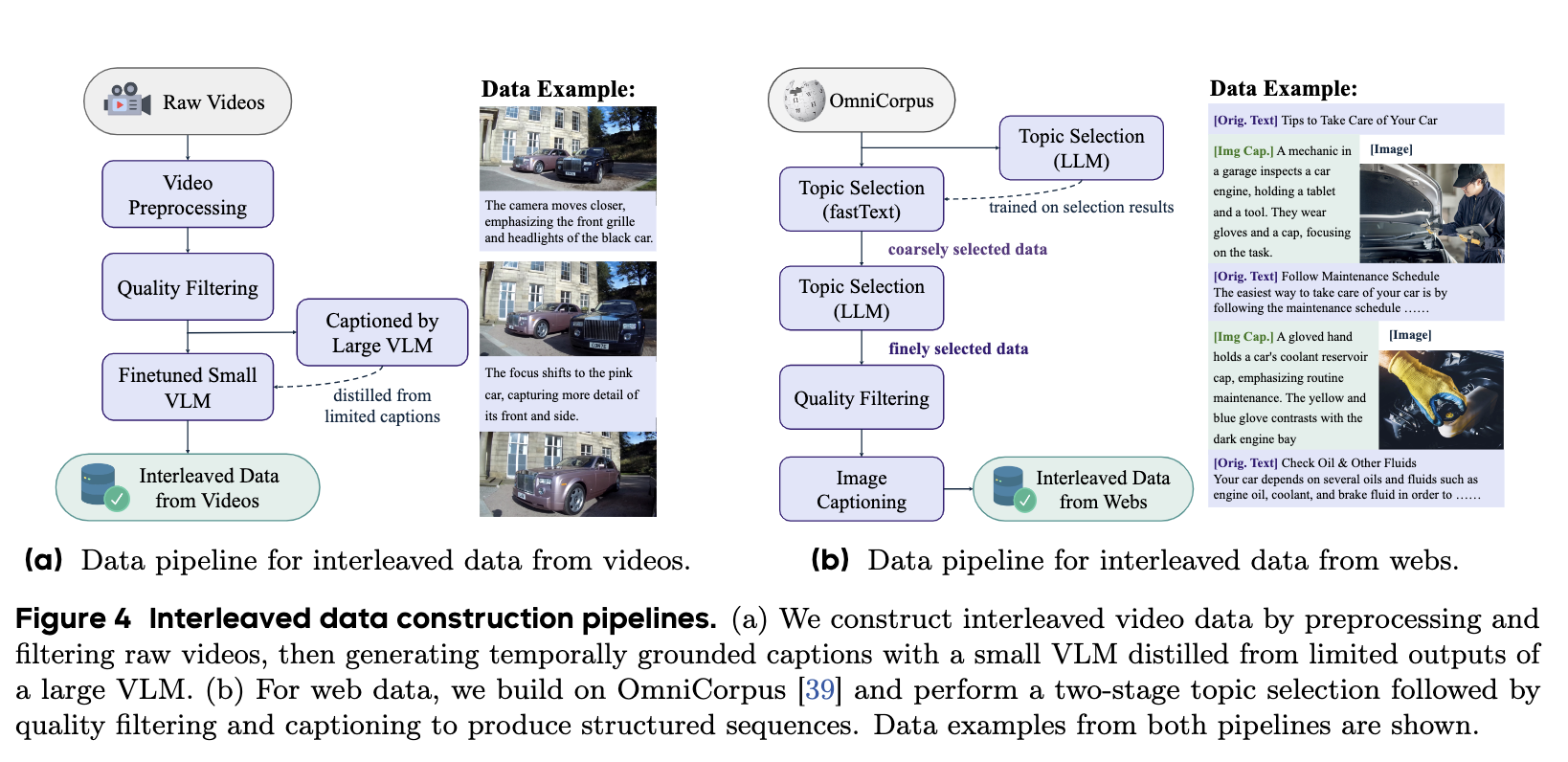
利用VLM交错数据集改善多模态理解。对于视觉生成,引入了一个统一的协议,通过结合不同的来源来构建视觉文本交错数据,以支持更丰富的多模态交互,详情如下。 ### 数据来源 #### 视频 视频数据通过直接从现实世界中捕捉时间和空间动态来提供丰富的世界知识,这是最大、最自然的模拟器。它保留了精细的视觉细节,保持了跨帧的身份一致性,并模拟了复杂的运动,这使得它对图像编辑、导航和3D操作等任务特别有效。我们使用公开可用的在线视频资源以及两个开源数据集构建我们的视频数据集:Koala36M,它提供大规模的教学和丰富的交互内容,以及MVImgNet2.0,它包含从不同相机视角捕获的对象,以支持多视图空间理解。
Web
网络数据捕获复杂的现实世界多模态结构,并提供涵盖广泛领域的多样化知识。它包括自然交错的资源,如插图百科全书文章、分步视觉教程和其他基础丰富的文档。这种交错格式为训练模型提供了丰富的监督,以执行多模态推理。我们建立在OmniCorpus之上,这是一个从Common Crawl预处理的大型数据集,它提供了大量带有交错文本和图像的网络文档集合。此外,我们还包括开源图像编辑数据集作为结构化交错数据,这些数据教授精细的编辑行为,并增强了模型对精确多模态推理和逐步生成的能力。
数据过滤
视频
视频数据的数据过滤。我们遵循T2V视频处理管道协议,通过时间分割、空间裁剪和质量过滤将视频预处理成高质量的训练剪辑。视频首先使用轻量级镜头检测分段为短而连贯的片段,相关片段可选择根据视觉相似性合并。然后,我们使用裁剪检测和帧级边界框聚合来删除徽标或文本等黑色边框和叠加层。为了确保质量,我们根据长度、分辨率、清晰度和运动稳定性过滤剪辑,并使用基于CLIP的相似性进行重复。这个过程产生了一个干净多样的视频数据集,适合多模态训练。
Web
网络数据的数据过滤。为了从大型语料库中策划高质量的交错数据,我们设计了一个两阶段的过滤管道,针对文档,如教程、百科全书条目和设计内容,其中文本和图像表现出强烈的语义对齐。受DeepSeekMath
[64]的启发,我们首先应用了轻量级主题选择过程:LLM被提示对文档的一小部分进行分类,生成的标签用于训练fastText
[34]分类器,以实现高效的大规模推理。然后,所选数据再次通过LLM分类器进行精细过滤。我们采用了Qwen2.5模型的14B变体[92],因为它在性能和效率方面取得了平衡。为了进一步提高数据质量,我们应用了一套基于规则的过滤器,针对图像清晰度、相关性和文档结构,如表2所述。

数据构建
视频交错
为了从视频中构建图像文本交错序列,我们生成连续帧之间的视觉变化的文本描述——捕捉对象运动、动作过渡和场景移位。这些帧间字幕作为学习视觉动力学的时间监督。虽然大型VLM可以产生高质量的更改描述,但其推理成本限制了可扩展性。相反,我们提炼了一个基于Qwen2.5-VL-7B [4]的轻量级caption模型,在一小组高质量的帧间示例上进行微调。为了减少幻觉,我们将标题长度限制在30个代币。对于每个视频剪辑,我们平均抽取四个帧,并为每个帧对生成字幕,从而产生4500万个时间接地交错序列。如图4a所示。
Web交错
来自网络的交错数据。为了从网络文档中构建高质量的交错序列,我们的目标是减少图像、其附带文本和周围视觉背景之间对齐不力造成的图像生成难度。为了为每张图片提供更本地化和相关的线索,我们采用了标题优先策略:对于每张图片,我们使用Qwen2.5-VL-7B
[4]生成简明的描述,并将其直接插入到图像之前作为概念脚手架。
这使得模型能够在生成目标图像之前形成目标图像的概念草案,该图像以前面的上下文和插入的标题为基础。通过生成标题来指导模型在图像中应该期待什么,这种方法缓解了松散相关或模棱两可的输入造成的问题。此外,我们使用LLM总结器重写超过300个令牌的图像间文本段,以提高上下文密度。这些步骤产生了一个由2000万个交错网络文档组成的更干净、更结构化的数据集。数据管道和示例如图4b所示。
Reasoning-Augmented Data
受O1[33]和DeepSeek-R1[26]等近期模型的启发,我们利用长上下文思想链数据进行多模态理解。此外,我们假设在图像生成之前引入基于语言的推理步骤有助于明确视觉目标并改善规划。为了探索这一点,我们构建了50万个推理增强示例,根据输入和输出之间的结构关系涵盖了四个类别:文本到图像生成、自由形式图像操作和抽象编辑。
文本到图像生成。我们首先手动制作一组简短且模棱两可的T2I查询,每个查询都配对了简单的生成指导。使用上下文学习,我们提示Qwen2.5-72B [ 92]生成额外的查询-指导对和相应的详细提示,然后将其传递给FLUX.1-dev [35]以生成目标图像。这个过程产生了查询、推理跟踪(指导+详细提示)和图像的训练三胞胎,使模型能够在基于语言的推理中生成图像。
自由形式图像操作。我们通过提示带有源图像、目标图像、用户查询和DeepSeek-R1的推理跟踪示例的VLM [ 26]来生成推理增强示例。R1示例是通过对源和目标标题、用户查询和推理指令进行条件生成的。表9和表10展示了用于推理跟踪生成的VLM提示。我们主要从两个来源抽取源和目标图像对:开源编辑数据集,如OmniEdit [80]和交错视频数据,它们提供了一组丰富的自然发生的编辑场景,其特点是实质性运动、观点变化和人类互动,同时保持时空一致性。
概念编辑。概念编辑针对图像操作需要高级概念推理而不是简单的本地像素修改,例如将对象转换为设计草图。对于这些任务,我们使用网络交错数据集,从每个序列中抽样候选图像对,并应用三阶段VLM管道来构建高质量的QA示例。首先,给定一系列图像,我们提示VLM识别一个合理的输入-输出对。接下来,我们提示模型根据所选对生成相应的文本问题。最后,我们使用VLM来评估问题的质量及其与输入和输出图像的一致性,过滤掉低质量的例子。然后将接受的示例传递给VLM,并提示来自DeepSeek-R1 [26]的推理跟踪示例,以对预期转换进行有根据的解释,如表11所示。这种设置有助于模型从多样化的文本指令中学习解释复杂的视觉目标。
训练
如表3所示,我们使用上述混合数据进行多阶段训练: 对齐阶段初始化VLM connector,预训练阶段进行large-scale多模态预训练,继续训练阶段提高视觉输入分辨率和交错数据采样比,监督微调阶段进行多模态生成和理解的微调。
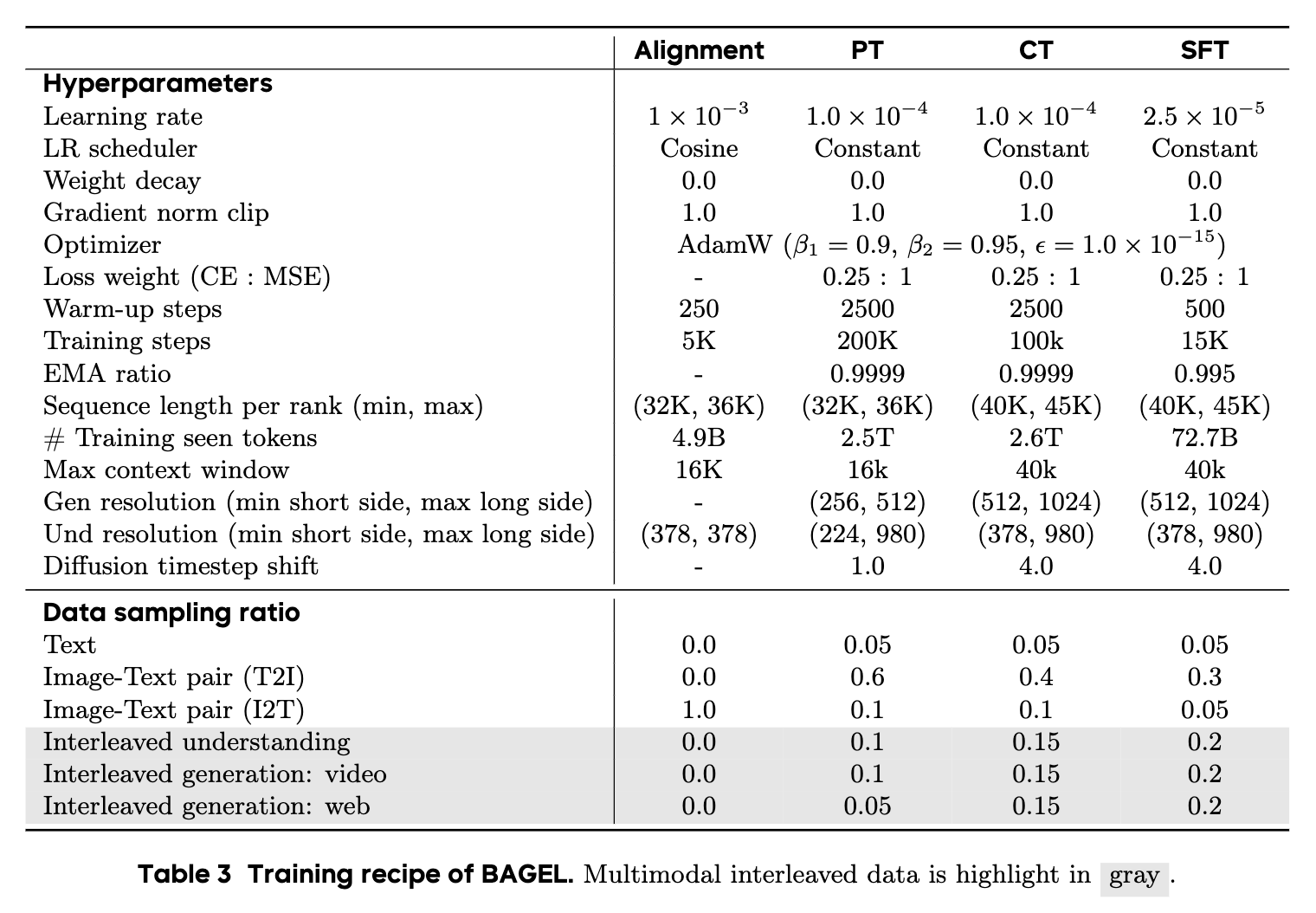
Alignment. 只用I2T数据训练SigLip2 Vit和Qwen2.5 LLM之间MLP连接器。 图像大小固定在378x378,以匹配SigLIP2的预训练输入大小。
Pre-training (PT).
在这个阶段,我们将QK-Norm添加到LLM中,除VAE之外的所有模型参数都可以训练。 训练语料库由2.5T tokens组成,包括文本、图像-文本对、多模态对话、网络交错和视频交错数据。采用原生分辨率策略来理解和生成多模态,但是限制每个图像的最大长边和最小短边。
- Continued Training (CT)
与PT相比,在CT阶段提高了视觉输入分辨率, 增加了交错数据的采样比, CT阶段消耗了大约2.6T tokens。
- Supervised Fine - tuning (SFT).
在SFT阶段,进一步提高交错数据集比例,对于多模态生成,我们从图文对数据集和交错-生成数据集中构建一个高质量的子集。 为了多模态理解,我们用LLaVA-OV和Mammoth-VL指令调整数据中过滤的一个子集。 sft阶段的数据量为72.7B tokens。
其他超参: - AdamW优化器使用β1 = 0.9,β2 = 0.95,设置ε = 1.0 × 10−15来抑制损失峰值。 - 在提高生成分辨率时,我们还将扩散时间步从1.0增加到4.0,以确保适当的噪声分布。 - PT、CT和SFT阶段采用恒定的学习率,这样我们就可以在不重新开始训练过程的情况下轻松扩展训练数据。 - 为了确保不同rank之间的负载平衡,我们将每个rank的序列打包到一个狭窄的长度范围内(对齐和PT为32K至36K代币,CT和SFT为40K至45K代币)。 - 与独立VLM或T2I模型的预训练不同,统一的多模态预训练需要仔细调整两个关键超参数——数据采样比和学习率——以平衡理解和生成任务的信号:
Data Sampling Ratio
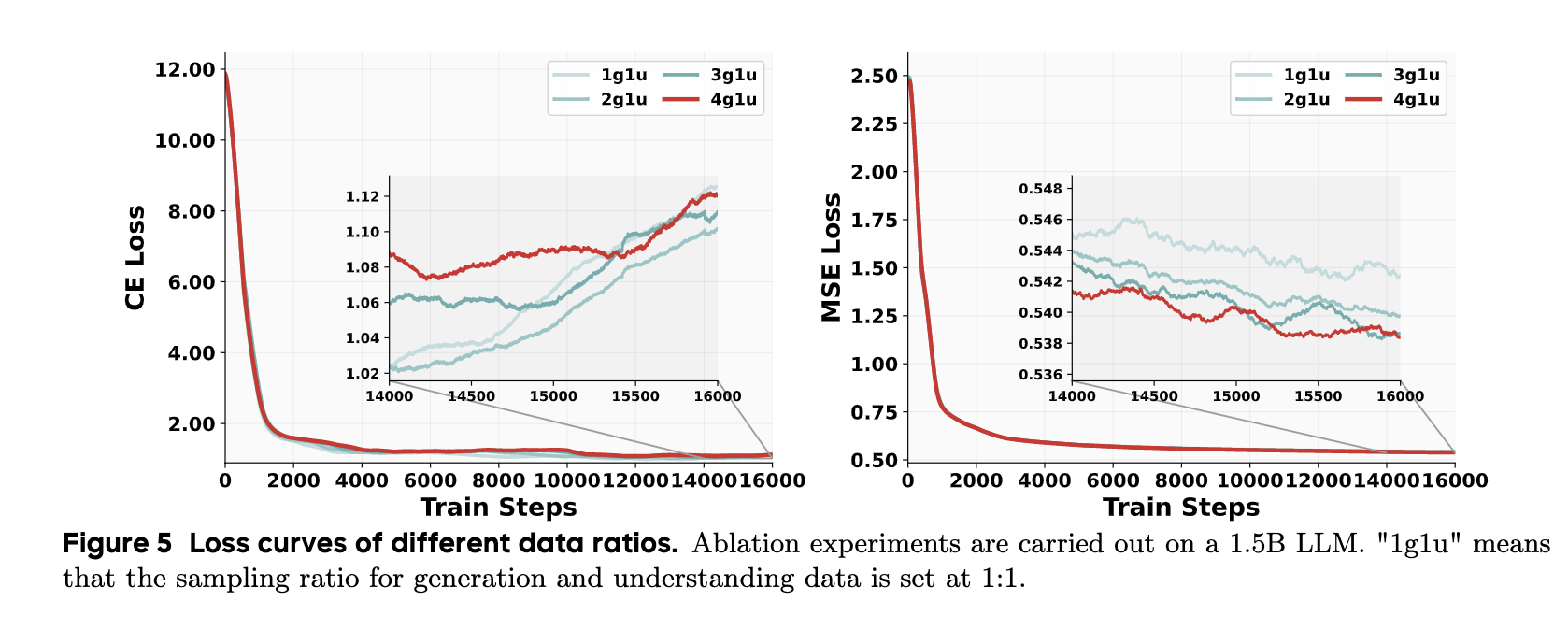
基于对1.5B Qwen2.5 LLM
进行了一系列对照研究,如图5所示,将生成数据的采样率从50%(“1g1u”)提高到80%(“4g1u”)可以稳步降低MSE损失,大概有0.4%的绝对减少(对于生成模型来说,已经很大的提升)。相比之下,交叉熵(CE)损失在抽样比中没有表现出一致的模式,观察到的最大差距,即“4g1u”和“2g1u”之间的步骤14,000的0.07,对下游基准的影响可以忽略不计。
这些发现表明,生成样本应该比理解样本更频繁地抽样——所以表3中对于生成数据的比例设置的较高。
学习率
如图6所示,两种损失的行为相反:更大的学习率使MSE损失收敛得更快,而较小的学习率有利于CE损失。为了调和这种权衡,我们为表3中列出的两个ce_loss
和 mse_loss目标分配了单独的权重。 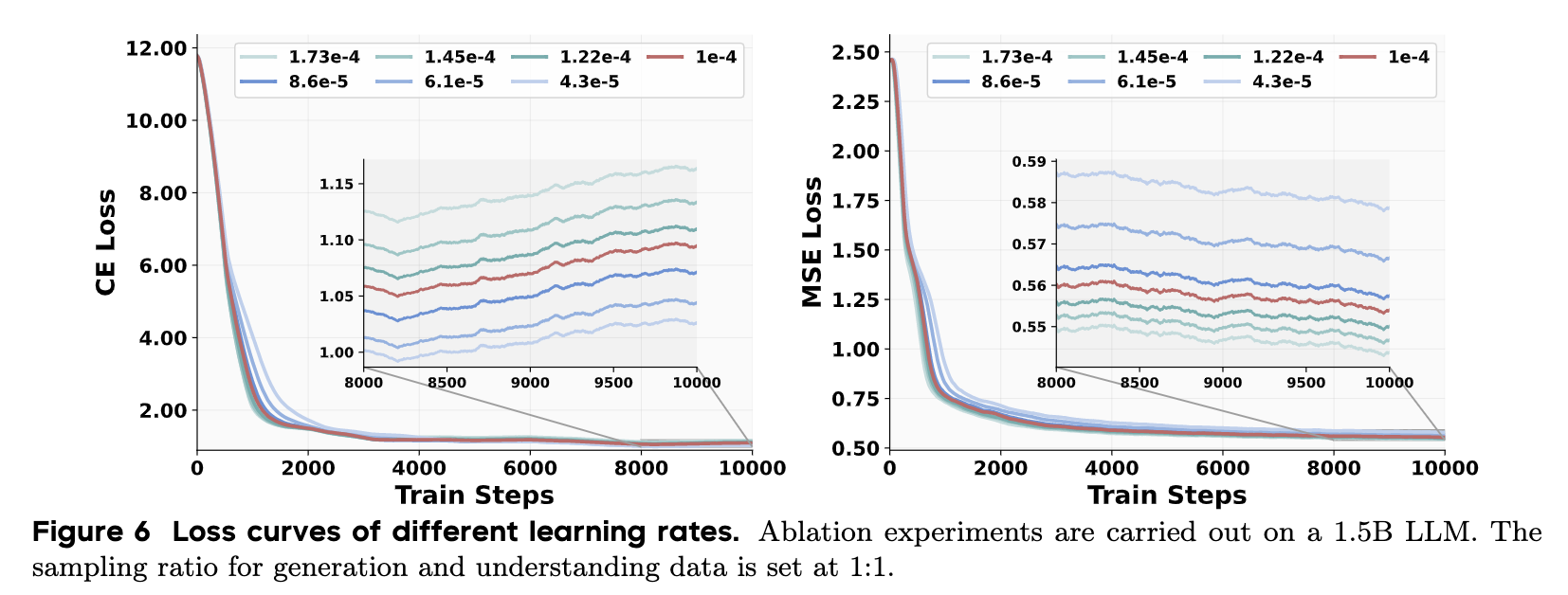
评估
为了全面评估统一模型,针对明确的能力,如多模态理解、T2I生成和经典图像编辑的验证使用了已有的基准。 然而,对于需要强大的多模式推理和复杂任务构成的能力,仍然缺乏有效的评估策略。 因此论文首先说明了评估过程中使用的可用基准, 然后介绍了用于自由形式图像操作(包括概念编辑)的新评估套件IntelligentBench,旨在揭示模型在多模态推理和复杂组成任务方面的熟练程度。
多模态理解
使用泛使用的基准——MME、MMBench(1.0-EN)、MMVet、MMMU、MathVista和MMVP。
T2I生成
按照janus-pro等paper[11,57],报告流行的GenEval [25]基准的结果。 我们还采用了最近提出的WISE基准[53],该基准对文本到图像生成中的复杂语义理解和世界知识整合进行了全面评估。 此外,我们将与最先进的模型进行定性比较,作为这些自动评估指标的补充。
图像编辑
采用GEdit-Bench作为主要评估套件,因为它具有现实世界的相关性和多样化的编辑任务。 GEdit-Bench由从网络上抓取的真实用户请求构建,密切反映了实际的编辑需求。 通过GPT-4.1自动进行评分,我们还用定性示例来补充这些分数,以提供更细微的评估。
IntelligentBench
论文提出IntelligentBench作为评估自由形式图像操作能力的代理任务,这需要复杂的多模态推理和任务组成。 IntelligentBench的初始版本包括350个示例,每个示例包括一个问题图像、问题文本和参考答案图像。
使用GPT-4o(版本:gpt-4o-2024-11-20)进行评估,该模型审查了一个完整的四组——问题图像、问题文本、参考答案图像和模型生成的图像。评估标准包括请求履行、视觉一致性和基于知识的创造力,反映了基准对任务正确性和推理深度的关注。每个答案都以0到2的等级进行评分。
模型的最终分数是通过将所有个人分数相加,并将总数归一化为100分制来计算的。附录表12提供了详细的评估提示。在IntelligentBench的帮助下,我们可以评估模型在推理方面的表现如何,并整合世界知识进行图像编辑。图12显示了IntelligentBench上的一些展示和定性结果。


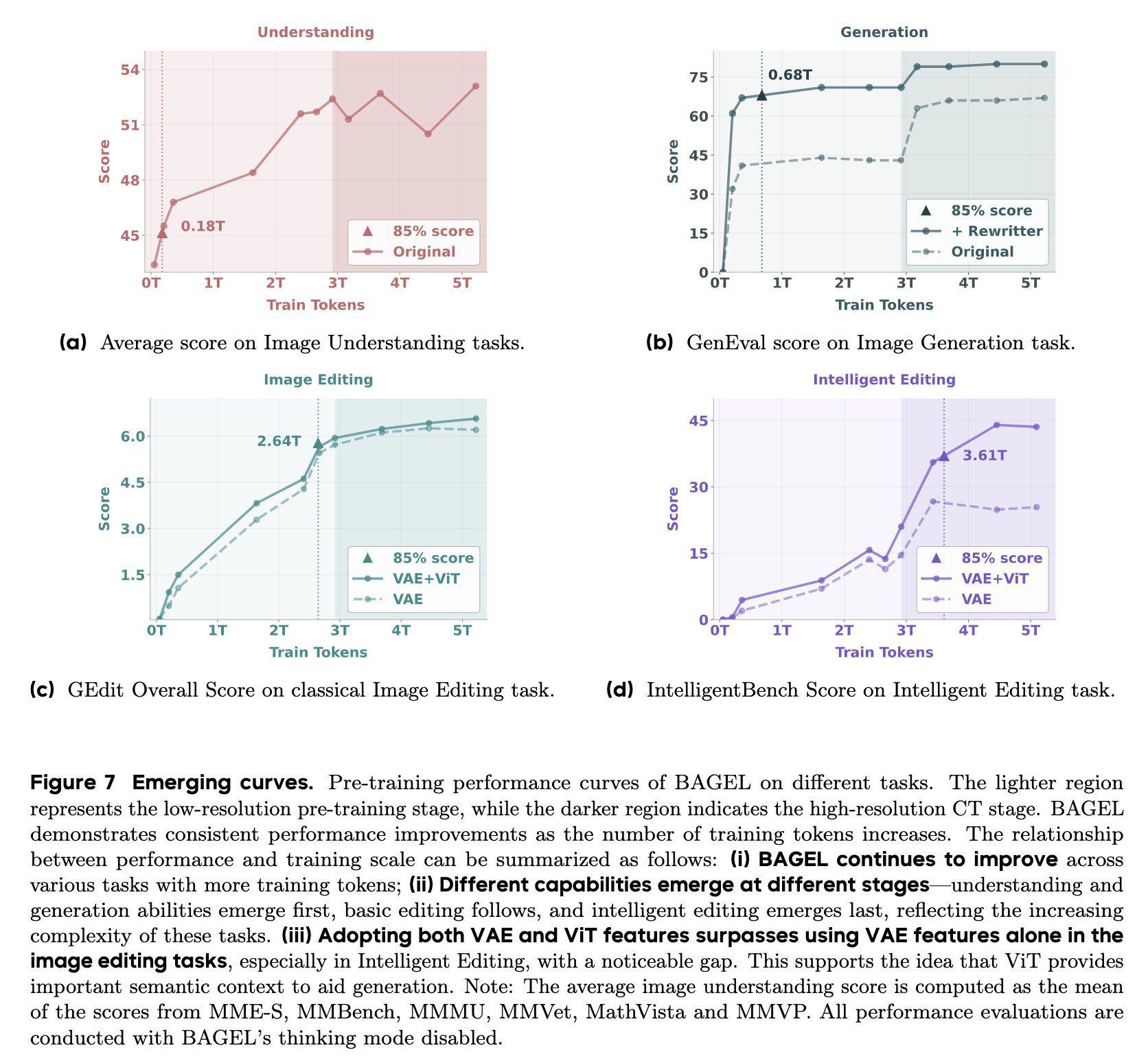
Emerging Properties 涌现能力
在大型视觉或语言模型的背景下,对涌现能力进行了广泛的研究[7, 81]。在这项工作中,位于统一多模态基础模型的范围内,我们对涌现能力采用了更集中的定义: >y涌现力不存在于早期的训练阶段,而是存在于后期的预训练阶段. 这种通常被称为相位转换的定性转变,表示模型行为的突然和戏剧性变化,无法通过从训练损失曲线中推断来预测[81]。有趣的是,我们在统一的多模态缩放中观察到类似的现象,其中损失曲线并没有明确表示新能力的出现。因此,我们通过评估历史检查点上一系列任务的性能来调查模型能力的出现。具体来说,我们报告了标准VLM基准的平均性能,作为多模态理解的代理,GenEval分数的生成能力,以及GEdit分数和IntelligentBench分数,分别评估模型在天真和复杂的多模态推理中的能力。
有趣的是,不同的任务表现出不同的学习动态和饱和行为。如图7所示,如果我们选择达到峰值性能85%所需的可见代币数量作为指标,我们发现传统理解和生成基准相对较早饱和:分别约为0.18T和0.68T代币。相比之下,需要理解和生成能力的编辑任务表现出较慢的收敛,仅在2.64T令牌后才能达到85%的性能。最值得注意的是,智能编辑任务旨在消除幼稚的编辑案例并强调复杂的多模态推理,需要3.61T令牌才能达到85%,展示了类似于[81]中描述的紧急行为的模式。在此设置中,该模型最初显示性能低,在3T看到令牌后逐渐显著改善。虽然传统的编辑任务在很大程度上不受3T令牌的分辨率增加的影响,但智能编辑性能持续大幅提高——从15到45——在后期训练阶段增加了三倍,并强调了其对统一多模态推理的依赖。我们进一步发现,理解能力,特别是视觉输入,在多模态推理中起着至关重要的作用:删除ViT令牌对GEdit-Bench的影响很小,但导致智能编辑下降16%,凸显了视觉语义推理在复杂编辑任务中的重要性。
虽然评估指标可能不会线性地捕捉模型的真正能力——可能会导致虚假的出现迹象,尽管不太可能——但我们通过检查不同培训检查点的生成输出来进一步检查定性的新兴行为。如图8所示,我们观察到与性能曲线一致的趋势:在1.5T看到令牌之前,生成质量已经很强大,在以更高的分辨率训练3.0T看到令牌后,质量略有改善。对于文本渲染,生成“hello”和“BAGEL”的正确拼写的能力稍后会出现——大约1.5T到4.5T代币。在图9中智能编辑任务的定性可视化中也观察到了新出现的行为。与图8所示的传统编辑不同,后者只涉及对输入图像进行部分修改,智能编辑通常需要基于多模态推理生成全新的概念。在3.5T令牌之前,该模型倾向于以最小的更改再现输入图像——当任务没有完全理解时,这是一种回退策略。然而,在看到3.5T令牌后,该模型开始展示明确的推理,产生连贯和语义上适当的编辑,与图7中看到的紧急行为保持一致。



